【WWW2022】图上的聚类感知的监督对比学习

论文标题:ClusterSCL: Cluster-Aware Supervised Contrastive Learning on Graphs
第一作者:王艳玲
通信作者:张静
录用会议:WWW 2022
研究动机:
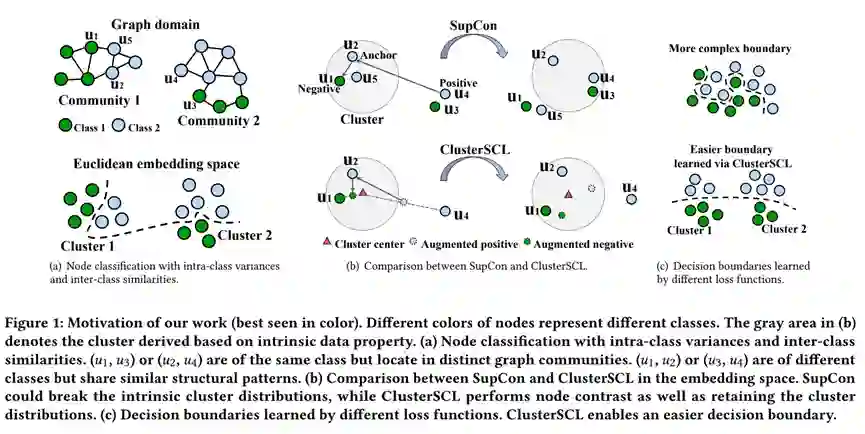
本文关注到节点分类任务中广泛存在的类内方差和类间相似问题,并提出一种监督学习方法,更好地在该类型数据上训练节点分类模型,其思想可被应用到其他领域的分类问题中。
现阶段,主流的节点分类模型主要包含两个组件:编码器(encoder)和分类器(classifier)。编码器用于编码节点的特征表示,可被实例化成各种图神经网络结构,例如GCN、GAT。分类器基于节点特征表示计算节点的类别分布,常被实例化成linear layer或MLP。目前,大多数工作直接采用Cross Entropy损失函数(CE),端到端地同时优化编码器和分类器。受启发于快速发展的对比学习技术,本文拓展CV领域的Supervised Contrastive Learning损失函数(SupCon)来训练节点分类模型。SupCon的核心思想是:通过对比损失拉近同类别样本,推远不同类别的样本。我们先采用SupCon训练编码器,在优化后的编码器上,再使用CE进一步端到端地优化编码器和分类器,取得了比直接使用CE更好的分类效果。尽管如此,SupCon还有进一步改进的空间,因为它没有讨论现实数据中的类内方差和类间相似问题。因此,SupCon在拉近同类样本时,可能会间接拉近不同类别的样本,在推远不同类别样本时,可能会间接推远同类别样本。当数据存在较大的类内方差和类间相似时,SupCon可能会导致一个较复杂的类别分界面,从而加大学习分类器的难度。
解决方案:
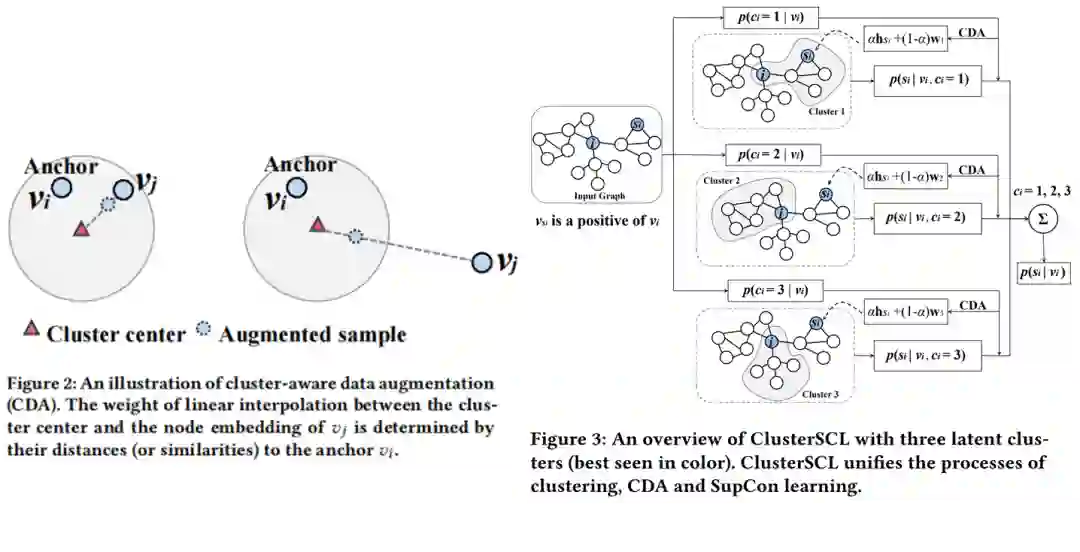
为解决上述问题,我们将数据中存在的类内方差和类间相似视为数据固有性质的一种体现,在做监督对比减小同类样本间距离的同时,希望能保持数据固有的性质。我们通过聚类建模数据。聚类依据样本特征无关于类别标签,因此可以反应数据的固有性质。
为了在做监督对比学习时,维持节点的聚类分布,一种直接的想法是:第一步做硬聚类,然后在各个聚类中做监督对比学习。基于此想法,本文设计了Group Sensitive SupCon损失函数(GS-SupCon)。具体地,我们假设互联程度高的节点拥有相似的特征,使用METIS根据节点间的链接关系进行图分割使子图间的互联程度尽可能小,然后在每个子图中进行监督对比学习,优化GNN编码器。GS-SupCon可以取得比SupCon更优的效果,说明了维护数据固有性质在对比学习过程中的重要性。然而,GS-SupCon忽略了跨cluster的正样本对,例如图1中的(u1, u3)和(u2, u4)。
本文认为所有正样本对都是有价值的,但不直接拉近正样本对或推远负样本对,而是设计了cluster-aware data augmentation(CDA)作用于每个anchor的真实正负样本,使生成的虚拟正负样本既包含原正负样本的信息,又更加靠近anchor所在的聚类。通过CDA,监督对比学习在一个更加集中的空间中进行,间接削弱了anchor和其原始正负样本之间的拉推力度,从而避免过度改变图中节点的聚类分布情况。进一步,我们设计了Cluster-Aware Supervised Contrastive Learning(ClusterSCL),通过概率模型统一了软聚类,CDA和监督对比,使三者能互相影响促进。CLusterSCL的具体优化方式请参考原文。
主要实验结果:
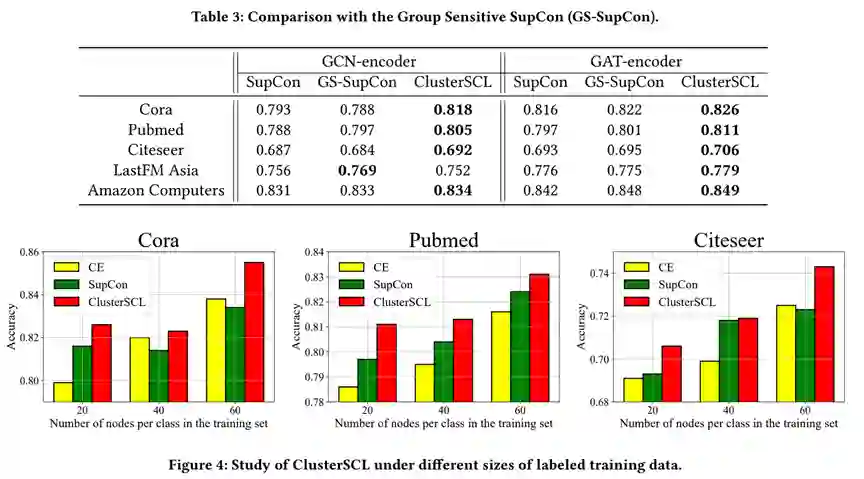
1. 相比CE和SupCon,ClusterSCL取得了更优的节点分类效果。在不同size的标注训练集上,ClusterSCL均能取得更优的表现。随着训练数据的增多,类内方差和类间相似带来的负面影响可能会被放大,使得CE的效果可能超过SupCon的效果。
2. GS-SupCon可以取得与SupCon相当或比SupCon更优的表现,但在不同数据集和不同编码器下的表现不太稳定。ClusterSCL则能更稳定地优于SupCon和GS-SupCon。
更多实验结果与实验分析请参考原文。
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“CSCL” 就可以获取《【WWW2022】图上的聚类感知的监督对比学习练》专知下载链接

请扫码加入专知人工智能群(长按二维码),或者加专知小助手微信(zhuanzhi02),加入专知主题群(请备注主题类型:AI、NLP、CV、 KG、论文等)交流~






