一字千金话迭代

在我国灿若星河的诗词中,有恢宏壮阔的山河,也有润物无声的春雨,有春风得意马蹄疾,也有停杯投箸不能食.. 它们或哀婉或振奋,宛若浑然天成。当拉近时间的距离,进一步探究创作的过程,许多诗词的创作并非一蹴而就,而是经过了千锤百炼,反复迭代优化润色,才能在时间的长河中熠熠生辉。所以有 “两句三年得,一吟双泪流” 的喜极而泣,也有 “吟安一个字,拈断数茎须” 的锲而不舍;当然, 流传最广的当属唐朝著名诗人贾岛推敲的故事了。
在人工智能创作诗词大行其道的今天,机器人能否学会推敲这一高级技能呢?本文将为大家介绍平安科技技术研究院(中国)在人工智能会议AAAI2020 上的一篇工作《An Iterative Polishing Framework based on Quality Aware Masked Language Model for Chinese Poetry Generation》,阐述机器人推敲迭代需要攻克的难点,并深度揭秘我们的解决方案。
AAAI(The Association for the Advance of Artificial Intelligence)是1979年成立的世界范围的人工智能组织。这一协会在早期由计算机科学和人工智能的创始人 Allen Newell, Marvin Minsky 和John McCarthy 等人首创的,也是人工智能会议AAAI的组织者。AAAI-20是第三十四届AAAI人工智能大会,被中国计算机协会(CCF)评定为A类会议。本次会议投稿量超过8800篇,论文录取率只有20%左右。
/// 引言-独上西楼,月如钩 ///

图片来源于网络
现有比较知名的人工智能创作诗词系统, 比如 清华的 “九歌”,华为的 “乐府” 都取得了较为惊艳的效果,引发了广泛的关注。他们所创作生成的诗词成形后就不再进行修改润色。这样有些生成的诗词好,有些生成的差也在所难免,而诗人在写完诗词初稿后是会反复修改润色的。因此,我们能否让人工智能系统 也进行诗词的修改迭代润色呢?
答案是 当然可以!
据笔者调研,有一些工作在这方面进行了有益的探索,比如 严睿老师的 i,poet (Yan 2016) 通过不断整合写作意图和已经生成的诗句来重新 生成新的诗句,这样期望新生成的诗句更能表现写作意图;还比如 微软亚研院这边用于机器翻译的Deliberation Network (Xia et al. 2017)。分析这些工作发现,他们都有推敲的雏形,但与人类的推敲过程还有一些差距。人类推敲的过程主要分为以下几个步骤:
1)判断该文本是否需要迭代,判断需要迭代替换哪些字词,
2)找到更合适的字词来替换上一步中被认为不合适的字词,
3)重复以上步骤,直到所有字词都认为合适为止。
要获得人类的推敲技能,人工智能系统必须具备两大能力:
1)鉴赏能力,即鉴别文本质量高低的能力
2)更强的遣词造句能力。
/// 方法-忽如一夜春风来///
受益于NLP技术的快速发展,我们基于强大的 BERT 模型,巧妙设计了能够感知文本质量的遮挡语言模型,提出了一种文本多轮迭代的框架,该框架 能够 深度模仿人类推敲时的三大步骤,并获得明显的质量改善。
首先,我们将鉴别文本质量好坏的能力 转换为一个分类任务来学习其鉴赏力。将 BERT 中由预测是否为下一句的二分类问题 转换为 预测文本中哪一个位置的字为质量较差字的多分类问题。 具体来说,我们仿照 BERT 构造MASK数据集的方式,随机替换 一部分字词,并记录被替换字词的位置 作为它真实的分类标签。我们假设 从古代诗歌数据库中获得的诗歌数据都是质量好的文本,而经过随机替换后的文本就是人为构造质量较差的文本。通过这种方式可以获得输入样本 和 分类标签,这个真实的分类标签表明 哪个或哪些位置的字词质量较差。如果我们没有对真实的诗歌文本进行任何操作,那么它的分类标签 人为设置为0,表明文本中所有字词的质量都较好。通过监督训练,模型能够学到文本中是否有质量较差的字,较差的字的位置是哪里。这样 模型就具有了一定的鉴赏能力,从而能够实现人类在进行推敲润色时非常关键的第一步。
其次,鉴赏出质量较差的字词之后,如何获得更强的遣词造句能力找到更合适的字词来替换当前较差的字词呢?要找到这个问题的答案,我们首先分析一下现有的绝大部分文本生成系统都是从单一方向逐字或逐词进行生成的,这种生成方式 使得预测生成的字词只考虑了单侧的信息而忽略了另一侧的信息,这样使得最终生成的字词很难完全匹配上下文语境。因此,我们利用遮挡的语言模型 整合双向信息来预测该位置的字或者词,从而获得更合适的候选字词。实验表明双向信息很大程度上能够获得更好的候选字词来适应上下文语境。
最后,我们提出的模型 既有了鉴赏能力,又有了更强的遣词造句能力,那么只需要重复去鉴赏已经生成的文本,替换掉被认定为质量较差的字词就能获得更好的 润色后的文本。由于模型具有鉴赏能力,模型能够自动判断经过多轮迭代后文本的质量是否变好,如果模型认定为文本质量全部较好(即分类标签预测为0时)迭代过程自动终止。模型能够自动收敛,在我们的测试文本中,大部分文本经过两到三轮迭代就会自动终止。
通过以上三步,我们提出的模型和迭代框架非常巧妙的模仿了人类的推敲过程,也确实能够起到推敲、润色的效果。模型示意图如图1所示:
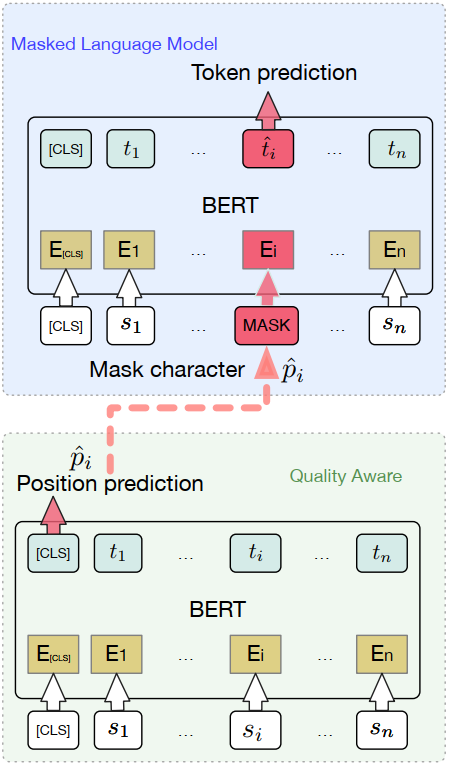
图1 质量感知遮挡语言模型框架
/// 效果-千树万树梨花开 ///
下图为利用我们提出的迭代框架润色诗歌草稿的效果,更多分析和实验结果请查看详细论文(https://arxiv.org/abs/1911.13182)

图2 左边为利用encoder-decoder框架生成的诗歌草稿,右边为利用我们提出的模型迭代框架进行修改润色后的结果。
/// 总结与思考-试玉要烧三日满 ///
本文简要介绍了我们组在诗歌生成领域所探索的一条 独特而有效的方法路径,实现 像诗人一样能够修改润色这一高级技能。通过详细定义润色迭代的三大步骤,赋予模型鉴赏和更强遣词造句的两大能力,最终实现了这一高级技能。主要贡献在于提出了一种通用的文本润色迭代框架,并转换为具体的任务进行实现。
目前,在NLP领域算法或者评价指标很难像人一样去感知、鉴别文本的质量,而本文所赋予模型的鉴赏能力能够有效的鉴别文本质量,为NLP领域提供了一种评价文本质量的思路,值得持续探索完善。
/// 团队介绍- 辨材须待七年期 ///
平安科技技术研究院(中国)由平安集团首席科学家肖京博士、人工智能中心首席NLP专家王少军博士领导,集结了一批国内外高端科技人才。神笔小安是由技术研究院(中国)感知计算技术研发团队研发的智能文本创作平台,其利用深度学习技术实现文本的艺术创作。神笔小安创作的所有作品,均是依赖于最前沿的自然语言生成模型,其能够基于用户的多样化输入,学习诗词歌中的语言风格,结合个性化的结构控制,最终创作出连贯的文本段落。目前,神笔小安赋能各类波段式营销场景,提供丰富的文本创作的有趣玩法,为保险、金融等各类业务场景进行导流。
参考文献
[1] Liming Deng, Jie Wang, Hangming Liang, Hui Chen, Zhiqiang Xie, Bojin Zhuang, Shaojun Wang, and Jing Xiao. 2019. An iterative polishing framework based on quality aware masked language model for chinese poetry generation. arXiv preprint arXiv:1911.13182.
[2] Devlin, J.; Chang, M.-W.; Lee, K.; and Toutanova, K. 2018. Bert: Pre-training of deep bidirectional transformers for language understanding.arXiv preprint arXiv:1810.04805.
[3] Yan, R. 2016. i, poet: Automatic poetry composition through recurrent neural networks with iterative polishing schema. In IJCAI, 2238–2244.
[4] Xia, Y.; Tian, F.; Wu, L.; Lin, J.; Qin, T.; Yu, N.; and Liu, T.-Y. 2017. Deliberation networks: Sequence generation beyond one-pass decoding. In Advances in Neural Information Processing Systems, 1784–1794
推荐阅读
百度aistudio事件抽取比赛总结——记一次使用MRC方式做事件抽取任务的尝试
模型压缩实践系列之——bert-of-theseus,一个非常亲民的bert压缩方法
征稿启示| 200元稿费+5000DBC(价值20个小时GPU算力)
斯坦福大学NLP组Python深度学习自然语言处理工具Stanza试用
太赞了!Springer面向公众开放电子书籍,附65本数学、编程、机器学习、深度学习、数据挖掘、数据科学等书籍链接及打包下载
数学之美中盛赞的 Michael Collins 教授,他的NLP课程要不要收藏?
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLPer(id:ainlper),备注工作/研究方向+加群目的。

阅读至此了,点个在看吧👇



