消息中间件这么多,到底应该如何选型?
消息队列已经逐渐成为企业应用系统内部通信的核心手段。它具有低耦合、可靠投递、广播、流量控制、最终一致性等一系列功能。

图片来自 Pexels

消息队列概述
通过提供消息传递和消息排队模型,它可以在分布式环境下提供应用解耦、弹性伸缩、冗余存储、流量削峰、异步通信、数据同步等等功能,其作为分布式系统架构中的一个重要组件,有着举足轻重的地位。
消息队列的特点
采用异步处理模式
消息发送者可以发送一个消息而无须等待响应。消息发送者将消息发送到一条虚拟的通道(主题或队列)上,消息接收者则订阅或是监听该通道。
一条信息可能最终转发给一个或多个消息接收者,这些接收者都无需对消息发送者做出同步回应。整个过程都是异步的。
应用系统之间解耦合
主要体现在如下两点:
发送者和接受者不必了解对方、只需要确认消息。
发送者和接受者不必同时在线。
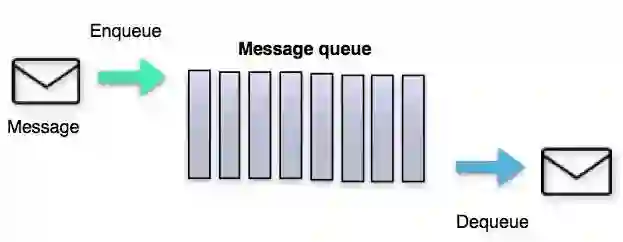
消息队列的传递服务模型
消息队列的传递服务模型如下图所示:

消息队列的的传输模式
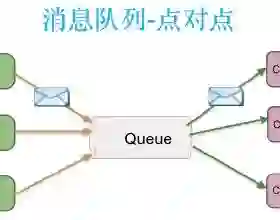
点对点模型
其典型的结构如下图所示:
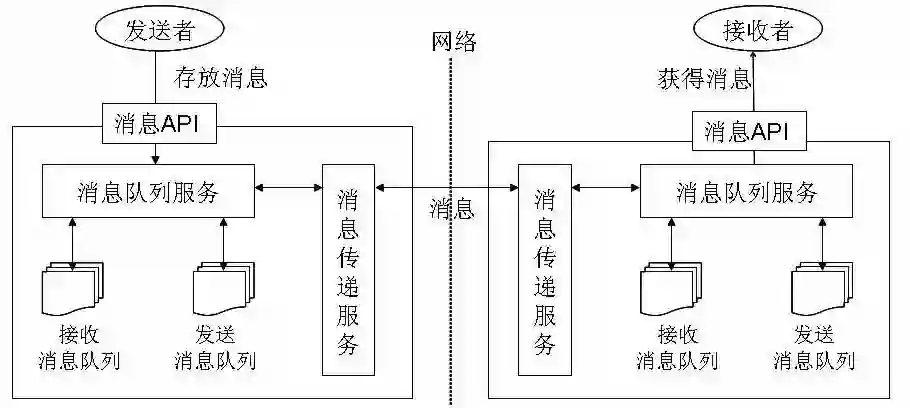
每个消息只用一个消费者。
发送者和接受者没有时间依赖。
接受者确认消息接受和处理成功。
示意图如下所示:

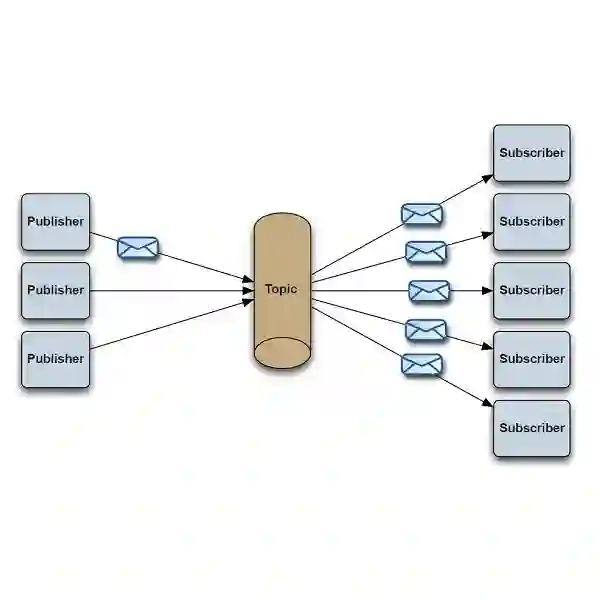
发布/订阅模型(Pub/Sub)
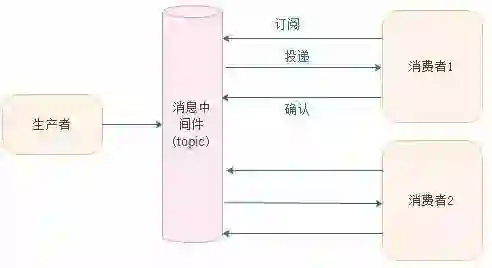
每个消息可以有多个订阅者。
客户端只有订阅后才能接收到消息。
持久订阅和非持久订阅。
注意以下三点:
发布者和订阅者有时间依赖:接受者和发布者只有建立订阅关系才能收到消息。
持久订阅:订阅关系建立后,消息就不会消失,不管订阅者是否都在线。
非持久订阅:订阅者为了接受消息,必须一直在线。当只有一个订阅者时约等于点对点模式。
消息队列应用场景
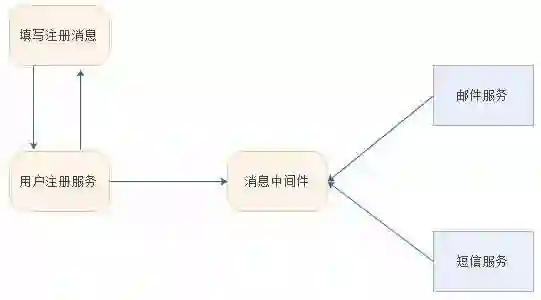
异步处理
应用案例:网站用户注册,注册成功后会过一会发送邮件确认或者短信。
系统解耦
系统之间不是强耦合的,消息接受者可以随意增加,而不需要修改消息发送者的代码。
消息发送者的成功不依赖消息接受者(比如:有些银行接口不稳定,但调用方并不需要依赖这些接口)。
不强依赖于非本系统的核心流程,对于非核心流程,可以放到消息队列中让消息消费者去按需消费,而不影响核心主流程。
最终一致性
先写消息再操作,确保操作完成后再修改消息状态。定时任务补偿机制实现消息可靠发送接收、业务操作的可靠执行,要注意消息重复与幂等设计。
所有不保证 100% 不丢消息的消息队列,理论上无法实现最终一致性。
像 Kafka 一类的设计,在设计层面上就有丢消息的可能(比如定时刷盘,如果掉电就会丢消息)。哪怕只丢千分之一的消息,业务也必须用其他的手段来保证结果正确。
广播
生产者/消费者模式,只需要关心消息是否送达队列,至于谁希望订阅和需要消费,是下游的事情,无疑极大地减少了开发和联调的工作量。
流量削峰和流控
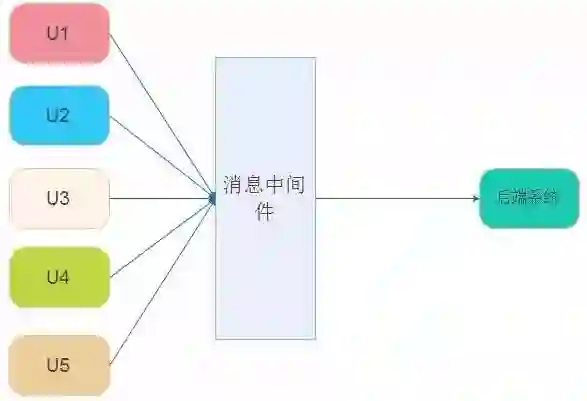
应用案例:
把消息队列当成可靠的消息暂存地,进行一定程度的消息堆积。
定时进行消息投递,比如模拟用户秒杀访问,进行系统性能压测。
日志处理
应用案例:把日志进行集中收集,用于计算 PV、用户行为分析等等。
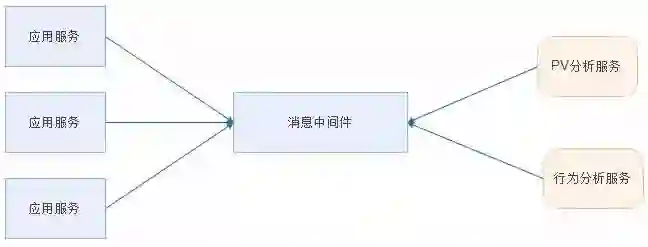
消息通讯
消息队列的推拉模型
Push 推消息模型
Pull 拉消息模型
两种类型的区别
两种类型的区别如下图:

消息队列技术对比
ActiveMQ

主要特性:
服从 JMS 规范:JMS 规范提供了良好的标准和保证,包括:同步或异步的消息分发,一次和仅一次消息分发,消息接收和订阅等等。
遵从 JMS 规范的好处在于,不论使用什么 JMS 实现提供者,这些基础特性都是可用的。
连接灵活性:ActiveMQ 提供了广泛的连接协议,支持的协议有:HTTP/S,IP 多播,SSL,TCP,UDP 等等。对众多协议的支持让 ActiveMQ 拥有了很好的灵活性。
支持的协议种类多:OpenWire、STOMP、REST、XMPP、AMQP。
持久化插件和安全插件:ActiveMQ 提供了多种持久化选择。而且, ActiveMQ 的安全性也可以完全依据用户需求进行自定义鉴权和授权。
支持的客户端语言种类多:除了 Java 之外,还有 C/C++,.Net,Perl, PHP,Python,Ruby。
代理集群:多个 ActiveMQ 代理可以组成一个集群来提供服务。
异常简单的管理:ActiveMQ 是以开发者思维被设计的。所以,它并不需要专门的管理员,因为它提供了简单又实用的管理特性。
有很多种方法可以监控 ActiveMQ 不同层面的数据,包括使用在 JConsole 或者在 ActiveMQ 的 WebConsole 中使用 JMX。
通过处理 JMX 的告警消息,通过使用命令行脚本,甚至可以通过监控各种类型的日志。
部署环境:ActiveMQ 可以运行在 Java 语言所支持的平台之上。
JavaJDK
ActiveMQ 安装包
优点如下:
跨平台(Java 编写与平台无关,ActiveMQ 几乎可以运行在任何的 JVM上)。
可以用 JDBC:可以将数据持久化到数据库。虽然使用 JDBC 会降低 ActiveMQ 的性能,但是数据库一直都是开发人员最熟悉的存储介质。
支持 JMS 规范:支持 JMS 规范提供的统一接口。
支持自动重连和错误重试机制。
有安全机制:支持基于 Shiro,JAAS 等多种安全配置机制,可以对 Queue/Topic 进行认证和授权。
监控完善:拥有完善的监控,包括 WebConsole,JMX,Shell 命令行, Jolokia 的 RESTfulAPI。
界面友善:提供的 WebConsole 可以满足大部分情况,还有很多第三方的组件可以使用,比如 Hawtio。
缺点如下:
社区活跃度不及 RabbitMQ 高。
根据其他用户反馈,会出莫名其妙的问题,会丢失消息。
目前重心放到 ActiveMQ 6.0 产品 Apollo,对 5.x 的维护较少。
不适合用于上千个队列的应用场景。
RabbitMQ

主要特性如下:
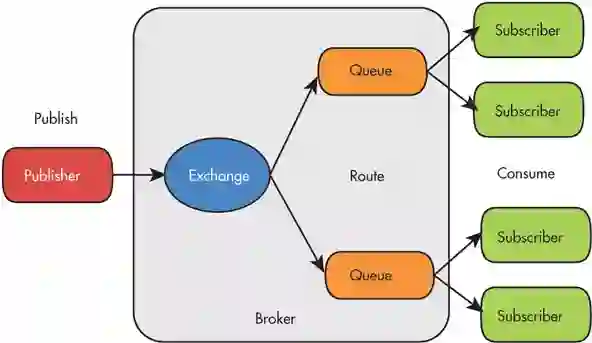
可靠性:提供了多种技术可以让你在性能和可靠性之间进行权衡。这些技术包括持久性机制、投递确认、发布者证实和高可用性机制。
灵活的路由:消息在到达队列前是通过交换机进行路由的。RabbitMQ 为典型的路由逻辑提供了多种内置交换机类型。
如果你有更复杂的路由需求,可以将这些交换机组合起来使用,你甚至可以实现自己的交换机类型,并且当做 RabbitMQ 的插件来使用。
消息集群:在相同局域网中的多个 RabbitMQ 服务器可以聚合在一起,作为一个独立的逻辑代理来使用。
队列高可用:队列可以在集群中的机器上进行镜像,以确保在硬件问题下还保证消息安全。
支持多种协议:支持多种消息队列协议。
支持多种语言:用 Erlang 语言编写,支持只要是你能想到的所有编程语言。
管理界面:RabbitMQ 有一个易用的用户界面,使得用户可以监控和管理消息 Broker 的许多方面。
跟踪机制:如果消息异常, RabbitMQ 提供消息跟踪机制,使用者可以找出发生了什么。
插件机制:提供了许多插件,来从多方面进行扩展,也可以编写自己的插件。
部署环境:RabbitMQ 可以运行在 Erlang 语言所支持的平台之上,包括 Solaris,BSD,Linux,MacOSX,TRU64,Windows 等。
使用 RabbitMQ 需要:
ErLang 语言包
RabbitMQ 安装包
优点如下:
由于 Erlang 语言的特性,消息队列性能较好,支持高并发。
健壮、稳定、易用、跨平台、支持多种语言、文档齐全。
有消息确认机制和持久化机制,可靠性高。
高度可定制的路由。
管理界面较丰富,在互联网公司也有较大规模的应用,社区活跃度高。
缺点如下:
尽管结合 Erlang 语言本身的并发优势,性能较好,但是不利于做二次开发和维护。
实现了代理架构,意味着消息在发送到客户端之前可以在中央节点上排队。此特性使得 RabbitMQ 易于使用和部署,但是使得其运行速度较慢,因为中央节点增加了延迟,消息封装后也比较大。
需要学习比较复杂的接口和协议,学习和维护成本较高。
RocketMQ

主要特性如下:
基于队列模型:具有高性能、高可靠、高实时、分布式等特点。
Producer、Consumer 队列都支持分布式。
Producer 向一些队列轮流发送消息,队列集合称为 Topic。Consumer 如果做广播消费,则一个 Consumer 实例消费这个 Topic 对应的所有队列。
如果做集群消费,则多个 Consumer 实例平均消费这个 Topic 对应的队列集合。
能够保证严格的消息顺序。
提供丰富的消息拉取模式。
高效的订阅者水平扩展能力。
实时的消息订阅机制。
亿级消息堆积能力。
较少的外部依赖。
部署环境:RocketMQ 可以运行在 Java 语言所支持的平台之上。
JavaJDK
安装 Git、Maven
RocketMQ 安装包
优点如下:
单机支持 1 万以上持久化队列。
RocketMQ 的所有消息都是持久化的,先写入系统 PAGECACHE,然后刷盘,可以保证内存与磁盘都有一份数据,而访问时,直接从内存读取。
模型简单,接口易用( JMS 的接口很多场合并不太实用)。
性能非常好,可以允许大量堆积消息在 Broker 中。
支持多种消费模式,包括集群消费、广播消费等。
各个环节分布式扩展设计,支持主从和高可用。
开发度较活跃,版本更新很快。
缺点如下:
支持的客户端语言不多,目前是 Java 及 C++,其中 C++ 还不成熟。
RocketMQ 社区关注度及成熟度也不及前两者。
没有 Web 管理界面,提供了一个 CLI(命令行界面)管理工具带来查询、管理和诊断各种问题。
没有在 MQ 核心里实现 JMS 等接口。
Kafka

主要特性如下:
快速持久化:可以在 O(1) 的系统开销下进行消息持久化。
高吞吐:在一台普通的服务器上即可以达到 10W/S 的吞吐速率。
完全的分布式系统:Broker、Producer 和 Consumer 都原生自动支持分布式,自动实现负载均衡。
支持同步和异步复制两种高可用机制。
支持数据批量发送和拉取。
零拷贝技术(zero-copy):减少 IO 操作步骤,提高系统吞吐量。
数据迁移、扩容对用户透明。
无需停机即可扩展机器。
其他特性:丰富的消息拉取模型、高效订阅者水平扩展、实时的消息订阅、亿级的消息堆积能力、定期删除机制。
部署环境,使用 Kafka 需要:
JavaJDK
Kafka 安装包
优点如下:
客户端语言丰富:支持 Java、.Net、PHP、Ruby、Python、Go 等多种语言。
高性能:单机写入 TPS 约在 100 万条/秒,消息大小 10 个字节。
提供完全分布式架构,并有 Replica 机制,拥有较高的可用性和可靠性,理论上支持消息无限堆积。
支持批量操作。
消费者采用 Pull 方式获取消息。消息有序,通过控制能够保证所有消息被消费且仅被消费一次。
有优秀的第三方 Kafka Web 管理界面 Kafka-Manager。
在日志领域比较成熟,被多家公司和多个开源项目使用。
缺点如下:
Kafka 单机超过 64 个队列/分区时, Load 时会发生明显的飙高现象。队列越多,负载越高,发送消息响应时间变长。
使用短轮询方式,实时性取决于轮询间隔时间。
消费失败不支持重试。
支持消息顺序,但是一台代理宕机后,就会产生消息乱序。
社区更新较慢。
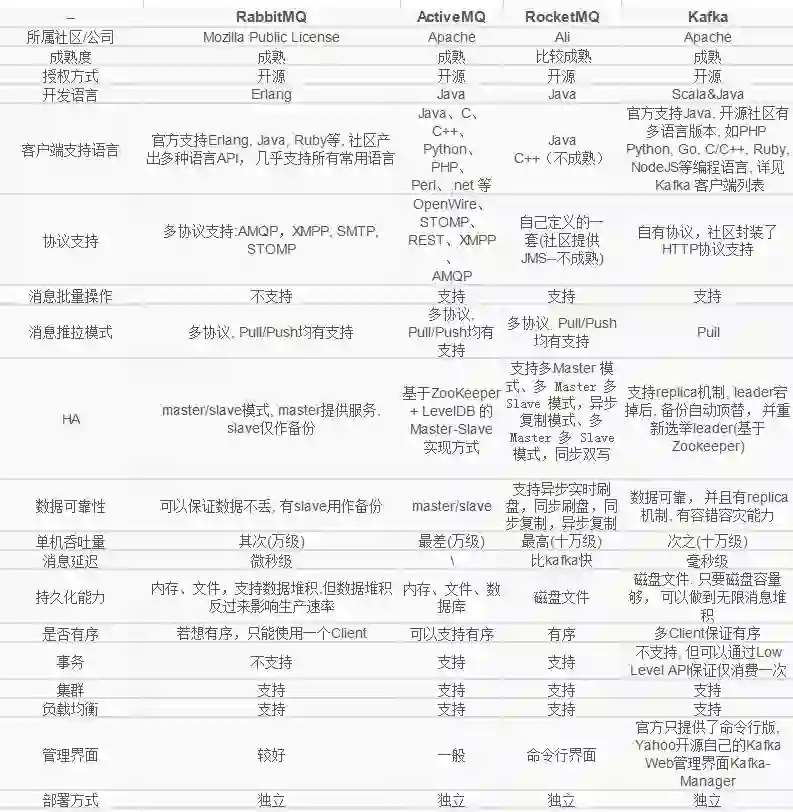
几种消息队列对比
小结
作者:陈林
简介:五年研发与架构经验,曾任职 SAP 中国研发中心后端研发、上海冰鉴科技信息科技有限公司架构师助理,目前担任成都 ThoughtWorks 有限公司高级咨询师与研发人员。熟悉大数据、高并发、负载均衡、缓存、数据库、消息中间件、搜索引擎、容器和自动化等领域。个人学习能力强,技术热情高,热爱开源和写技术博客,善于沟通和分享。
编辑:陶家龙、孙淑娟
出处:转载自微信公众号:零壹技术栈(ID:zero-one-technology)

精彩文章推荐: