【ICML2022】深度潜在粒子的无监督图像表示学习

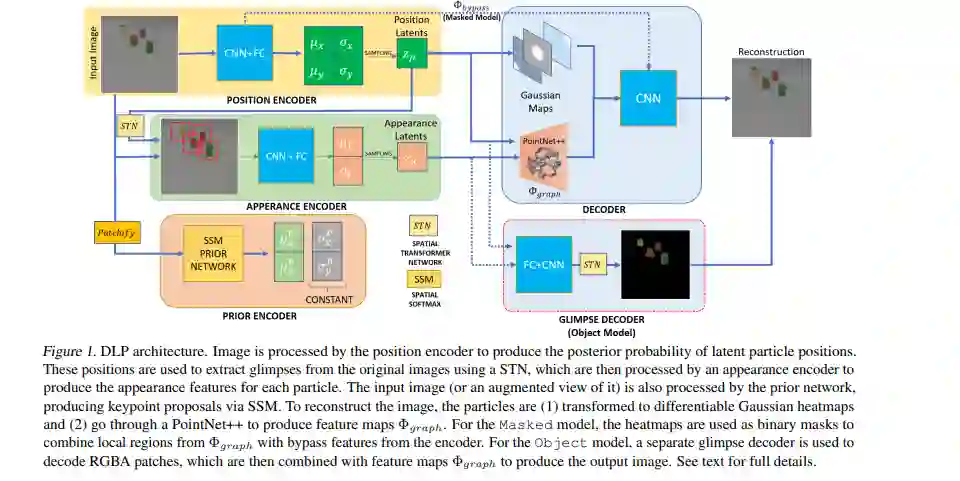
我们提出了一种新的可视化数据表示方法,将对象的位置从外观中分离出来。我们的方法被称为深度隐式粒子(Deep Latent Particles, DLP),将视觉输入分解为低维潜伏“粒子”,其中每个粒子都由其空间位置及其周围区域的特征来描述。为了推动对这种表示的学习,我们遵循了一种基于虚拟空间的方法,并引入了基于空间-softmax架构的粒子位置先验,以及由粒子之间的倒角距离启发的证据下限损失修正。我们证明了我们的DLP表示对于下游任务是有用的,如无监督关键点(KP)检测,图像操作,以及由多个动态对象组成的场景的视频预测。此外,我们展示了我们对问题的概率解释自然地提供了粒子位置的不确定性估计,这可以用于模型选择等任务。视频和代码:
https://taldatech.github.io/ deep-latent-particles-web/。
https://www.zhuanzhi.ai/paper/54bd011def8f275ff0b312c91f2c9799
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“DLPK” 就可以获取《【ICML2022】深度潜在粒子的无监督图像表示学习》专知下载链接



登录查看更多
相关内容
Arxiv
59+阅读 · 2020年1月20日




相关VIP内容
相关资讯
相关论文
Arxiv
59+阅读 · 2020年1月20日