五年后的计算机视觉会是什么样?和CV先驱们一同畅想(下) | CVPR2019

真实世界中视觉系统的表现如何

AI 科技评论按:计算机视觉顶会 CVPR 2019 上举办了首届「Computer Vision After 5 Years - CVPR Workshop」,领域内的多位知名学者受邀演讲,和大家分享他们对于 5 年后的计算机视觉领域发展的看法。
在上篇中,AI 科技评论已经介绍了 Cordelia Schmid、Alexei Efros 两位的演讲内容。这篇中我们继续带来其他几位讲者的内容。
演讲三

Facebook 人工智能研究院(FAIR)的研究科学家、目标检测界的领军人物 Ross Girshick 上午还在教学讲座,下午就在这个研讨会进行又一个演讲。

就在 Ross Girshick 之前演讲的 Alexei Efros 说到有四件我们需要改变看法的事情,Ross 一开场也就说,他的演讲相当于只针对其中的第四点数据集的一点想法。他的演讲主题是「Big Little Data」。

目前在深度学习时代,可以说「大规模、类别均衡的数据集+手工标签+神经网络=不错的表现」,不过这也是我们唯一掌握的模式,所有不符合这个模式的都是还没解决的问题。

在这个演讲里,Ross 打算讨论的是一个和这个模式非常类似,但是还没被解决的问题。


从命名说起,人类和机器之间交流、机器和机器之间的交流会打开一个很大的新挑战:实体命名。自然场景中的物体非常多非常细,对它们的命名是一个尚未得到充分研究的挑战,这也将是未来的重要发展方向。


相比于当前的数据集、当前的对象识别任务中只检测主要的一些物体,如果要检测场景中的所有物体,这有一系列不同:首先需要大幅扩充词汇库,其次,如果希望能服务更丰富的行为的话也需要更丰富的表征。实际上,要检测所有的物体,其实并不仅仅是检测更多类别而已,它会启发很多全新的研究课题。
很明显的,第一个问题:是要如何评价分类结果;第二个问题是,如何应对数据效率、长尾数据的状况。

长尾数据的状况其实远比我们一般印象里的糟糕,他们统计了 COCO 数据集中的类别分布比例,并同步尝试了用更少的数据训练模型。在减少到只有 1k 训练样本时,超过 90% 的类别都仍然有至少 20 个样本,甚至还没有到小样本学习的范畴,但模型的准确率已经出现了大幅下降。
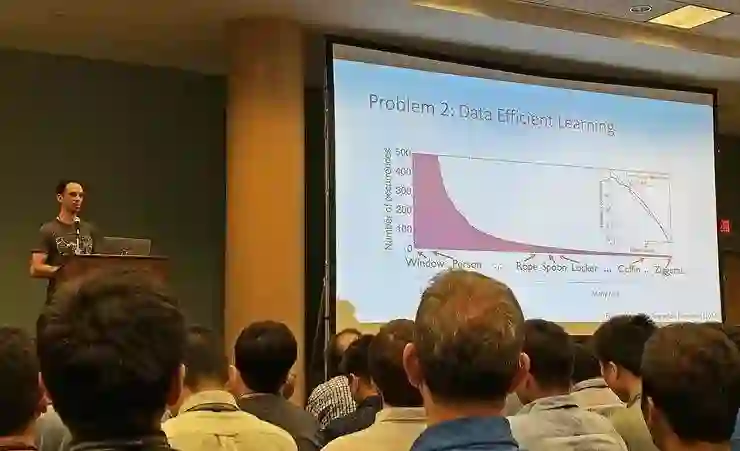
而如果统计更大范围的图片内的类别分布,总的类别数目越大时,最后出现的罕见类别也就越多、每个类别样本越少。

Facebook 探究这个问题的努力是设计了 LVIS 数据集。它基于的是 COCO 数据集中的图像,数据总量很大,但是样本量很小的数据类别也很多。非常多的实例分割标注,但是包含的长尾数据中也有数量很少的类别,这就是 Big Little 两个词的所指。

Ross 说道,构建数据集时就需要重新思考不少东西:过往的数据集构建时,做法都是先选定想要包含的类型(哪一千个类别),再通过关键词搜索对应类别的图片,然后添加到数据集中。这样的结果就是模糊的类别少、类别总数目有限、不同类型的样本分布过于平衡。这其实都是和更广泛的图像、生活中的图像的特性不符的,也达不到检测所有物体的目标。LVIS 的设计目标和方法都有所不同,所以不再有这些特点(也可以说是缺点)。

Ross 着重说了一下他们对「类别」概念的重新思考。目前的对象识别数据集中都有许许多多类别名,但是「类别名只是一种表达」,并不能真的等同于类别本身的定义。

实际上,类别就是具有灵活性和多义性的,比如玩具鹿可以同时属于「玩具」类别和「鹿」类别,小汽车和卡车都可以属于「交通工具」,以及同一个物体可以有不同的称呼。一种直白的处理方式是把所有类别都列出来,然后每一个对象实例都要分别一一标注出它是否属于某个类别。但类别和实例稍微多一点以后这种做法就是不行的。

除此之外,真实世界的物体分类很多时候也就是模糊的,比如 hotdog(热狗)、taco(肉卷)、sandwich(三明治)三者之间的区别就很难说清,cereal(燕麦粥)和 soup(粥)也很类似。对于 toast 的理解就更是令人迷惑了。没有准确的定义,类别间的区别非常模糊。这都说明了没法做以往那样的直白的标注。

Facebook 的解决方案是用联邦数据集的概念,不做所有图像中的实例的精细标注,而是把整个数据集看作许多个类别数据集的集合;其中每个类别数据集由出一定数量的正例和负例组成,除此之外的图像都允许处于未知的状态,不再逼迫分类器一定要给出某个结果。

这种做法也带来了一些标注方面的新特性。建立这个数据集他们花了一年多时间,目前还没完全完成。感兴趣的研究者可以访问 www.lvisdataset.org。

对于数据效率问题,Ross 有一个有趣的说法:我们尝试持续提升 AP 了这么多年,是时候把它降下来了——需要让大家知道这不是一个已经完全解决的问题。



数据中的长尾特性是不可能消除的,检测不同类别对象的 mAP 有明显的高低区别,而且 Ross 认为当前的小样本学习根本就还没发展到可以解决问题的程度。从小样本中学习的能力真的是未来五年中的一个非常重要的课题。

Ross 并没有介绍他们在这方面的新的成果,但是他们将在 ICCV2019 上举办比赛,就基于 LVIS 数据集,通过挑战的过程吸引更多研究者关注长尾小样本学习问题。
演讲四

MIT 电子工程与计算机科学教授 Bill Freeman 的演讲主题是「The future of CV told through seven classic rock songs」。

他说这个主题,用摇滚比喻计算机视觉,其实觉得挺贴切的。不过鉴于这些老歌曲国内读者都不熟悉,这里暂时把比喻都略去,只关注正题内容。

Bill Freeman 一开头也讽刺了过去五年的论文发表模式:翻到计算机视觉教科书的随便哪一页,在那一页讲的课题前面加上「深度」,收集一个相关的数据集,仿照 AlexNet 的样子训练一个 CNN 模型,然后就可以发表在 CVPR 了。


最近几年的一个新风潮是从人类的视觉感知系统获得灵感发表论文,也许接下来五年的计算机视觉论文发表模式会变成:翻开 MIT 的《视觉科学》教科书,随便翻到哪一页,然后仔细地把这一页的概念融入到自己设计的网络中,就可以把论文命名为「一个 xxxx 的架构设计」,然后补充内容以后发表到 CVPR 了。(这当然也是讽刺)

接下来 Bill Freeman 花时间和听众一起讨论了许多视觉系统概念的辨析,大家交换了一下看法。鸟类能够飞行,当时有人认为是因为鸟有羽毛,也有人认为是鸟有翅膀。现在当然公认翅膀才是对飞行来说真正重要的,羽毛不一定需要。他希望大家思考一下,后面的这些概念,对视觉系统来讲哪些是翅膀、哪些是羽毛。也藉由这些讨论,窥探未来计算机视觉研究有待探究的课题。

1 人类视觉系统中独立的背侧和腹侧视觉通路,对类别和位置的分别表征,大多数人认为是羽毛;

2,明确地表征对象的边界,应该是翅膀;3,边界的重建能力,应该是翅膀;
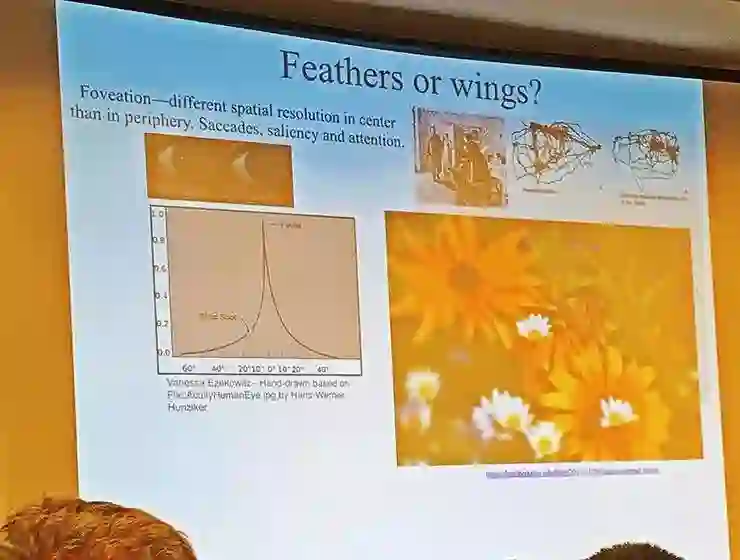
4,Foveation,视野的中央部分最灵敏,Bill 认为这对学术研究来说是羽毛,对商业产品是翅膀(学术研究要研究视觉系统的本质,但商业产品有恰当的功能性就够);

5,感知分类(认为上图中是一个条形贯穿了方形和圆形),应该是翅膀;6,三色视觉,有待讨论;7,高效率,低发热,可移动性,对学术研究来说是羽毛,对商业产品是翅膀;

8,反向连接,大多数人认为应该是翅膀

在这些说完之后,Bill Freeman 告诫大家要多看看前人的成果,不要总是重复发明轮子。
演讲五

第五位演讲的是计算机视觉领域奠基人之一的 UC 伯克利教授 Jitendra Malik。


Malik 开场首先说了像绕口令一样的一句话:科研的艺术,就是要找重要的、未解决的、但能解决的问题,去解决。
Malik 说,其实许多年前的演讲中他就曾讨论过未来:在 2004 年他就做过以《The Hilbert Problems of Computer Vision》的演讲,提出了一些对于计算机视觉系统的问题,希望未来的研究可以给出答案;然后在 2015 年,他做了《The (new) Hilbert Problems of Computer Vision》的演讲,为 2004 年提出的问题给出了一些回答,也提出了新的问题。他说他挺喜欢这个模式的,这个问答过程就是很好的预测和回顾,而且现在我们还可以回过头看以前对更早的问题的回答,以此作为预测未来的参考。唯一的遗憾是,今天这次演讲在 2019 年,距离上一次 2015 年的预测稍微近了点。

2004 年提出的对于早期视觉、静态视觉、动态视觉三个板块的问题,可以看作是在深度学习时代来之前对视觉领域的思考。在 2015 年时给出的回答分别是:
早期视觉问题
如何从图像统计中获得目前还不了解的信息?
在监督学习任务中训练一个多层神经网络就可以获得通用的图像表征
自底向上的图像分割能发展到什么水平?
可以产生一小组物体分割候选,然后可以用分类器添上标签。滑动窗口已经不再需要了。
如何根据自然图像中的阴影、纹理进行推理?
相比于对成像过程进行反向建模,我们可以进行学习。如果数据比较稀疏,我们需要给一些参数设定先验的值;如果有足够的数据,就可以直接用神经网络之类的非参数化方法学习。

静态场景理解
分割和识别之间如何互动?
双向信息流。
场景、物体、部件之间如何互动?
在感知域内能够隐式地捕捉到一些联系,但还不是普遍的结构
识别系统中的设计和学习的角色如何?
尽量多地从数据中学习。不要设计特征。要设计网络结构。

动态场景理解
在大范围运动对应关系中,高阶知识起到什么样的作用?
如何找到好的对应关系是可以通过学习得到的
如何找到并追踪明确的结构?
重建人体形状和动作方面已经有了巨大的进步
如何表征动作?
这还是个开放性的问题,目前我们还不理解动作和活动之间的层次结构

2015 年提出的新问题和现在给出的回答则是
人、地点和物体
世界上的每一个地点建模
已经有了表现优秀的 SLAM、地点分类和视觉导航
对每个物体类别建模
已经有了表现优秀的实例分割、分类和形状重建
用于社交感知的人类建模以及算法
已经有了表现优秀的人类形状、姿态、动作识别

不过对于社交感知的现状,Malik 认为并不乐观:今天的计算机的社交智慧少得可怜;当人类之间互动、人类和外部世界互动时,我们需要能够理解人类的内部状态,例子比如情感状况、身体语言、当前目标

Malik 回忆了图灵当年在图灵机论文较为靠后的章节里对智慧的表述,然后说我们的视觉感知发展之路可以像人类小孩的学习一样经历六个方向的发展。

这六个方向是:多模态学习;渐进学习;物理交互学习;探索;社交学习;使用语言。对于体现不同阶段的内建过程(以观察为监督、以互动为监督、以文化为监督),他认为这是挺合适的思考结构。

最终,我们希望达到的效果是,看到这样一张图(街边长凳上坐着一个演奏手风琴的人,边上经过两个路人),除了能识别出来图中的凳子、识别出人的动作之外,还能推测路人是否会给演奏者留下一些钱。
AI 科技评论总结:在这个研讨会的演讲中,大家关注的不再是发论文时候需要的非常具体的任务和条件限定(做实验所必须的),而是关注整个领域里未解决的问题需要我们如何思考,以及对计算机视觉、甚至就是视觉、自然世界的本质有全面的审视。用全局的、贴近自然世界的视角看过以后,也就更理解了 Ross Girshick 在演讲中说到的这个成功的模式是「我们唯一掌握的模式」,现阶段能在数据集上比较、能在论文中展示算法表现的只是一部分具体刻画后的任务,整个计算机视觉领域内尚未得出结论的问题还有很多,我们都需要用更长远更开放的眼光去看待。到最后,预测五年后会发生什么,远不如提醒大家「我们还可以尝试做什么」来得重要。
AI 科技评论现场参会报道。
2019 年 7 月 12 日至 14 日,由中国计算机学会(CCF)主办、雷锋网和香港中文大学(深圳)联合承办,深圳市人工智能与机器人研究院协办的 2019 全球人工智能与机器人峰会(简称 CCF-GAIR 2019)将于深圳正式启幕。
届时,诺贝尔奖得主JamesJ. Heckman、中外院士、世界顶会主席、知名Fellow,多位重磅嘉宾将亲自坐阵,一起探讨人工智能和机器人领域学、产、投等复杂的生存态势。

今日限量赠送5张1000元门票优惠码,门票原价1999元,打开以下任一链接即可使用,券后仅999元,限量5张,先到先得,送完即止。
https://gair.leiphone.com/gair/coupon/s/5d11f295996f1
https://gair.leiphone.com/gair/coupon/s/5d11f29599497
https://gair.leiphone.com/gair/coupon/s/5d11f2959924b
https://gair.leiphone.com/gair/coupon/s/5d11f29598fe1
https://gair.leiphone.com/gair/coupon/s/5d11f29598d87





