月考+通过Python使用Sqlite3的7个技巧

预计阅读时间:8分钟
我最近在做一个项目,这个项目大量地使用sqlite3来进行数据存储和处理。我最开始没有使用数据库,所有的数据都放置在内存中,查询操作就是遍历列表、对字典对象写if语句这样。但是毕竟内存就那么大,很快,我就需要写程序不断地把数据在内存和磁盘间搬来搬去,这个处理很枯燥,而且效率低下。
我决定试试sqlite3,用了它我们就可以处理更大的数据量了,而且查询操作的耗时会小很多。同时代码也可以进行精简,大量Python逻辑都可以用SQL来代替。
使用sqlite3的过程中我学到了很多知识和技巧,我愿意与大家一起来分享一下。
它们是:
使用批量操作(比如executemany)
大多数时候你不需要游标
游标可以遍历
使用上下文管理器
必要时使用pragmas指令
推迟创建索引
使用占位符进行Python插值
使用批量操作
如果你需要一次性向数据库插入很多行,你不应该使用execute方法,sqlite3提供了一种批量操作的办法:executemany。
相比于这样写:

下面这样写效率更高

事实上,execute底层也是使用了executemany方法,只不过execute每次只插入一行,而后者每次可以插入多行。
我做了一个很小的性能测试,向一张空表中插入100万行数据(数据库存在于内存中),得到的测试结果如下:
executemany:1.6s
execute:2.7s
你不需要游标
......大多数时候
刚开始学习使用的时候我就有一个地方一直很困惑,那就是游标管理。线上文档中的例子通常类似这样:

但是大多数情况下你根本不需要一个游标,你可以直接使用连接对象(其实在文档最后也提到了)。
像execute和executemany这些操作都可以直接在连接对象上执行。下面是一个小例子:
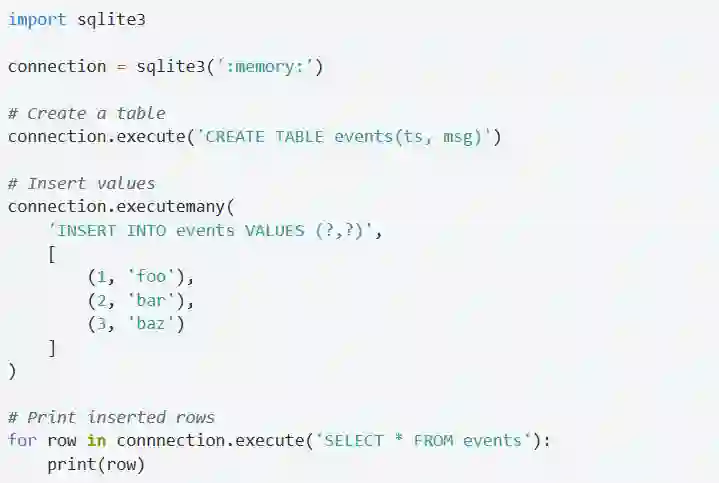
游标是可以遍历的
你经常可以看到示例代码中,作者在select语句的结果上使用fetchone或者fetchall操作。但是我发现,最自然的查看结果的方式是直接在游标上进行遍历:

使用这种方式,你可以在计算得到自己想要的结果后立即释放资源。当然,如果你预先知道自己需要多少记录的时候,你可以使用limit语句限制返回的行数。不过Python生成器真的很方便,它允许你在数据生成和数据消耗的逻辑之间进行解耦。
使用上下文管理器
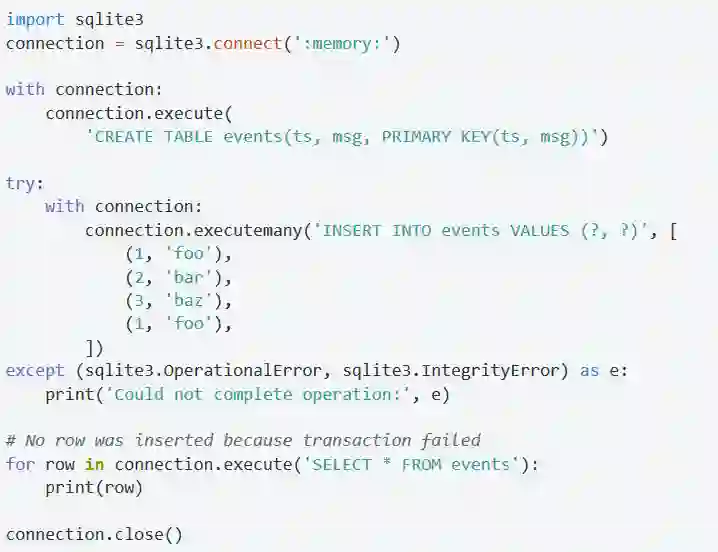
异常是会不时发生的,即便你定义了一个事务,在事务运行过程中也可能会发生异常。为了避免你不得不手动地进行commit和rollback,你可以把连接对象作为一个上下文管理器。在下面的例子中,我们创建了一张表,然后插入了一些错误的数据,因为这些数据的主键上有重复的值。
使用Pragmas
......必要时再使用它
有一些pragmas指令让你能够改变你的程序中sqlite3的行为。比如,关闭synchronous选项可以提高性能

要注意的是这么做可能会有点危险。如果在事务运行中程序不幸崩溃了,数据库可能会进入一种不一致的状态,所以请谨慎使用这个功能。如果你想让插入大量数据的速度快一点,这么做也是一个选项。
推迟索引创建
如果你的数据表需要一些索引,而同时创建数据表时你又需要向表中插入大量数据。那么请先插入数据后再创建索引,这样做可以带来一定的性能提升。
使用占位符来做Python插值
你可能倾向于使用Python字符串操作来向SQL中插入值,不要那样做!那样很不安全,Sqlite3提供了一个更安全的办法:占位符。
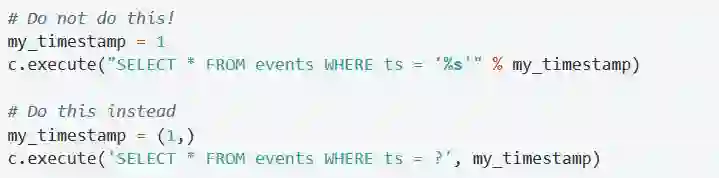
同时,Python的%s替换值得语法,在executemany方法中根本无法使用,所以放弃字符串操作吧,它真的不合适。
结语
这些意见和技巧能不能为您带来实际的好处,取决于您的具体使用场景。在使用过程中您还是需要自己去判断和甄别。
英文原文:https://remusao.github.io/posts/2017-10-21-few-tips-sqlite-perf.html
译者:诗书塞外




