脏数据-缺失值处理


作者简介
勾蒙蒙,R语言资深爱好者。
个人公众号: R语言及生态系统服务。
前文传送门:
没有高质量的数据,就没有高质量的数据挖掘结果。当你拿到一组数据,常规急迫性思维就是尽快把数据模拟、分析、预测以及制图,然而除非常完美的数据之外,结果往往差强人意,归结其原因,你可能是忽略了这组数据中的脏数据!对于脏数据,你是否了解,是否会处理,决定了后续数据分析的结果!
脏数据的存在形式主要有以下几种:
1、缺失值
2、异常值
3、数据的量纲差异
4、多重共线性
接下来几天将用几篇文章依次对脏数据及其处理方式逐一进行说明……
缺失值
即在数据观测中缺测、露测以及缺少记录的数据。对少量缺失数据,可进行手动删除或其他处理,然而面对大量的缺失数据,手动处理则不可弄,下文将以一组实际案例对缺失值的处理进行详细的说明!
文章数据来源于泰坦尼克号沉船存活数据,一个特殊的时代造就了杰克和罗丝感天动地的爱情故事,也为科学留下了宝贵的数据,正所谓:我在你的航程上,你在我的记忆里!
Kaggle中经常会遇到无法注册的情况,详细教程请参考https://blog.csdn.net/FrankieHello/article/details/78230533,亲测有效!
####导入数据集 Data<-read.csv("train.csv") View(Data) ##查看数据结构 Str(Data)
数据共891行,12个变量
$PassengerID:乘客编号 $Survived:活情况(存活:1,死亡:0) $pclsss:船舱等级 $name:乘客姓名 $sex:乘客性别 $age:乘客年龄 $sibsp:同程的兄弟姐妹/配偶 $parch:同程的父母/小孩 $ticket:船票编号 $fare:船票价格 $cabin:客舱号 $embark:登船地点 ##查看数据情况 Summary(Data)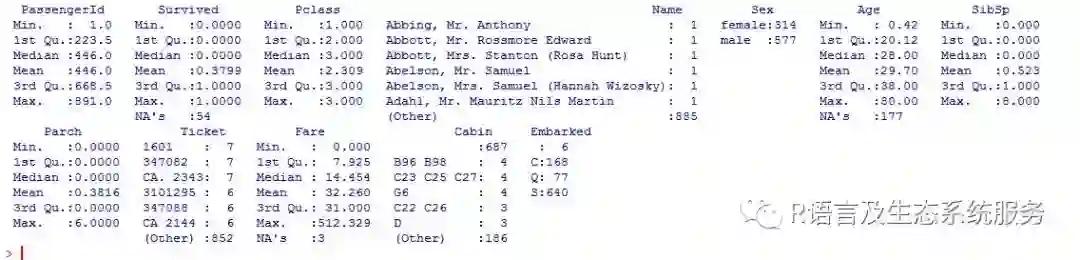
##查看数据的缺失情况 library(VIM) aggr(Data,prop=FALSE,number=TRUE)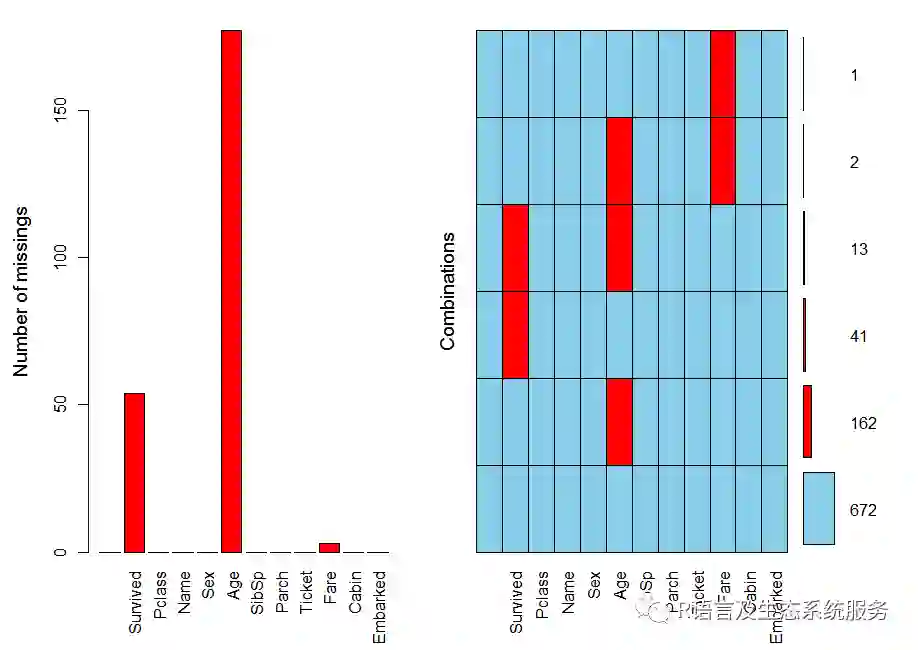
由此可以看出,Survived缺失值为54个,Age字段上缺失值较多,为177个,Fare缺失值为3个。若不及时处理,会对后续的数据分析造成一定的影响。
##处理Fare的缺失值 line<-which(is.na(Data$Fare)) Data[c(line),]
可以发现Fare值为NA的的舱位等级为3等,因此可以考虑用3等舱票价的中位数对Fare值进行处理:
##缺失值中位数处理 newdata<-Data[-c(line),] newfare<-newdata[which(newdata$Pclass==3),10] median(newfare) Data[c(line),10]=median(newfare) ##Age相对缺失的比较多,采用回归法进行插补,首先将Age的存在以及缺失值进行分开 line<-which(is.na(Data$Age)==T) no<-Data[c(line),] exist<-Data[-c(line),] ##建立回归关系 model<-lm(Age~Pclass+Sex+SibSp+Parch+Fare+Embarked,data=exist) summary(model) ##预测 predict<-predict(model,newdata=no)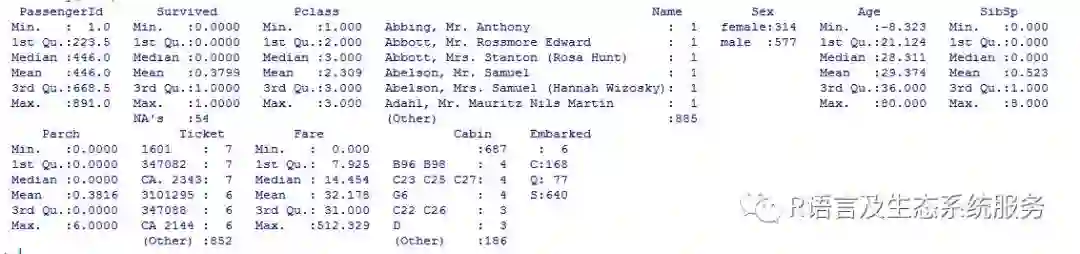


公众号后台回复关键字即可学习
回复 爬虫 爬虫三大案例实战
回复 Python 1小时破冰入门
回复 数据挖掘 R语言入门及数据挖掘
回复 人工智能 三个月入门人工智能
回复 数据分析师 数据分析师成长之路
回复 机器学习 机器学习的商业应用
回复 数据科学 数据科学实战
回复 常用算法 常用数据挖掘算法



