使用 Python 和 Scrapy 半小时爬了 10 个在线商店的网页

作者丨Erdem İşbilen
译者丨Sambodhi
策划丨赵钰莹
获取启动 App 项目所需的源数据是一步。即便你是全栈开发人员,希望开发一款出色的 Web 应用程序,并能全身心投入到项目中。在编写代码之前,仍然需要一个与领域相关的数据集。这是因为现代应用程序会同时或成批处理大量数据,以便为其用户提供价值。本文,我将解释生成这样一个数据集的工作流程。你将会看到,我在没有任何人工干预的情况下是如何对许多网站进行自动网页抓取的。
我的目标是为价格比较网络应用程序生成一个数据集。我将使用的产品类别以手提袋为例。对于这样的应用,应该每天从不同的在线商店那里收集手提包的产品信息和价格信息。尽管有些在线商店提供了 API 让你访问所需的信息,但并非所有在线商店都会这么做。所以,网页抓取不可避免。
在本文的示例中,我将使用 Python 和 Sparky 为 10 个不同的在线商店生成网络蜘蛛(Web spider)。然后,我将使用 Apache Airflow 自动化这一过程,这样就不需要人工干预来定期执行整个过程。
你可以在 GitHub 仓库 找到所有相关的源代码,也可以访问在线 Web 应用程序,使用的是网页抓取项目提供的数据。
在开始任何网页抓取项目之前,必须先定义哪些网站将包含在项目中。我决定抓取 10 个网站,这些网站是土耳其手提包类别中访问量最大的在线商店。
在创建 Scrapy 蜘蛛之前,必须将 Scrapy 安装到计算机中,并生成 Scrapy 项目。请查看下面的帖子了解更多的信息。
Fuel Up the Deep Learning: Custom Dataset Creation with Web Scraping (推动深度学习:使用网页抓取创建自定义数据集)
安装 Scrapypip install scrapy安装用于下载产品图片的图像pip install image使用 Scrapy 开始网页抓取项目scrapy startproject fashionWebScrapingcd fashionWebScrapingls创建项目文件夹,如下所述mkdir csvFilesmkdir images_scrapedmkdir jsonFilesmkdir utilityScripts
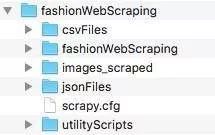
项目的文件夹结构
我在本地计算机上创建了一个文件夹结构,将项目文件整齐地放入不同文件夹。csvFiles 文件夹包含了每个被抓取的网站的 CSV 文件。网络蜘蛛将从那些 CSV 文件中读取“起始 URL”来启动网页抓取,因为我不想在网络蜘蛛中对它们进行硬编码。
fashionWebScraping 文件夹包含 Scrapy 蜘蛛和助手脚本,比如 settings.py、item.py 和 pipelines.py。我们必须修改其中一些 Scrapy 助手脚本,才能成功执行网页抓取过程。
抓取的产品图像将保存在 images_scraped 文件夹中。
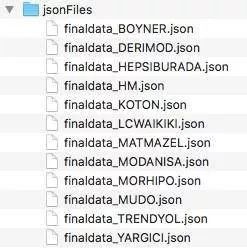
在网页抓取过程中,所有的产品信息,如价格、名称、产品链接和图像链接都将存储在 jsonFiles 文件夹中的 JSON 文件中。
deldub.py 用于在网页抓取结束后,检测并删除 JSON 文件中重复的产品信息。
jsonPrep.py 是另一个实用程序脚本,用于在网页抓取结束后,检测并删除 JSON 文件中的空行项。
deleteFiles.py 可删除在上一次网页抓取会话中生成的所有 JSON 文件。
jsonToes.py 通过读取 JSON 文件,在远程位置填充 ElasticSearch 集群。这是提供实施全文搜索体验所必需的。
sitemap_gen.py 用于生成涵盖所有产品链接的站点地图。
创建项目文件夹后,下一步就是使用我们要抓取的每个网站的起始 URL 来填充 CSV 文件。几乎所有的电子商务网站都提供分页功能,以便通过产品列表为用户导航。每次导航到下一页时,URL 中的 page 参数都会增加。请参见下面的示例 URL,其中使用了 page 参数。
https://www.derimod.com.tr/kadin-canta-aksesuar/?page=1我将使用 { } 占位符,这样就可以通过增加 page 的值来对 URL 进行迭代。我还将使用 CSV 文件中的 gender 列来定义特定 URL 的性别类别。
因此,最终的 CSV 文件看起来如下图所示:

同样的原则,也适用于项目中的其他网站,可以在我的 GitHub 仓库中找到已填充的 CSV 文件。
要开始网页抓取,我们必须修改 items.py 来定义用于存储抓取数据的 item objects。
为了定义通用输出数据格式,Scrapy 提供了 Item 类。Item 对象是适用于收集抓取的数据的简单容器。它们提供了一个类似字典的 API,有一个方便的语法来生命它们可用的字段——引自 scrapy.org
# fashionWebScraping 文件夹中的 items.pyimport scrapyfrom scrapy.item import Item, Fieldclass FashionwebscrapingItem(scrapy.Item):#与产品相关的项,如 Id、名称、价格等gender=Field()productId=Field()productName=Field()priceOriginal=Field()priceSale=Field()#要存储链接的项imageLink = Field()productLink=Field()#公司名称项company = Field()passclass ImgData(Item):#用于下载产品图像的图像管道项image_urls=scrapy.Field()=scrapy.Field()
然后,我们必须修改 settings.py 。这是自定义网络蜘蛛的图像管道和行为所必需的。
通过 Scrapy 设置,你可以自定义所有 Scrapy 组件的行为,包括核心、扩展、管道和网络蜘蛛本身——引自 scrapy.org
# fashionWebScraping 文件夹中的 settings.py# fashionWebScraping 项目的 Scrapy 设置# 为简单起见,此文件仅包含被认为重要或常用的设置。你可以参考文档找到更多的设置:# https://doc.scrapy.org/en/latest/topics/settings.html# https://doc.scrapy.org/en/latest/topics/downloader-middleware.html# https://doc.scrapy.org/en/latest/topics/spider-middleware.htmlBOT_NAME = 'fashionWebScraping'SPIDER_MODULES = ['fashionWebScraping.spiders']NEWSPIDER_MODULE = 'fashionWebScraping.spiders'# 通过在用户代理上标识自己(和你的网站),负责任的抓取。USER_AGENT = 'fashionWebScraping'# 遵守 rebots.txt 规则ROBOTSTXT_OBEY = True# 参阅 https://doc.scrapy.org/en/latest/topics/settings.html# 下载延迟# 另请参阅 autothrottle 的设置和文档# 这样可以避免对服务器造成太大的压力DOWNLOAD_DELAY = 1# 重写默认的请求报头:DEFAULT_REQUEST_HEADERS = {'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8','Accept-Language': 'tr',}# 配置项目管道# 参阅 https://doc.scrapy.org/en/latest/topics/item-pipeline.htmlITEM_PIPELINES = {'scrapy.pipelines.images.ImagesPipeline': 1}IMAGES_STORE = '/Users/erdemisbilen/Angular/fashionWebScraping/images_scraped'
item.py 和 settings.py 对我们项目中的所有网络蜘蛛都有效。
Scrapy Spiders 是用于定义如何抓取某个站点(或一组站点)的类,包括如何执行抓取(即跟随链接),以及如何从其页面中提取结构化数据(即抓取项目)。换言之,Spiders 是你定义特定站点(或者在某些情况下为一组站点)的网络蜘蛛和解析页面的自定义行为的地方——引自 scrapy.org
fashionWebScraping $ scrapy genspider fashionBOYNER boyner.com 在模块中使用 basic 模板创建网络蜘蛛 fashionBOYNER:fashionWebScraping.spiders.fashionBOYNER
上面的 shell 命令创建一个空的 spider 文件。让我们将这些代码写入到我们的 fashionBOYNER.py 文件中:
# fashionWebScraping/Spiders 文件夹中的 'fashionBOYNER.py' 文件# 导入 scrapy 和 scrapy 项import scrapyfrom fashionWebScraping.items import FashionwebscrapingItemfrom fashionWebScraping.items import ImgDatafrom scrapy.http import Request# 从 csv 文件读取import csvclass FashionboynerSpider(scrapy.Spider):name = 'fashionBOYNER'allowed_domains = ['BOYNER.com']start_urls = ['http://BOYNER.com/']# 此函数通过跟踪 csv 文件中的起始 URL 来帮助我们抓取网站的全部内容def start_requests(self):# 从 csv 文件读取主类别 URLwith open ("/Users/erdemisbilen/Angular/fashionWebScraping/csvFiles/SpiderMainCategoryLinksBOYNER.csv", "rU") as f:reader=csv.DictReader(f)for row in reader:url=row['url']# 以增量方式更改 page 值来浏览产品列表# 你可以根据最大值来调整产品数量的范围值,默认是抓取 30 个网页link_urls = [url.format(i) for i in range(1,30)]for link_url in link_urls:print(link_url)# 将包含产品的每个链接传递给带有性别元数据的 parse_ product_pages 函数request=Request(link_url, callback=self.parse_product_pages,meta={'gender': row['gender']})yield request# 此函数在 xpath 的帮助下抓取网页数据def parse_product_pages(self,response):item=FashionwebscrapingItem()# 获取 HTML 块,其中列出了所有的产品。# <div> HTML 元素,具有 "product-list-item" 类名content=response.xpath('//div[starts-with(@class,"product-list-item")]')# 循环遍历内容中的每个 <div> 元素for product_content in content:image_urls = []# 获取产品详细信息并填充项item['productId']=product_content.xpath('.//a/@data-id').extract_first()item['productName']=product_content.xpath('.//img/@title').extract_first()item['priceSale']=product_content.xpath('.//ins[@class="price-payable"]/text()').extract_first()item['priceOriginal']=product_content.xpath('.//del[@class="price-psfx"]/text()').extract_first()if item['priceOriginal']==None:item['priceOriginal']=item['priceSale']item['imageLink']=product_content.xpath('.//img/@data-original').extract_first()item['productLink']="https://www.boyner.com.tr"+product_content.xpath('.//a/@href').extract_first()image_urls.append(item['imageLink'])item['company']="BOYNER"item['gender']=response.meta['gender']if item['productId']==None:breakyield (item)# 下载 image_urls 中包含的图像yield ImgData(image_urls=image_urls)def parse(self, response):pass
我们的 spider 类包含两个函数,即 start_requests 和 parse_product_pages。
在 start_requests 函数中,我们从已经生成的特定 CSV 文件中读取起始 URL 信息。然后,我们对占位符 {} 进行迭代,将产品页面的 URL 传递给 parse_product_pages 函数。
我们还可以使用 meta={‘gender’: row[‘gender’]} 参数将 gender 元数据传递给 Request 方法中的 parse_product_pages 函数。
在 parse_product_pages 函数中,我们执行实际的网页抓取,并用抓取的数据填充 Scrapy 项。
我使用 Xpath 来定位网页上包含产品信息的 HTML 部分。
下面的第一个 XPath 表达式从当前正在抓取的网页中提取整个产品列表。所有必需的产品信息都包含在内容的 div 元素中。
# // 从当前节点中选择与所选内容匹配的节点,无论它们在何处#//'//div[starts-with(@class,"product-list-item")]'选择所有的 div 元素,这些元素具有类值 startcontent = response.xpath('//div[starts-with(@class,"product-list-item")]')
我们需要遍历 content 以获取各个产品,并将它们存储在 Scrapy 项中。借助 XPath 表达式,我们可以很容易地在 content 中找到所需的 HTML 元素。
# 遍历内容中的每个 <div> 元素for product_content in content:image_urls = []# 获取产品详细信息并填充项# ('.//a/@data-id') 提取 product_content 中的 <a> 元素的 'data-id' 值item['productId']=product_content.xpath('.//a/@data-id').extract_first()# ('.//img/@title') 提取 product_content 中的 <img> 元素的 `title` 值item['productName']=product_content.xpath('.//img/@title').extract_first()# ('.//ins[@class= "price-payable"]/text()') 提取 <ins> 元素的文本值,该元素具有 product_content 中的 `price-payable` 类别属性。item['priceSale']=product_content.xpath('.//ins[@class="price-payable"]/text()').extract_first()# ('.//del[@class="price-psfx"]/text()') 提取 <del> 元素的文本值,该元素具有 product_content 中的 `price-psfx` 类属性。item['priceOriginal']=product_content.xpath('.//del[@class="price-psfx"]/text()').extract_first()if item['priceOriginal']==None:item['priceOriginal']=item['priceSale']# ('.//img/@data-original') 提取 product_content 中的 <img> 元素的 `data-original` 值item['imageLink']=product_content.xpath('.//img/@data-original').extract_first()# ('.//a/@href') 提取 product_content 中的 <a> 元素的 `href`值item['productLink']="https://www.boyner.com.tr"+product_content.xpath('.//a/@href').extract_first()# 将产品图片链接分配到图像管道定义的 `image_urls` 中image_urls.append(item['imageLink'])item['company']="BOYNER"item['gender']=response.meta['gender']if item['productId']==None:breakyield (item)**# 下载 image_urls 中包含的图像yield ImgData(image_urls=image_urls)
同样的原则也适用于其他网站。你可以在我的 GitHub 仓库中看到所有 10 个网络蜘蛛的代码。
在抓取过程中,每个产品项都存储在一个 JSON 文件中。每个网站都有一个特定的 JSON 文件,该文件在每次网络蜘蛛抓取时都填充了数据。
fashionWebScraping $ scrapy crawl -o rawdata_BOYNER.json -t jsonlines fashionBOYNER与 JSON 格式相比,使用 jsonlines 格式的内存效率要高得多,特别是当你在一个会话中抓取了大量网页数据时。
注意,JSON 文件名以 rawdata 开头,这表明下一步是在我们的应用程序中使用抓取的原始数据之前,检查并验证它们。
在网页抓取过程结束之后,你可能需要先从 JSON 文件中删除一些行项,然后才能在应用程序中使用它们。
JSON 文件中可能有那些带有空字段或重复值的行项。这两种情况,都需要一个修正过程,我使用的是 jsonPrep.py 和 deldub.py 来处理这两种情况。
jsonPrep.py 查找带有空值的行项,并在检测到它们时将其删除。你可以查看下面的带有解释的示例代码:
# fashionWebScraping/utilityScripts 文件夹中的 `jsonPrep.py`文件import jsonimport sysfrom collections import OrderedDictimport csvimport os# 从 jsonFiles.csv 文件中读取需要验证的所有 json 文件的名称和位置with open("/Users/erdemisbilen/Angular/fashionWebScraping/csvFiles/ jsonFiles.csv", "rU") as f:reader=csv.DictReader(f)# 迭代 jsonFiles.csv 中列出的 json 文件for row in reader:# 从 jsonFiles.csv 文件中读取 jsonFile_raw 列jsonFile=row['jsonFile_raw']# 打开 the jsonFilewith open(jsonFile) as json_file:data = []i = 0seen = OrderedDict()# 对 json 文件中的行进行迭代for d in json_file:seen = json.loads(d)# 如果产品 Id 为空,则不包括行项try:if seen["productId"] != None:for key, value in seen.items():print("ok")i = i + 1data.append(json.loads(d))except KeyError:print("nok")print (i)baseFileName=os.path.splitext(jsonFile)[0]# 通过从 `file_name_prep` 行读取 filename,将结果写成 json 文件with open('/Users/erdemisbilen/Angular/fashionWebScraping/jsonFiles/'+row['file_name_prep'], 'w') as out:json.dump(data, out)
在删除重复的行项之后,结果以 finaldata 开头的文件名保存到 jsonFiles 项目文件夹中。
一旦我们定义了网页抓取过程后,就可以进入工作流程自动化了。我将使用 Apache Airflow,这是 Airbnb 开发的,基于 Python 的工作流自动化工具。
我将提供安装和配置 Apache Airflow 的终端命令,你可以参考我下面的帖子进一步了解更多的细节:
My Deep Learning Journey: From Experimentation to Production (我的深度学习之旅:从实验到生产)
$ python3 --versionPython 3.7.3$ virtualenv --version15.2.0$ cd /path/to/my/airflow/workspace$ virtualenv -p `which python3` venv$ source venv/bin/activate(venv) $ pip install apache-airflow(venv) $ mkdir airflow_home(venv) $ export AIRFLOW_HOME=`pwd`/airflow_home(venv) $ airflow initdb(venv) $ airflow webserver
在 Airflow 中,DAG 或有向无环图(Directed Acyclic Graph)是你希望运行的所有任务的集合,其组织方式反映了它们之间的关系和依赖关系。例如,一个简单的 DAG 可以由三个任务组成:A、B 和 C。可以说,A 必须先成功运行,B 才能运行,但是 C 可以随时运行。可以说任务 A 在 5 分钟后超时,而任务 B 在失败的情况下,最多可以重启 5 次。也可以说,工作流程将在每晚 10 点运行,但不应在某个特定日期才开始。
DAG 是在 Python 文件中定义的,用于组织任务流。我们不会在 DAG 文件中定义实际的任务。
让我们创建一个 DAG 文件夹和一个空的 Python 文件,开始用 Python 代码定义我们的工作流程。
(venv) $ mkdir dags在一个 DAG 文件中,有几个由 Airflow 提供的操作符来描述任务。我在下面列出了几个常用的。
BashOperator:执行 bash 命令。
PythonOperator:调用任意 Python 函数。
EmailOperator:发送一封电子邮件。
SimleHttpOperator:发送一个 HTTP 请求。
Sensor:等待特定的时间、文件、数据库行、S3 键等等。
目前我计划只使用 BashOperator,因为我将使用 Python 脚本完成所有任务。
因为我将使用 BashOperator,所以最好有一个 bash 脚本,其中包含了一个特定任务的所有命令,以简化 DAG 文件。
根据本教程,我为每个任务生成了 bash 脚本。你可以在我的 GitHub 仓库 中找到它们。
然后,我可以使用创建的 bash 命令编写我的 DAG 文件,如下所示。使用下面的配置,我的任务将由 Airflow 每天安排和执行。你可以根据需要,更改 DAG 文件中的开始日期或计划间隔。你还可以使用本地执行器或 celery 执行器并行运行任务实例。由于我使用的是最原始的执行器——顺序执行器,因此,我所有的任务实例都将按顺序工作。
# Airflow dag 文件夹中的'fashionsearch_dag.py'文件import datetime as dtfrom airflow import DAGfrom airflow.operators.bash_operator import BashOperatorfrom datetime import datetime, timedeltadefault_args = {'owner': 'airflow','depends_on_past': False,'start_date': datetime(2019, 11, 23),'retries': 1,'retry_delay': timedelta(minutes=5),# 'queue': 'bash_queue',# 'pool': 'backfill',# 'priority_weight': 10,# 'end_date': datetime(2016, 1, 1),}dag = DAG(dag_id='fashionsearch_dag', default_args=default_args, schedule_interval=timedelta(days=1))#此任务将删除在以前抓取会话中生成的所有 json 文件t1 = BashOperator(task_id='delete_json_files',bash_command='run_delete_files',dag=dag)# 此任务运行 www.boyner.com 的网络蜘蛛,并使用所抓取的数据填充相关的 json 文件t2 = BashOperator(task_id='boyner_spider',bash_command='run_boyner_spider',dag=dag)# 此任务运行 www.derimod.con 的网络蜘蛛,并使用抓取的数据填充相关的 json 文件t3 = BashOperator(task_id='derimod_spider',bash_command='run_derimod_spider',dag=dag)# 此任务运行 www.hepsiburada.com 的网络蜘蛛,并使用抓取的数据填充相关的 json 文件t4 = BashOperator(task_id='hepsiburada_spider',bash_command='run_hepsiburada_spider',dag=dag)# 此任务运行 www.hm.com 的网络蜘蛛,并使用抓取的数据填充相关的 json 文件t5 = BashOperator(task_id='hm_spider',bash_command='run_hm_spider',dag=dag)# 此任务运行 www.koton.com 的网络蜘蛛,并使用抓取的数据填充相关的 json 文件t6 = BashOperator(task_id='koton_spider',bash_command='run_koton_spider',dag=dag)# 此任务运行 www.lcwaikiki.com 的网络蜘蛛,并使用抓取的数据填充相关的 json 文件t7 = BashOperator(task_id='lcwaikiki_spider',bash_command='run_lcwaikiki_spider',dag=dag)# 此任务运行 www.matmazel.com 的网络蜘蛛,并使用抓取的数据填充相关的 json 文件t8 = BashOperator(task_id='matmazel_spider',bash_command='run_matmazel_spider',dag=dag)# 此任务运行 www.modanisa.com 的网络蜘蛛,并使用抓取的数据填充相关的 json 文件t9 = BashOperator(task_id='modanisa_spider',bash_command='run_modanisa_spider',dag=dag)# 此任务运行 www.morhipo.com 的网络蜘蛛,并使用抓取的数据填充相关的 json 文件t10 = BashOperator(task_id='morhipo_spider',bash_command='run_morhipo_spider',dag=dag)# 此任务运行 www.mudo.com 的网络蜘蛛,并使用抓取的数据填充相关的 json 文件t11 = BashOperator(task_id='mudo_spider',bash_command='run_mudo_spider',dag=dag)# 此任务运行 www.trendyol.com 的网络蜘蛛,并使用抓取的数据填充相关的 json 文件t12 = BashOperator(task_id='trendyol_spider',bash_command='run_trendyol_spider',dag=dag)# 此任务运行 www.yargici.com 的网络蜘蛛,并使用抓取的数据填充相关的 json 文件t13 = BashOperator(task_id='yargici_spider',bash_command='run_yargici_spider',dag=dag)# 此任务检查并删除 json 文件中的空行项t14 = BashOperator(task_id='prep_jsons',bash_command='run_prep_jsons',dag=dag)# 此任务检查并删除 json 文件中的重复行项t15 = BashOperator(task_id='delete_dublicate_lines',bash_command='run_del_dub_lines',dag=dag)# 此任务使用 JSON 文件中的数据填充远程 ES 集群t16 = BashOperator(task_id='json_to_elasticsearch',bash_command='run_json_to_es',dag=dag)# 对于顺序执行器,所有任务都依赖于前一个任务# 不可能并行执行任务# 至少在执行并行任务时使用本地执行器t1 >> t2 >> t3 >> t4 >> t5 >> t6 >> t7 >> t8 >> t9 >> t10 >> t11 >> t12 >> t13 >> t14 >> t15 >> t16
要启动 DAG 工作流程,我们需要运行 Airflow Scheduler。这将使用 airflow.cfg 文件中指定的配置执行计划程序。调度器(Scheduler)监视位于 dags 文件夹中的每个 DAG 中的每个任务,如果任务的依赖关系已经满足,就会触发任务的执行。
(venv) $ airflow scheduler一旦运行了 Airflow 调度器,我们就可以通过浏览器访问 http://0.0.0.0:8080 来查看任务的状态。Airflow 提供了一个用户界面,我们可以在其中查看并跟踪计划的 DAG。
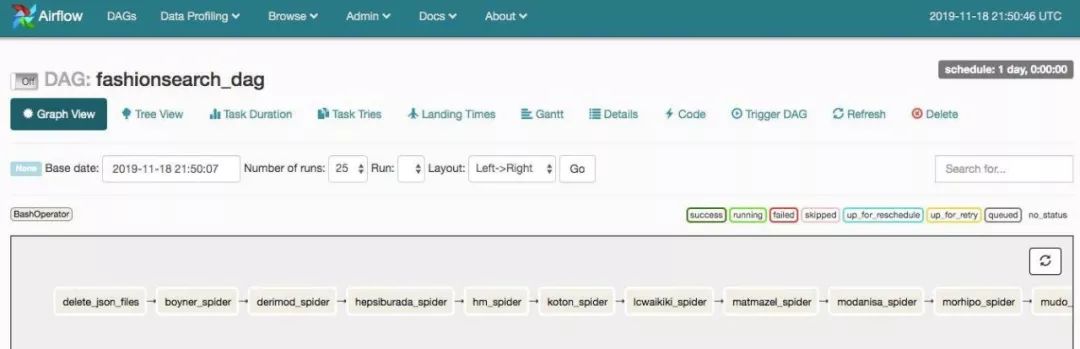
AirFlow DAG 图形视图
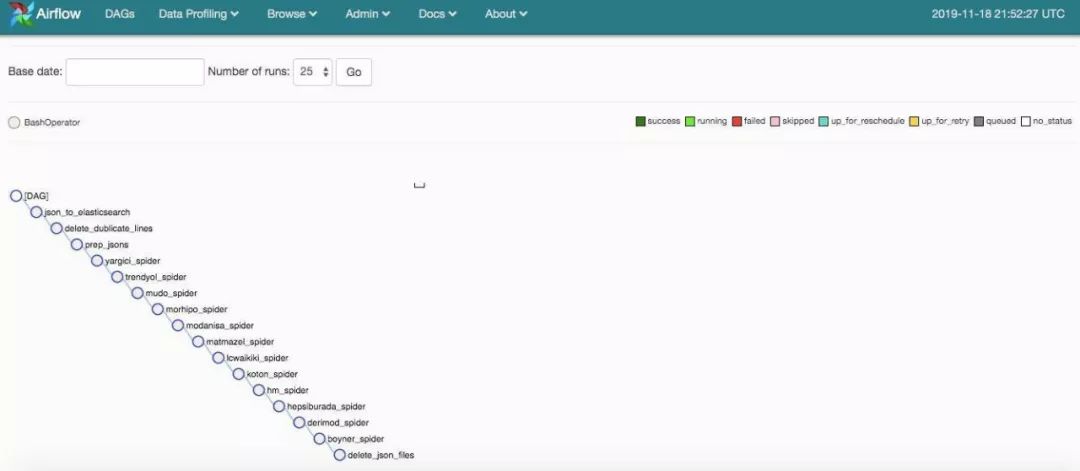
AirFlow DAG 树状视图
本文演示了我从头到尾实现网页抓取的整个工作流。我希望本文能够让你掌握网页抓取和工作流自动化的基础知识。
Erdem İşbilen,汽车工程师、机械工程师。有丰富的项目质量团队领导经验,自 2001 年以来,在汽车行业工作,有着丰富的项目质量团队领导经验,拥有海峡大学(Bogazici University)汽车工程专业的理学硕士学位。爱好深度学习和机器学习。
原文链接:
https://towardsdatascience.com/web-scraping-of-10-online-shops-in-30-minutes-with-python-and-scrapy-a7f66e42446d

点个在看少个 bug 👇





