


长按识别二维码享更多精彩
↑ 点击上方蓝字关注我们,和小伙伴一起聊技术!
作者 | 吴瑞诚
文章来源GitChat,CSDN独家合作发布,点击「阅读原文」查看交流实录
斗鱼是时下国内最大的游戏直播平台,日活用户达2000万,主播日活达40,000人,ALEXA全球排名约200名、国内约20名(高于优酷、Bilibili等站)。本文作者吴瑞诚,目前负责斗鱼数据平台部,本文中他将分享斗鱼大数据这块的玩法儿,包括斗鱼大数据平台的整体架构、斗鱼数据仓库、斗鱼个性推荐系统以及斗鱼风控系统。
这是一个典型的斗鱼直播间,是斗鱼最主要的内容形态:左边是视频区,上面飘过的文字就是弹(dàn)幕,直播网站上用户和主播互动的最主要形式。弹幕服务是性能压力最大的服务之一,相当于是需要百万人群聊时的消息推送量;视频区下面是礼物赠送区;右侧是弹幕区,Tab页上是排行榜,用户对该直播间的贡献值,土豪喜闻乐见。
14年加入斗鱼,当时负责的第一个业务是用shell脚本,从主站服务器上拉Nginx log到Hive集群中,统计产生报表。随着网站数据量的增长和配备约来越完备,从最开始的小系统越做越大,做到现在这个架构。
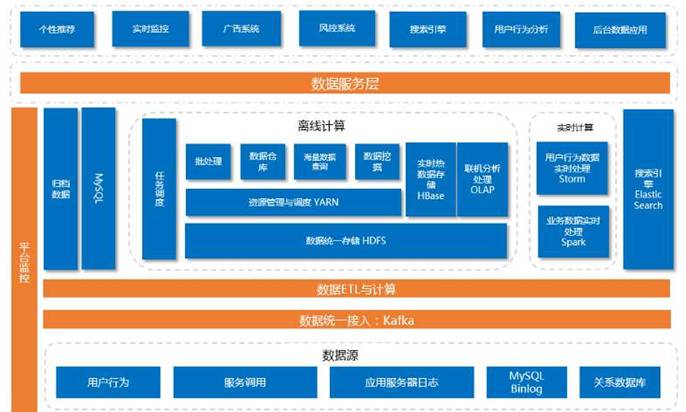
这个架构差不多是在16年初的时候成型的,主要包括:数据源层,用户行为打点、服务日志、Nginx/PHP日志(离线和实时两条数据流)、线上MySQL库、MongoDB、Redis存储数据接入层,包括了Kafka,负责接入打点上报(最大吞吐量约200w TPS)、Canal/Sqoop(主要解决数据库数据接入问题)、Flume/Logstash/rsyslog等实时日志;数据预处理层,简单的清洗和聚合计算;存储层,典型的系统HDFS(文件存储)、HBase(KV存储)、Kafka(消息缓存);计算层,主要包含了典型的所有计算模型的计算引擎,包含了MR、Hive、Storm、Spark以及深度学习平台比如Tensorflow等等再往上就是数据服务层,主要提供对外数据服务。这一块现在主要是基于Docker实现的一整套微服务环境来支撑。
大数据管理平台
下面先简单介绍一下各个组件的玩法,首先是大数据管理平台,承载所有的元数据管理、统一监控系统、报表展示、任务调度、发布系统等所有配套功能。
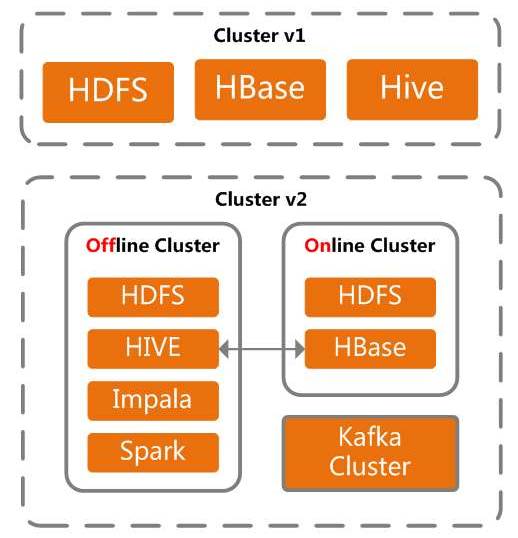
基础集群架构:
可以看到,清晰地区别了online 和offline 集群。
机器配置:
现负责约300台高配服务器,Dell 730xd,32Cores 128/256G内存,16*6T Sata Disk。
Hadoop大集群150台物理机,5PB数据,日增量约20T。
实时离线集群分离,避免资源竞争造成业务处理抖动。集群分离后也可以更安全的对集群进行运维操作;使用Kafka作为MQ,更确切说是消息通道。
OLAP查询引擎Impala
Impala之前,我们有使用Presto的经验,后来因为运维上的问题,暂时下线了。Kylin15年很早的时候,在北京和kylingence官方有过一次深入沟通,仔细评估后发现斗鱼的场景不能发挥他的优势。最近Kylin重大版本之后,准备再评估一次。这方面应该有不少同学都有相关的经验,最后讨论阶段,大家可以一起聊一下。
可能对大数据组件不太熟悉的同学,可能对OLAP概念不太熟悉,主要是针对秒级大数据量查询场景。对应的OLTP 是针对事务处理,我们比较常见的MySQL和Oracle属于这类。这样解释大家可能接受起来会简单一些。使用Impala作为SQL查询引擎,相比Hive整体提升5倍速度;使用了完全区别于MapReduce的一套数据处理模式。
我们主要做了一点:由于Impala是C++编写,为了提升性能,将部分高查询密度的UDF(如:JSON解析)替换为C++实现。使用HAProxy作为Impala负载均衡器,均衡JDBC连接。避免 Impala Daemon 故障、重启时影响正常业务。这样,可以覆盖我们现在大部分的秒级大数据量查询(10亿级别)。
Spark应用
Spark在斗鱼大数据生态系统有着举足轻重的作用。涉及到:
接入实时流(7*24h) 各个场景的实时PV、UV统计,实时日志分析,服务接口性能监控,用户分布及其他报表等。已上线独立实时任务20余个。
数据抽取与处理 抽取异构数据源(MySQL,MongoDB),将其抽取数据合并、加工后写入数据仓库。每日凌晨触发数据抽取加工任务。为最重要依赖调度任务,为后续每日离线任务准备数据。
数据分析/挖掘 包含弹幕统计分析,流量渠道统计分析,垃圾弹幕识别,用户点击预测,用户分群,推荐系统等任务。这也是部门今年非常重视的一块,任务规模也在日益庞大。
部署:Spark on Yarn ,单节点部署,依赖Yarn环境。
发布:基于自研发布系统,可配置一键部署。
调度:基于自研发布系统,定时调度与依赖调度两种模式可选。
告警:监控与告警系统支持任务执行监控及其结果校验监控。
由于正在经历Spark大版本升级(1.6.x-2.1.x)进程之中 ,斗鱼数据平台部线上存在两个Spark集群来支撑目前的业务。
1.6.3版本Spark基于线上yarn进行部署(Spark on Yarn): 66个节点 72G 内存/节点 22个核/节点。
2.1.0版本Spark基于Standalone: 12个节点 72G 内存/节点 22个核/节点。
Spark生态中,我们主要用到的两个组件:
Zeppelin主要提供Spark SQL交互界面查询,数据可视化支持。后续将支持Python、R语言的建模,支持用户Notebook的提交和调度。
Alluxio基于内存的分布式文件系统,它是架构在底层分布式文件系统和上层分布式计算框架之间的一个中间件,主要职责是以文件形式在内存或其它存储设施中提供数据的存取服务。
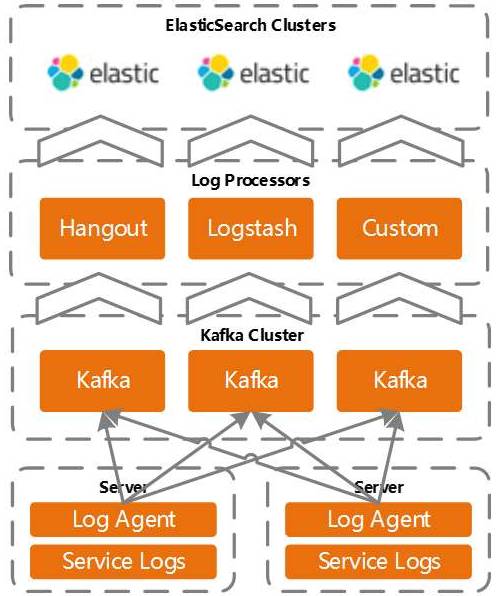
基于ELK的统一日志监控系统
现在我们把es集群按业务场景划分为多个小集群,这样的可以避免不同业务出现抢占资源的情况。
多个ES集群,50+物理节点、每日15T+日志量,多实例部署,接入全站所有服务器日志;年后,完成全部升级至ElasticSearch 5.X,性能提升明显;废弃FlumeAgent,使用Firebeat、Rsyslog,小巧稳定、资源占用低;为部分业务独立开发日志解析器,提高性能,有Java版和Spark版;我们应用ELK的场景中,最难的就是在agent 资源占用和 agent抽取吞吐之间做权衡,想马儿快,又想马儿不吃草,会针对不同的语言栈,使用不同的agent是实现。
推荐日志使用JSON格式,降低解析压力、增减字段灵活;我们agent会把日志灌入kafka,然后从kafka出口的日志流就需要稳定、格式化的结构往ES集群小batch灌,这样就出现了使用hangout和自研数据管道两种实现方式,hangout是java版的Logstash,效率仍然满足不了我们的要求,所以,有了基于spark 的自研日志消费管道。
对ELK的使用,算是踩坑无数。讲一些ES主要优化点:
索引按小时切分,当索引无数据写入时进行ForceMerge提升查询性能。
由于日志收集写请求远远大于读请求,保证每个节点有分片分摊写压力(每个节点1~2个分片),节点磁盘独立。
每台服务器(128G内存),1Master+2Data,预留大约一半内存作为System Cache提升查询性能;记住,一定要留足cache 。
cluster.routing.allocation.same_shard.host 禁止主从分片被分到同一台服务器上(不同节点),保证服务器宕机时索引可用。
ELK的整体优化思路是为了能抗住低延迟和大日志量的问题;现在我们已经能稳定在每日15T+日志量级,基于这一套统一日志监控系统,做了很多业务、服务的监控和告警。
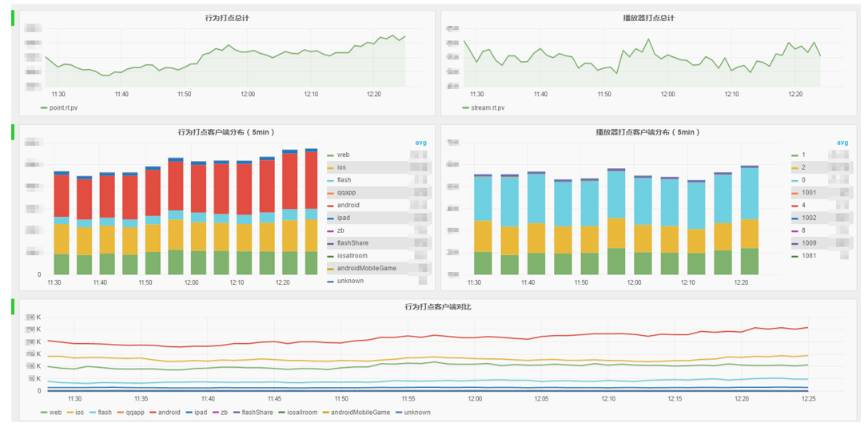
我们现在吞吐量最大的实时数据流,100w+TPS,全站各个端所有用户行为的实时监控,可以实时看到整体打点水位、各个客户端、各个版本播放器的健康状况。
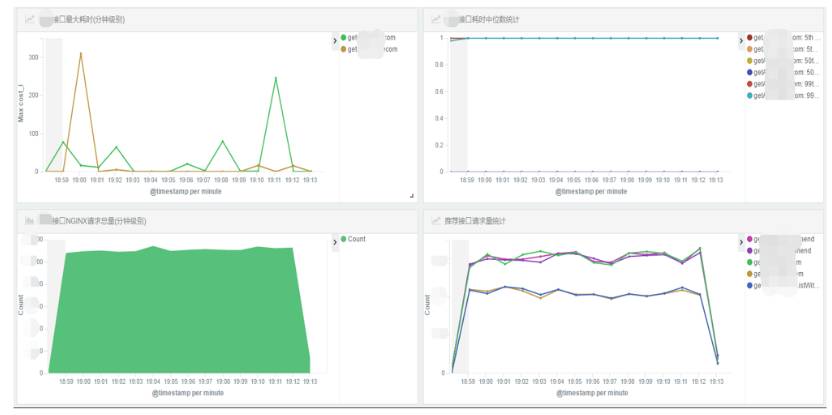
这是推荐接口的实时Dashboard监控效果图:左上是每次请求的最大耗时、右上50分位和99分位耗时统计;左下是推荐接口的整体水位统计、右下是各个Tomcat实例的水位统计;这样可以对实时推荐接口的整体访问量、每个实例的请求量、性能水位、超时请求一目了然,监控神器。基于此可以做阀值的监控,解放双手。
现在每个核心接口分给不同同学来负责,人手配置一个类似的Dashboard。加上告警,就可以腾出手来了。
微服务应用
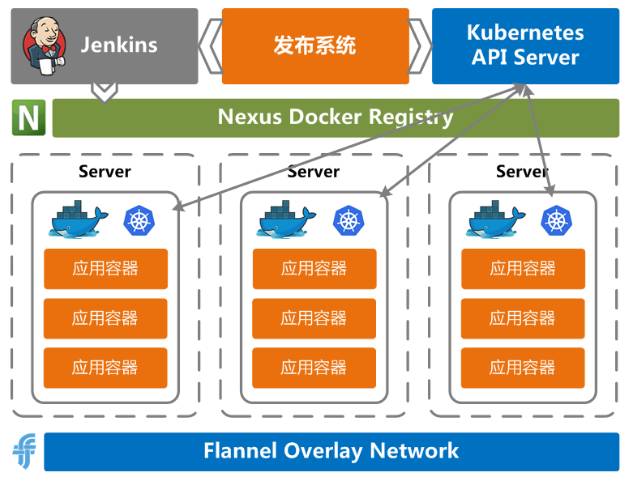
再分享最前面有一个大的架构图,最上层是数据应用层,我们会对外提供多种服务,包括个性推荐、实时监控、广告系统、风控系统、搜索引擎(基于ES)、后台数据应用等服务都是由我们自己来完成整个服务的部署,用以对外提供访问;这样,除了数据层面的处理,也对我们工程实现上提出了高要求,要能直接提供对外服务。我们现在的玩法是基于Docker+Kubernetes容器生态构建完备的微服务体系来实现,直接上图。
前后端完全分离,使用Nginx作为网关,代理后端服务。功能较单一,正在预研其他网关方案;全面升级至SpringBoot,拥抱微服务。
使用内嵌的Web容器(Tomcat、Jetty、Undertow),由应用自己掌控整个生命周期,形成闭环;
容器化改造更平滑,提高应用弹性(方便统一底层系统环境、方便扩缩容);
内置的Metrics 接口使应用监控更方便。
这样,就讲到斗鱼服务容器化:
使用K8S作为容器编排引擎,进行容器调度、运行、滚动升级、灰度发布;
暴露服务状态接口(isReady,isHeahthy),更好的利用K8S探针进行自我健康检查;
容器网络使用Flannel(VxLan模式);
使用Nginx作为网关代理外部请求(非容器网络内的请求);
进行容器化改造的过程中,对于需要暴露接口的服务,初期可以将服务容器网络设置为宿主机网络,避免接口无法访问的问题(尤其是在服务发现场景,注册的是容器IP,外部无法访问),后期进行宿主机端口感知、注册。
主要挑了核心组件来做简单分享,抛个砖;当然为了支撑Devops开发模式(每位同学从需求分析开始,一直负责设计、开发、测试、发布、运维、告警、优化等服务全周期),需要有配套的任务调度系统(基于ZK自研)、发布系统(基于Jenkins自研)、监控系统(自研)等系统限于篇幅不做展开。
斗鱼数据仓库最开始就是一个Hive default库,导入的表是Nginx/PHP log。慢慢需要对注册用户进行统计分析,逐渐导入了注册表、礼物流水、充值表等等关系表。逐渐增加到近200张表粗放的放在default库,碰到权限、误删除等问题后,数据仓库分层刻不容缓。
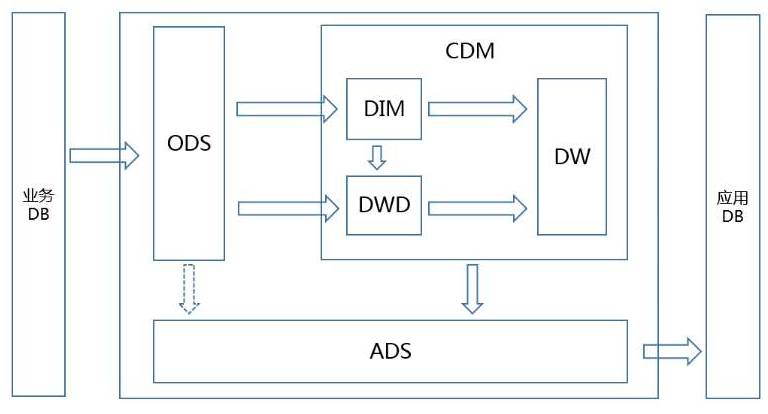
斗鱼数据仓库分层主要分为以下几层:ods:ods层主要用来存储从业务数据库表,如MySQL,MongoDB同步过来的原始数据,以及线上用户行为等原始数据external:external层主要用来存放线上写到HBase数据建立的外部表,以及日志数据的外部表dim:dim层主要用来存放维度表信息,如直播间维度信息等dwd:dwd层主要用来存放从ods层以及dim,external处理清洗过后的数据,方便接下来的计算dw:dw层主要用来对用户或主播等进行一些轻维度的汇总ads:ads层主要是应用层的一些数据,如对外的报表数据archive:archive层主要是归档历史数据。
数据仓库中还会根据业务以及数据类型做域的划分:
业务域:ad-广告
game-游戏数据域: log-日志域,pay-交易域
斗鱼数据仓库规范实施数据仓库基本的建设完成后,就会有一些用户操作数据的规范,如:SQL规范,数据时间周期的规范SQL规范主要有以下几个方面类型统一:double,string,bigint数据倾斜:group,count distinct,开窗函数表级&字段级注释条件语句类型必须一致case when语句必须要有else表查询带上库名称。
开始同步数据时使用了开源的sqoop作为同步工具,由于对多数据源的支持不够丰富以及对内部系统的兼容性问题,逐渐放弃使用。
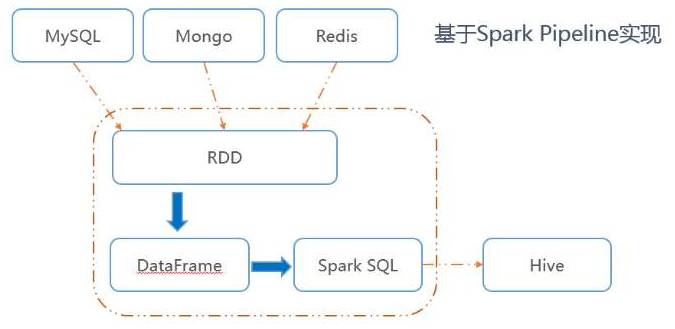
自研了Data-Porter工具作为目前主要的多种数据源与数据仓库间的同步工具。Data-Porter基于Spark Pipeline,将数据从DB读取为Spark RDD,再转为Spark DateFrame,最后使用Spark SQL将数据写入Hive,这种通过API由低阶到高阶的应用,实现了无附加操作的数据同步 。
目前支持MySQL的数据库分库分表的同步,MongoDB集群同步以及数据源去重,但是也有一些不足的地方,比如对数据源目前还只支持了MySQL和MongoDB,后续会规划开发关于HBase等目前主要使用的数据源的同步支持。
先看看斗鱼个性推荐的主要栏目位:
App首页几乎都是个性推荐的栏目位,每个用户看到的都是依据自己口味推荐的直播间,千人千面。
直播列表中有特定的两个位置。
直播间页面中,有“超管推荐”,每个直播间看到的都不一样,百人百面。
其中App首页是完全千人千面,不同的分区、不同的房间,都是根据用户历史行为,预测的用户偏好进行推荐。可以看下斗鱼个性推荐的场景,很多,而且会越来越多。是公司的总体战略目标。
斗鱼个性推荐是从15年开始预研,线下做推荐方案对比、模型效果对比、实际数据试跑,到16年6月份才正式上线。从Web端的列表、直播间内的推荐位,同步APP端上线。现在APP首页大部分都是个性推荐位,做到千人千面的实时推荐。
个性推荐的算法模型选择是一方面,推荐服务本身工程实现的性能也是很大的考验,要支持500w的用户同时在线量,接口处理请求峰值近1w +QPS。得益于服务化,核心功能都配备完备的监控告警。正在上线的Docker容器化,可以大大提升服务的弹性,方便服务规模的扩缩。
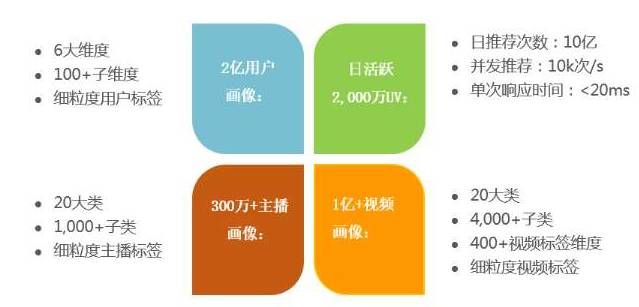
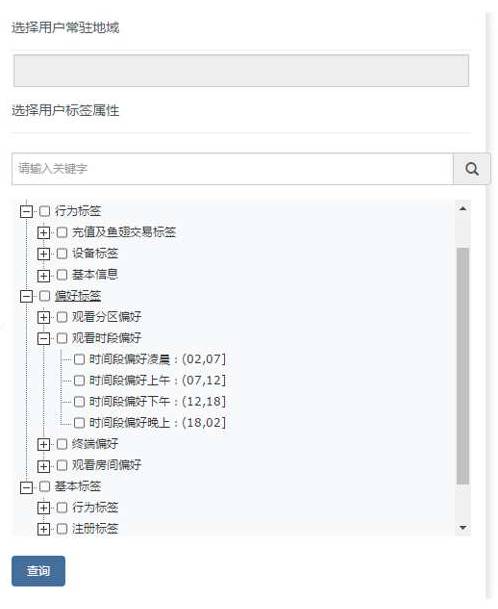
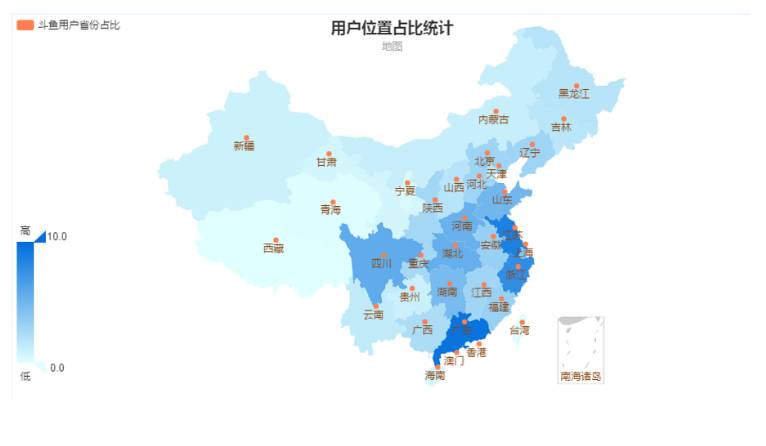
个性推荐的效果好坏拼的就是用户画像,对自己用户越熟悉,推荐效果才可能越好;斗鱼的用户画像现在是这么玩的:
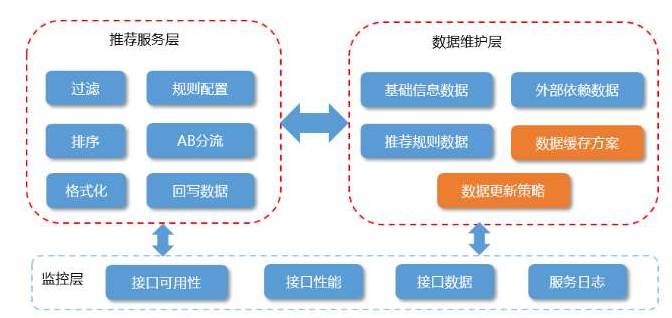
从上面的图可以看到,目前我们的推荐系统主要分为三个模块:推荐服务层、数据维护层、监控层。
推荐服务层推荐业务规则过滤,根据业务需求过滤不需要推荐的数据推荐算法配置,根据业务场景及推荐位配置不同的推荐算法ABTest分流,用于推荐算法对比及灰度上线结果数据格式化及排序。
数据维护层基础信息数据使用dubbo提供服务,降低服务层对数据源的依赖基于物品相似、用户标签、KPI体系等算法,离线计算与实时计算相结合推荐算法数据存储,基于不同算法数据分开存储维护数据缓存策略,提升缓存命中率,降低DB请求。
监控层接口可用性监控、接口性能监控数据质量监控,保证数据准确性推荐效果监控,实时关注推荐转化率。
个性推荐无法速成,斗鱼个性推荐当前也有不少问题:
推荐规则单一,点击转化率约5成,仍有提升空间。
推荐服务开发效率及扩展性不高。
推荐数据分散,复用率低。
这个图片有一个很励志的故事,是这样的:20平米房间,2万张卡,前期投入约40万,一天换一次,一个月内所有的卡都跑一圈。每月收入30万,高峰月入百万。工作室的日常:每天晚上将卡一张张取下来,更换新卡。这是黑产的一个缩影。
那斗鱼面对的黑产风险有:
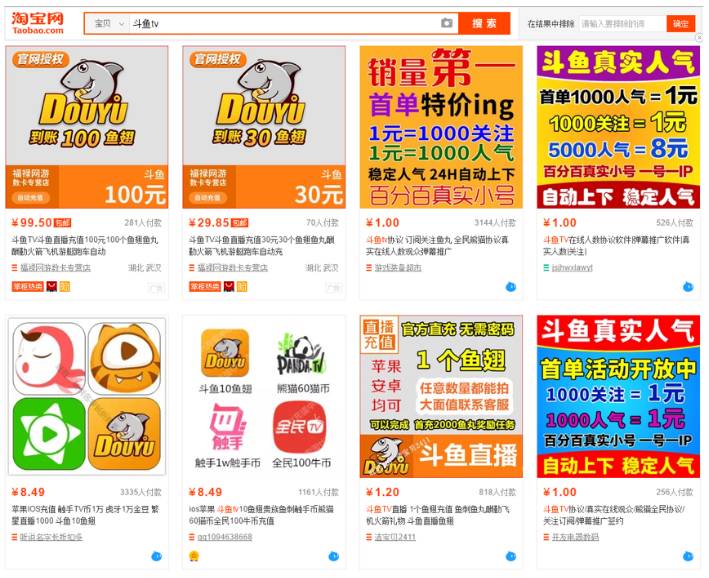
这是前天我从淘宝上搜索斗鱼tv时的结果截图,可以作为现在斗鱼面对黑产形势的一个典型缩影。
主要集中在直播间人气(主播价值的一个衡量依据)、鱼丸(主播可兑换的礼物)、打折鱼翅(黑卡充值—重灾区,主播可以兑换,危害更大更直接)、主播刷关注,可以从淘宝价格上一瞥黑市上各个刷量的难易和获益程度。同时,在搜索结果中,也能看到斗鱼友台出现在搜索结果中,可见,黑产风险是整个行业要面对的,不仅仅是斗鱼。在这一块,是需要行业内的整体合作的,尽管这个合作有些障碍。
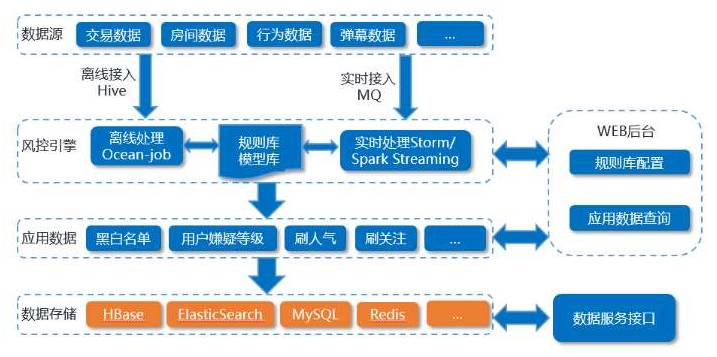
斗鱼风控系统是这样的:
大力惩治的同时,要保证用户体验,尽量降低误杀。
依据用户行为数据获取特征模型,提取作弊行为的特征模型。
针对IP和设备画像,对IP和设备进行嫌疑级别评级打分。
采用线上实时+离线分析 双层识别模型为主,辅以“基于规则-rule-based”判断。
提取用户行为风险模型、用户风险评分等级。
对照上图,挨个注释一下:
建设决策中心(Drools),识别各种作弊行为, 优化反作弊算法模型。风控实时引擎, 以实时弹幕、异地登录等关键行为实时流为基础,在结合账号防盗及充值消费数据,实时评估用户风险等级。
用户行为轨迹分析系统,协助分析用户作弊行为,提炼风控规则。风控离线引擎, 不定期更新离线风控规则,接入决策中心,统一配置。
风控web管理平台,用于配置决策规则、黑白名单管理、行为轨迹查询等功能。风控数据服务化,对外提供安全访问的接口,实时查询用户风险行为,降低损失。
总结
我们有很多数据;围绕数据我们做了很多努力;要让数据发挥更大的价值。
吴瑞诚,目前负责斗鱼数据平台部。11年华科通信硕士毕业后加入淘宝,主要做HBase相关开发,后来在1号店转向应用架构方向。14年9月加入斗鱼,从0开始搭建斗鱼大数据平台,现在的数据平台部团队规模接近60人。
长按识别二维码享更多精彩




