MixPath:基于权重共享的神经网络搜索统一方法

©PaperWeekly 原创 · 作者|陆顺
学校|中科院计算所硕士
研究方向|神经网络架构搜索

论文标题:MixPath: A Unified Approach for One-Shot Neural Architecture Search
论文链接:https://arxiv.org/abs/2001.05887
代码链接:https://github.com/xiaomi-automl/MixPath

本方法拓展了现有神经网络搜索中的权重共享(One-Shot)路线,打破了只能搜单路径模型的限制,支持多路径搜索空间。方法采用多路径激活训练一个超网(supernet)的方式,从而对多路径子网进行性能评估,已有的单路径方法 SPOS、FairNAS 因此成为该方法的特例。
本文证明了多路径超网在多路激活下的特征幅度关系,推测其可能导致了多路径超网训练不稳定性。基于此,本文提出使用影子批正则化(Shadow BN, SBN)来对多路径激活的特征进行“如影随形”的正则化,实验证明其能够有效缓解训练不稳定性。
本文进一步用实验证明 Shadow BN 可以提高多路径超网对多路径子网的排序能力(ranking),而且作用于训练过程的 Shadow BN 可以与训练后的 BN 校准相结合,能够进一步提升超网的排序能力,在 NAS-Bench-101 子集上达到的 Kendall Tau 值为 0.597。

研究动机
在分两阶段的权重共享方法中,训练超网是为了保证其对子模型的排序能力,即能够分辨子模型的优劣。
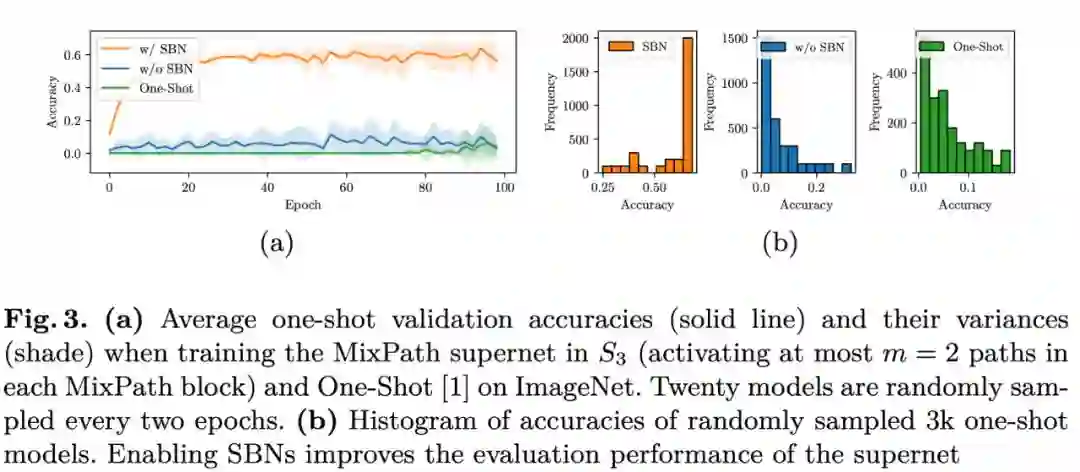
使用传统的单个 BN 训练多路径超网,训练过程并不稳定,模型排序能力也比较弱(Fig.3.b 蓝绿两种方法预测出的准确率区间在 0-0.2),因而需要一种方法能够提高多路径超网的训练稳定性和排序能力。

方法
通过分析 Supernet 训练过程中特征图的相似度及模长(Fig.4),作者推测使用 Shadow BN 来跟踪不同路径组合情况时的特征分布,使得多次激活之间特征变化不至于相差过大,尽然改善超网的训练过程。
本文提出的采用 Shadow BN 的多路径搜索方式如 Fig1 所示。作者采用了 MobilenetV2 的结构块(block),每个 block 中可以选择 depthwise conv 的数量以及卷积核的大小。
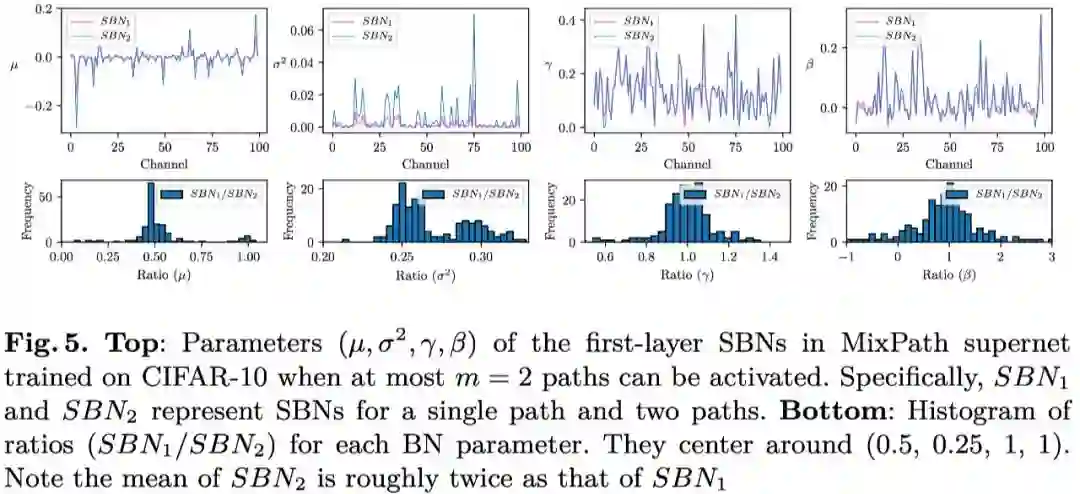
下图中间为 m=2 的示意图,即可选一条或两条路径,若选择一条路径则对应 SBN1(所有的单路径都经过 SBN1),若选择两条路径则可从 4 种操作中不重复地选择两种,输出叠加后,此时对应 SBN2(所有的双路径对应 SBN2)。
同理若 m=3 或者 m=4,则最多可选 3 条或 4 条路径,分别对应 SBN3 和 SBN4。


本文通过实验对上述证明进行了验证,如 Fig.5 所示,SBN2 学到的均值大约是 SBN1 的两倍,方差大约是 SBN1 的四倍,可以看出是基本符合上述推导的。
不同数量组合操作的输出,他们之间的均值和方差确实发生了变化,因此使用单个 BN 无法对呈多种分布的特征进行正则化。
同时由于相同数量不同组合操作的输出仍满足相似性,例如 y+z 和 u+v ,只需对应一个BN 即可,否则 BN 的数量会指数型增长,反而不利于训练。


实验
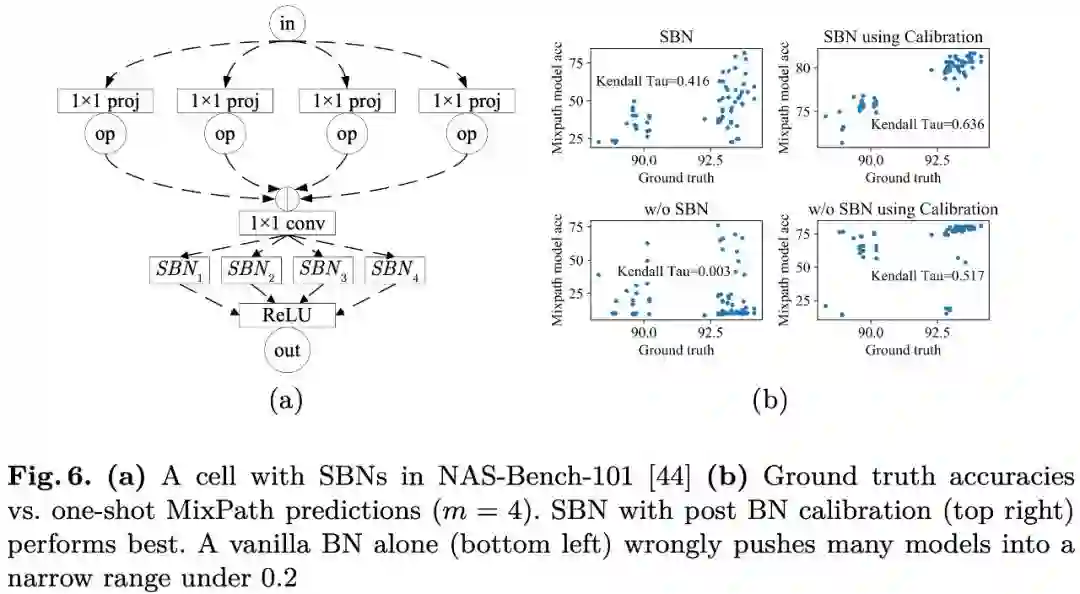
使用本文的方法在 NAS-Bench-101 的子集(以适应 MixPath 搜索空间)上进行验证,测试 ranking 如 Fig 6b,可见 SBN 和 BN 校准操作并用可以最大限度提升超网的排序能力:

使用本文方法在 CIFAR-10 进行搜索,将所得模型单独训练后进行对比;同时将 ImageNet 上搜索所得模型迁移到 CIFAR-10,top-1 准确率达到了 98.1%。
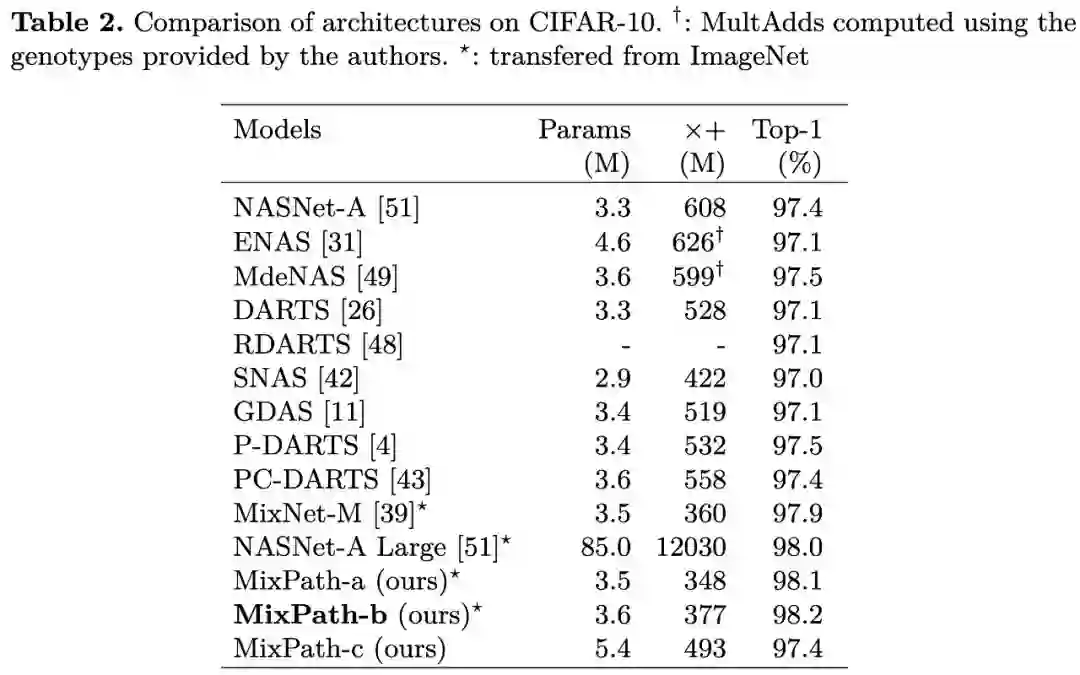
使用本文方法在 ImageNet 进行搜索,将所得模型单独训练后的对比,其中 MixPath-B 准确率最高可达 77.2%:
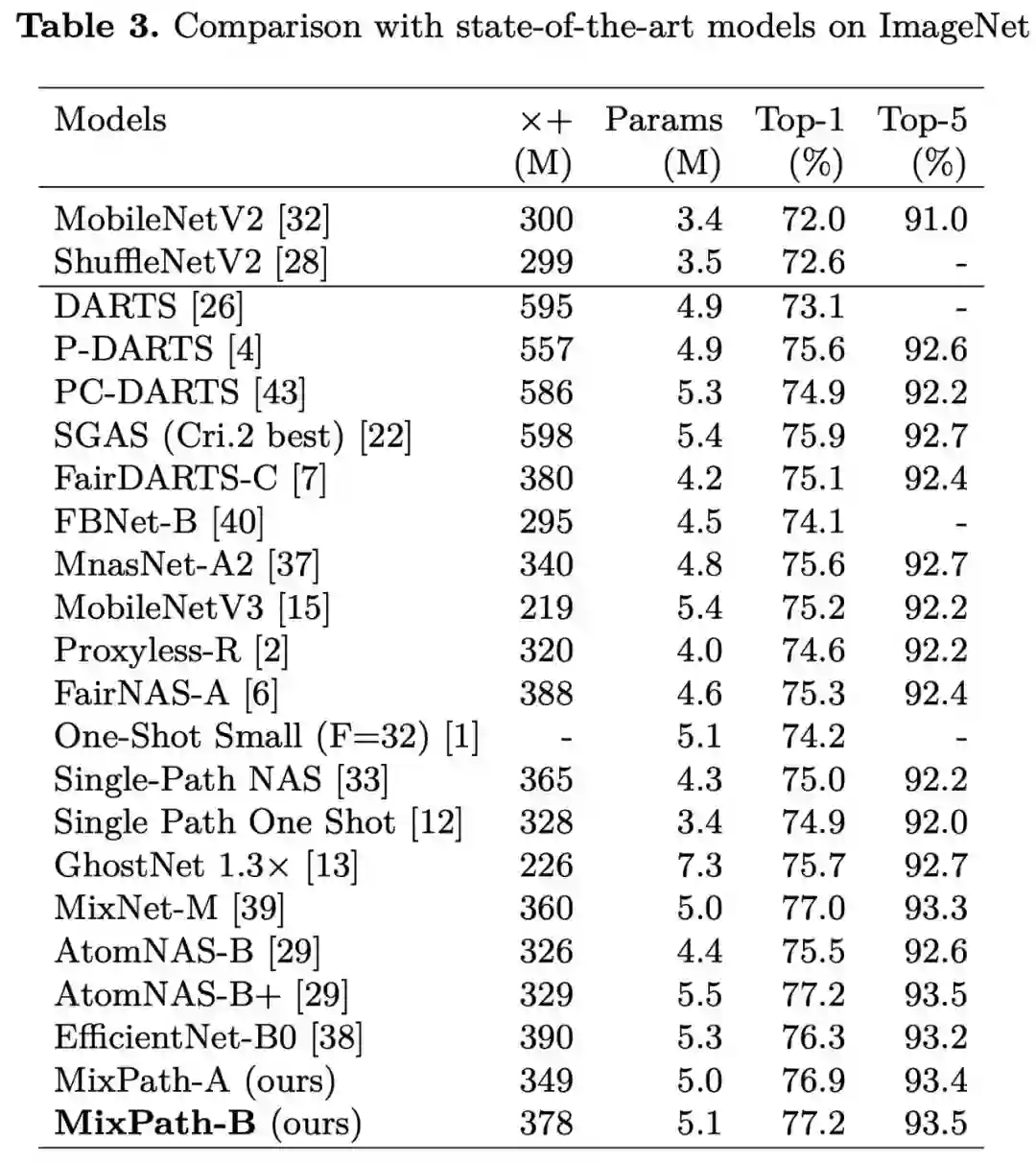
搜索所得多路径模型的结构示意图如 Fig 7:
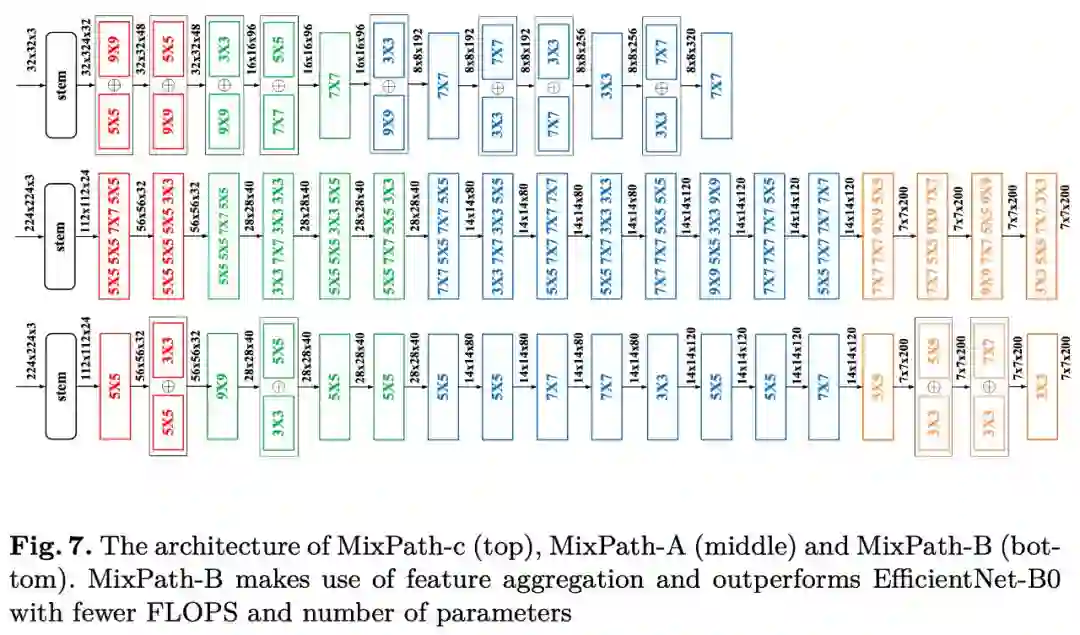
使用本文方法搜索所得模型迁移到目标检测任务上的对比:

消融实验
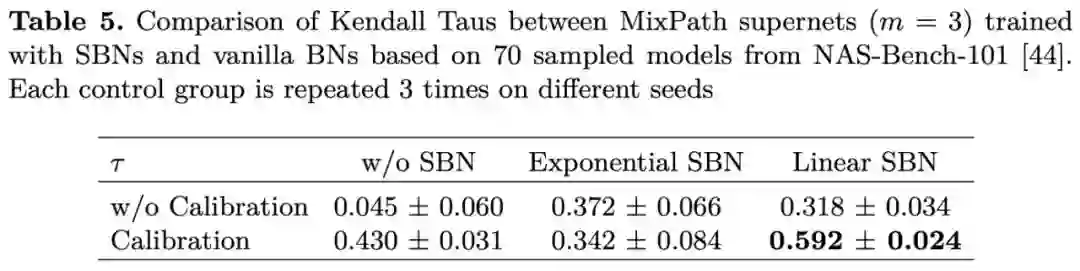
用 SBN 训练的 Supernet 采样子模型比不用 SBN 的分布更好,随机采样 1000 个模型的预测准确率分布(激活 m=1,2,3,4个路径):
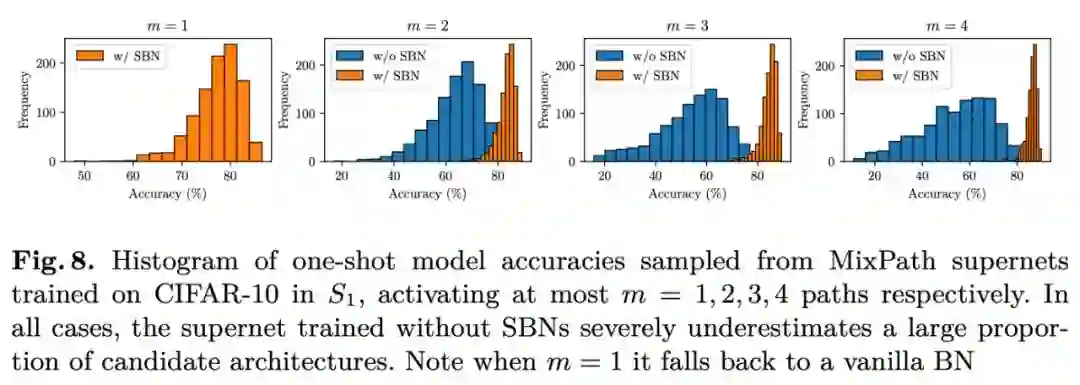
使用 NSGA-II 搜索策略和随机搜索策略的对比:

思考
为什么使用 SBN 能够稳定训练同时提升排序能力:余弦相似度并不是训练稳定的唯一条件,还需要保证特征分布的一致性,使用 SBN 能够对多路径下的特征分布进行正则化,从而促进稳定训练。
当训练稳定后,各个子网络能获得更合适的权重,从而能够更好地代表单模型的真实精度。
为什么 SBN 能和后校准 BN 叠加能提升排序能力:根据前述分析可知,不同路径组合的特征均值和方差是并不是完全满足上述推导关系,从 Fig 5 也能看出是大部分满足上述结论。

点击以下标题查看更多往期内容:

让你的论文被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学习心得或技术干货。我们的目的只有一个,让知识真正流动起来。
📝 来稿标准:
• 稿件确系个人原创作品,来稿需注明作者个人信息(姓名+学校/工作单位+学历/职位+研究方向)
• 如果文章并非首发,请在投稿时提醒并附上所有已发布链接
• PaperWeekly 默认每篇文章都是首发,均会添加“原创”标志
📬 投稿邮箱:
• 投稿邮箱:hr@paperweekly.site
• 所有文章配图,请单独在附件中发送
• 请留下即时联系方式(微信或手机),以便我们在编辑发布时和作者沟通
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。





