你真的会拆分代码吗?

你是否将所有 JavaScript 脚本放在一个大文件中,并在所有页面上使用这个文件?如果是这样,你可能需要考虑使用代码拆分!
很多应用程序将所有脚本放在一个文件中,这个文件不仅包含了初始路由相关的代码,还包含了所有路由涉及的交互代码——无论用户是否会访问这些路由!
这种一刀切的方法效率低下。每一秒用在加载、解析和执行未使用代码上的时间都会延长应用程序的 TTI,对用户体验造成影响。在移动设备上,因为处理器较慢或者网络连接延迟比较严重,用户就更能感觉到这一点。下图显示了移动设备与配备了强大的处理器的台式机或笔记本电脑在解析和编译脚本方面所花费的时间对比:
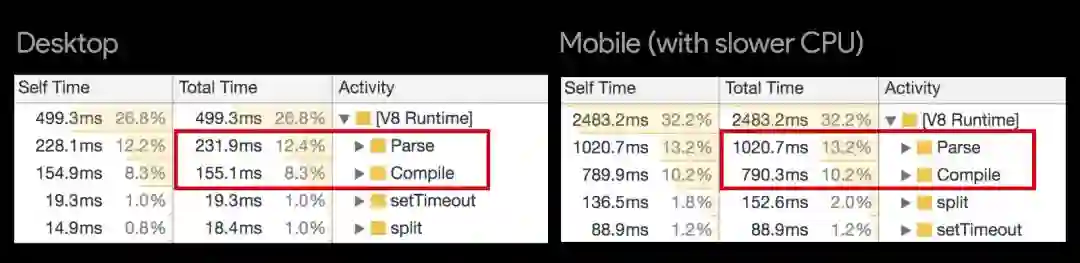
我们都知道,人们更喜欢速度快的应用程序。与一刀切的方法相比,代码拆分只捆绑可以满足当前路由的最少量代码,而不是一次性捆绑所有代码。
“我的应用程序需要进行代码拆分吗”?如果你的应用程序提供了丰富的功能,并且重度使用了框架和第三方库,那么答案几乎就是肯定的。不过,只有你自己才能回答这个问题,因为只有你自己最了解你的应用程序架构及其加载的脚本,以及 Lighthouse、DevTools、真实的设备和 WebPagetest 等工具。
对于新手来说,Lighthouse 更容易上手。在 Chrome 中,你可以在 DevTools 的“Audits”面板中打开 Lighthouse。你需要关注一个与关于 JavaScript 性能有关的审计,就是“JavaScript Bootup Time is Too Hight”,这个审计会标记出显著影响应用程序 TTI 的 JavaScript:
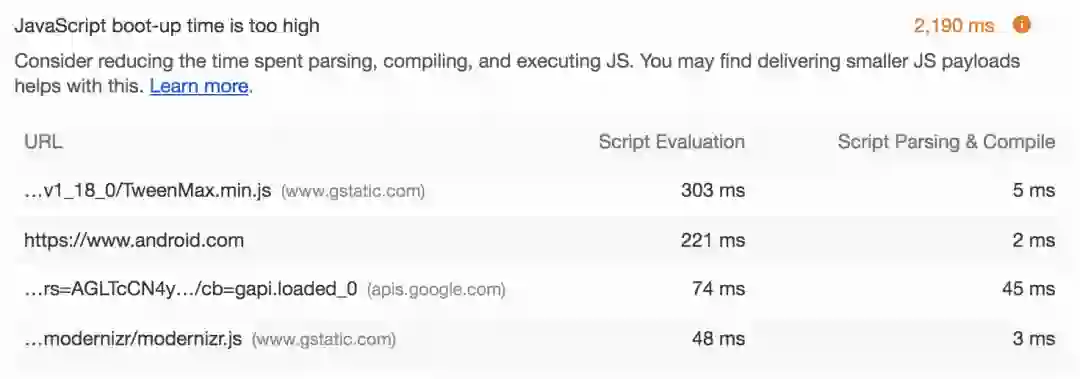
你可以利用这个审计收集的信息和 DevTools 的代码覆盖工具(你可以在 DevTools 中通过 esc 键打开它)一起找出哪些脚本包含当前路由未使用的代码。

需要注意的是,用户设备的功能和处理能力存在很大差异,所以在真实设备上进行测试是至关重要的。你的网站在 iPhone X 上加载很快并不代表在 Galaxy S5 上也会有同样的表现。如果你没有真实的设备可用于测试,至少可以使用 WebPagetest,这样你就可以评估各种平台的性能。
如果认为性能优化是一次性的任务,那么你的性能改进最终会被抵消掉,因为新功能和技术债务的增加将消除你所获得的收益。性能预算可帮助你巩固收益,并防止在添加新功能时对应用程序性能造成破坏。
性能预算为企业引入了一种问责文化,业务利益相关者将会权衡每个变更对以用户为中心的指标的影响。性能预算鼓励团队认真思考他们从设计阶段早期到里程碑结束所做出的决策会产生哪些后果。
团队在制定性能预算时,他们需要了解哪些指标对于用户来说是最重要的。如果你希望在中低端设备上也能快速运行应用程序,那么发送 5MB 的 JavaScript 到客户端就不是一个明智之举。
Alex Russell 在“Can You Afford It?”(https://infrequently.org/2017/10/can-you-afford-it-real-world-web-performance-budgets/)一文中概述的性能预算目标是这样的:
在 3G 网络或模拟(或真实)Moto G4 网络中的 TTI 小于 5 秒。
如果是针对移动设备,那么 JavaScript 大小应该小于 200 KB。如果是桌面版,预算应该低于 HTTP Archive(https://httparchive.org/reports/state-of-javascript#bytesJs)的中位数。
其他资源预算可以从总页面预算中扣除。如果页面不能超过 600 KB,那么图像、JS、CSS 等资源的预算需要做出调整。有些资源可以根据需要进行延迟加载,但初始成本应该有明确的预算。
只是纸上谈兵只会给读者留下更多的疑问。所以,本文将通过实际的示例应用程序来介绍几种不同的用于进行代码拆分的方法。
这个示例应用程序是一个可用于搜索吉他踏板的数据库。
这个应用程序有三个路由:
搜索页面(也是默认路由),用户用它搜索吉他踏板。
吉他踏板详细信息页面,在用户点击搜索结果中的链接时会显示这个页面。用户还可以将踏板添加到收藏夹中。
最喜爱的踏板页面,列出了用户最喜爱的踏板。
大多数示例将向你展示如何使用 webpack 进行代码拆分,而动态代码拆分部分则展示了如何使用 Parcel 进行代码拆分。我们首先展示如何通过 webpack 的入口点拆分应用程序的 JavaScript。
入口点是 webpack 分析应用程序依赖关系的起始文件。如果把它比作树,那么它是应用程序的主干,其中资源文件、路由和功能是分支。有些应用程序只有一个入口点,有些则可能有多个入口点。
什么时候可以使用这种方法:你开发的不是单页面应用程序(SPA),或者是一个混合应用程序,其中一些页面不使用客户端路由,但其他页面可能会用到。在这些情况下,可以使用多个入口点拆分代码。
需要注意的事项:如果你的入口点共享了第三方库或模块,那么脚本中可能会出现重复代码。我们稍后会解决这个问题。
我们的示例应用程序中有三个入口点(与之前描述的三个路由相对应),即 index.js、detail.js 和 favorites.js。这些脚本包含了 Preact 组件,用于渲染这些路由的页面。
在 webpack 中,我们可以通过在 entry 配置中指定入口点来拆分代码,如下所示:
module.exports = {
// ...
entry: {
main: path.join(__dirname, "src", "index.js"),
detail: path.join(__dirname, "src", "detail.js"),
favorites: path.join(__dirname, "src", "favorites.js")
},
// ...
};如果有多个入口点,webpack 将它们视为单独的依赖树,也就是说,代码会被自动拆分为块,如下所示:
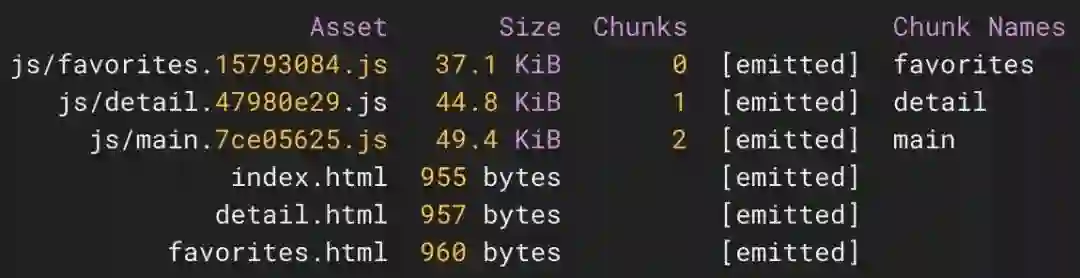
你可能已经猜到了,块的名称来自 entry 配置中的对象键,这样可以很容易识别哪个块包含哪个页面的代码。应用程序还使用 html-webpack-plugin 生成 HTML 文件,其中包含了每个页面对应的块。
虽然我们对每个页面进行了拆分,但仍然存在一个问题:每个块中有很多重复的代码。这是因为 webpack 将每个入口点视为自己的依赖关系树,没有评估它们之间共享的代码。如果我们打开 webpack 中的源映射并使用 Bundle Buddy 或 webpack-bundle-analyzer 等工具分析我们的代码,就可以看到每个块中有多少重复代码。
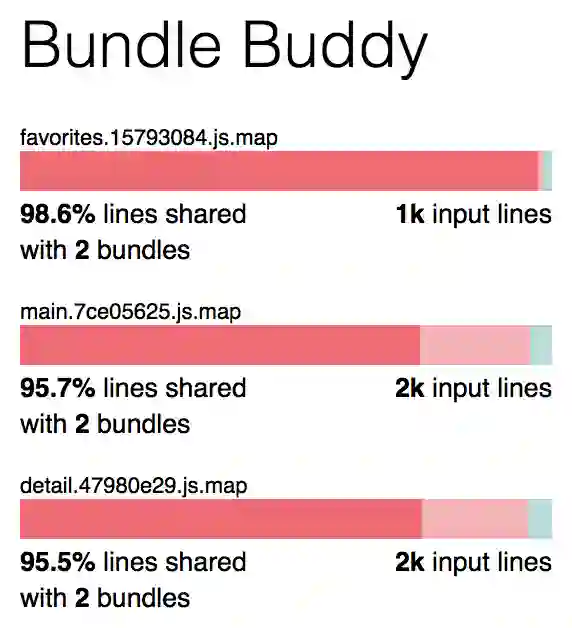
重复的代码主要来自第三方。为了解决这个问题,我们让 webpack 为这些脚本创建一个单独的块。为此,我们将使用 optimization.splitChunks 配置对象:
module.exports = {
// ...
optimization: {
splitChunks: {
cacheGroups: {
// Split vendor code to its own chunk(s)
vendors: {
test: /[\\/]node_modules[\\/]/i,
chunks: "all"
}
}
},
// The runtime should be in its own chunk
runtimeChunk: {
name: "runtime"
}
},
// ...
};这个配置的意思是“我想为每个第三发脚本输出单独的块”(从 node_modules 文件夹加载的那些)。这样做是有效的,因为所有第三方脚本都是通过 npm 安装到 node_modules 目录中的,我们可以使用 test 选项来检查它们。
我们还指定了 runtimeChunk 选项,将 webpack 的运行时移动到自己的块中,避免在应用程序代码中重复出现。在将这些选项添加到配置中并重建应用程序后,从输出中可以看到,应用程序的第三方脚本已经被移到单独的文件中:
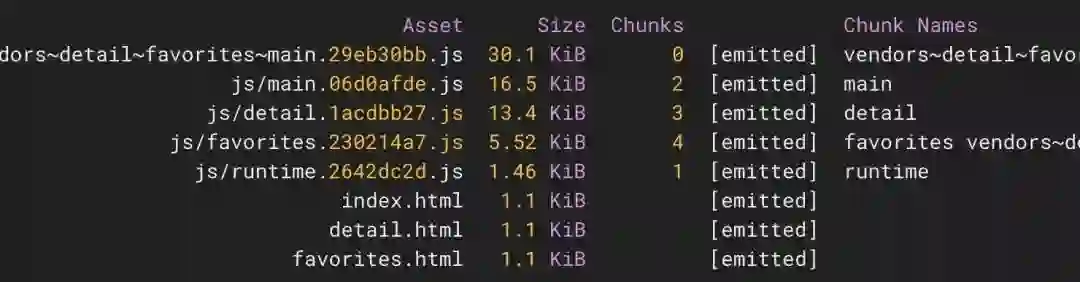
第三方脚本、运行时和共享代码已经被拆分到单独的块中,同时也减小了入口点脚本的大小。现在,Bundle Buddy 显示的结果是这样的:
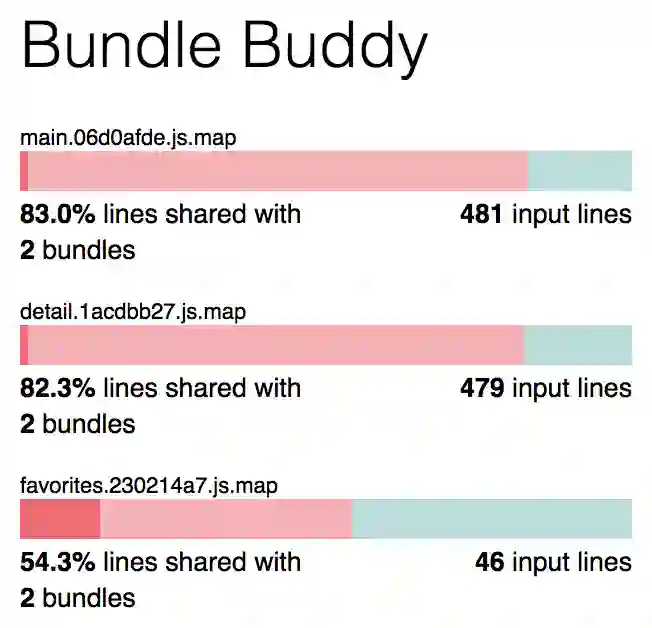
在拆分第三方代码之前,捆绑包之间共享了几千行代码。现在明显少了很多。虽然将第三方代码分成单独的块可能会产生额外的 HTTP 请求,但这个问题只会在使用 HTTP/1 时存在。此外,这样种方式对于缓存来说会更好。如果你有一个巨大的捆绑包,而你的应用程序或第三方代码发生了变化,那么就需要再次下载整个捆绑包。
如果你真的想要更进一步,你可以尝试消除捆绑之间的大部分或全部共享代码,并使用一种称为“公共拆分”的代码拆分方法。在示例应用程序中,可以通过在 cacheGroups 下创建另一个配置来实现,如下所示:
module.exports = {
// ...
optimization: {
splitChunks: {
cacheGroups: {
// Split vendor code to its own chunk(s)
vendors: {
test: /[\\/]node_modules[\\/]/i,
chunks: "all"
},
// Split code common to all chunks to its own chunk
commons: {
name: "commons", // The name of the chunk containing all common code
chunks: "initial", // TODO: Document
minChunks: 2 // This is the number of modules
}
}
},
// The runtime should be in its own chunk
runtimeChunk: {
name: "runtime"
}
},
// ...
};当我们使用公共拆分时,块之间共同的代码将被拆分到一个叫作 commons 的块中:
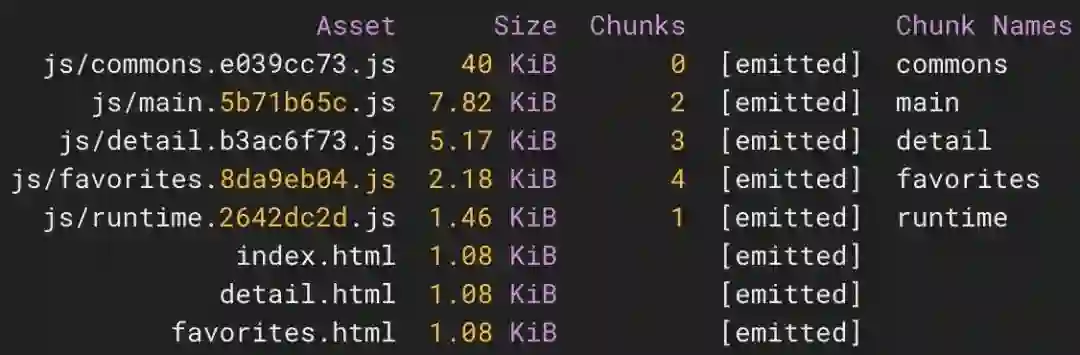
当我们重新运行 Bundle Buddy 时,我们应该会收到一条通知,告知我们的捆绑包中不再有重复的代码块。
尽可能多地移除重复代码是没错,但我们也要注意,使用这个配置拆分代码很可能会因为包含了可能未在当前页面上使用的代码而导致初始捆绑包变大。这个问题可以通过延迟加载脚本来解决,我们将在下面介绍!
如上所示,通过多个入口点进行代码拆分是非常直观的,但它可能不适合你的应用程序。另一种方法是使用动态 import() 语句来延迟加载脚本:
import("./myFancyModule.js").then(module => {
module.default(); // Call a module's default export
module.andAnotherThing(); // Call a module's named export
});import() 将返回一个 Promise,所以也可以使用 async/await:
let module = await import("./myFancyModule.js");
module.default(); // Access a module's default export
module.andAnotherThing(); // Access a module's named export无论你喜欢哪种方法,Parcel 和 webpack 都可以检测到 import(),并对导入的代码进行拆分。
什么时候可以使用这种方法:你正在开发一个单页应用程序,其中包含很多离散的功能,并非所有用户都会用到这些功能。延迟加载功能可以减少 JS 解析和编译活动,以及通过网络发送的代码量。
需要注意的事项:动态导入脚本需要进行网络请求,这意味着用户操作可能会因此被延迟。不过有很多方法可以缓解这种情况,我们稍后会介绍。
我们先来看看 Parcel 的动态代码拆分工作原理。
Parcel 是一个非常直观的动态代码拆分工具。不需要做任何配置,Parcel 就可以为静态和动态模块构建依赖树,并输出脚本,这些脚本的名称与输入可以很好地对应起来。
在这次的示例应用程序中,客户端路由由 preact-router 和 preact-async-route 提供。如果不使用动态导入模块,所有路由所需的组件都必须预先导入(并由客户端下载):
import Router from "preact-router";
import { h, render, Component } from "preact";
import Search from "./components/Search/Search";
import PedalDetail from "./components/PedalDetail/PedalDetail";
import Favorites from "./components/Favorites/Favorites";
render(<Router>
<Search path="/" default/>
<PedalDetail path="/pedal/:id"/>
<Favorites path="/favorites"/>
</Router>, document.getElementById("app"));我们为每个路由加载每个组件,无论用户是否会访问它们。当以这种方式构建应用程序时,我们就错过了通过延迟加载 JavaScript 来提高加载性能的好时机。其实我们可以通过使用动态 import() 和 preact-async-route 来延迟加载 /pedal/:id 和 /favorites 路由所需的组件,如下所示:
import Router from "preact-router";
import AsyncRoute from "preact-async-route";
import { h, render, Component } from "preact";
import Search from "./components/Search/Search";
render(<Router>
<Search path="/" default/>
<AsyncRoute path="/pedal/:id" getComponent={() => import("./components/PedalDetail/PedalDetail").then(module => module.default)}/>
<AsyncRoute path="/favorites" getComponent={() => import("./components/Favorites/Favorites").then(module => module.default)}/>
</Router>, document.getElementById("app"));这里有些东西与之前的例子是不一样的:
1. 我们只是静态导入 Search 组件。这是因为默认路由使用了这个组件,因此需要预先加载它。
2. preact-async-route 通过 AsyncRoute 组件处理异步路由。
3. 当用户浏览到 /pedal/:id 和 /favorites 时,将延迟加载 PedalDetail 和 Favorites 组件。
在重新构建应用程序后,Parcel 输出以下内容:

在零配置的情况下,Parcel 会自动将动态导入的脚本拆分为可以按需延迟加载的块。
当我们访问默认路由时,只会加载必需的脚本。当用户查看踏板详细信息或将踏板添加到收藏夹时,将按需加载相关的脚本。
与 Parcel 一样,webpack 也可以将动态导入脚本拆分为单独的文件。当 webpack 遇到 import() 语句时,它不会像 Parcel 那样命名输出的文件:
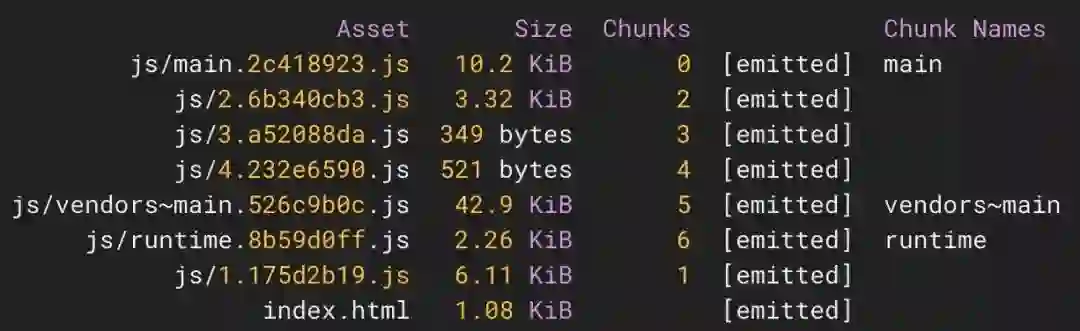
可以看出,webpack 为块分配的是 ID,而不是名称。不过这对用户来说无关紧要,但对于开发来说可能会有点问题。为了解决这个问题,我们需要使用一种称为内联指令的特殊注释让 webpack 输出文件名:
render(<Router>
<Search path="/" default/>
<AsyncRoute path="/pedal/:id" getComponent={() => import(/* webpackChunkName: "PedalDetail" */ "./components/PedalDetail/PedalDetail").then(module => module.default)}/>
<AsyncRoute path="/favorites" getComponent={() => import(/* webpackChunkName: "Favorites" */ "./components/Favorites/Favorites").then(module => module.default)}/>
</Router>, document.getElementById("app"));在上面的代码片段中,一个叫作 webpackChunkName 的内联指令会告诉 webpack 块的名称应该是什么。在 import() 中使用这个指令后,webpack 为块提供了名称,如下所示:
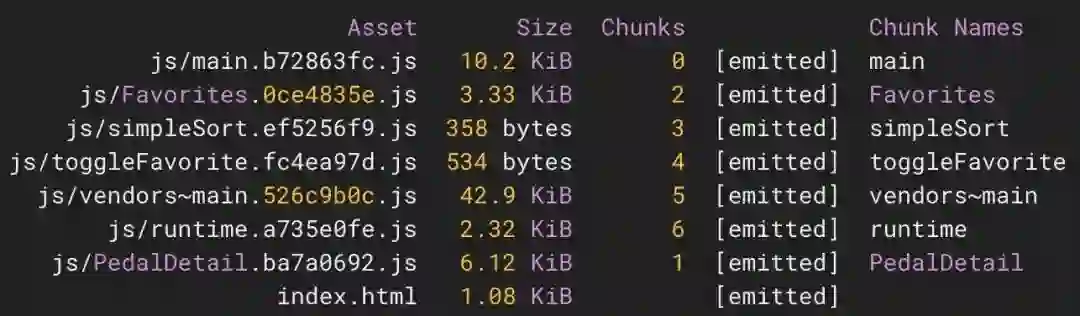
在我看来,这种语法有点笨拙,但它确实有效。如果你想了解示例应用程序如何使用 webpack 进行动态代码拆分,请查看代码库的 webpack-dynamic-splitting 分支(https://github.com/malchata/code-splitting-example/tree/webpack-dynamic-splitting)。
代码拆分的一个潜在痛点是它增加了对脚本的请求量,即使在 HTTP/2 环境中也是如此。下面我们将介绍一些可以提升应用程序加载性能的方法。
在本文的开头,我们讨论了性能预算问题。如果项目使用了 webpack,那么可以在 performance 中配置文件的最大值,如果构建的应用程序超过这个大小就抛出错误,如下所示:
module.exports = {
// ...
performance: {
hints: "error",
maxAssetSize: 102400
}
};这个配置是在告诉 Webpack:“在构建期间如果文件大于 100 KB 就抛出错误”。这当然是一个很严苛的配置,但如果你真的想要遵循预算,performance 对象可以帮助你做到这一点。请务必了解这个对象的其他可用选项,例如 maxEntrypointSize 等。
PRPL 模式(https://developers.google.com/web/fundamentals/performance/prpl-pattern/)中的第二个 P 表示预缓存(precache),涉及在初始化时使用 service worker 预缓存剩余的路由和功能。预缓存给性能带来的好处如下:
它不会影响应用程序初始化加载性能,因为 service worker 注册和后续的预缓存发生在页面加载之后。
使用 service worker 预缓存剩余路由和功能确保在随后发出请求时可以立即使用它们。
当然,由于多种原因(例如输出文件名中带有哈希值),将 service worker 添加到包含使用现代工具生成的代码的应用程序中可能不是很容易。好在 Workbox 提供了一个 webpack 插件,可以轻松地为你的应用程序生成 service worker。
你可以安装 workbox-webpack-plugin(https://www.npmjs.com/package/workbox-webpack-plugin)并将其带入你的 webpack 配置中,如下所示:
const { GenerateSW } = require("workbox-webpack-plugin");你可以在 plugins 配置中添加一个 GenerateSW 实例:
module.exports = {
// ...
plugins: [
// ... other plugins omitted
new GenerateSW()
]
// ...
};Workbox 将生成一个 service worker,可以预先缓解应用程序的所有 JavaScript。对于小型应用程序来说这可能很好,但对于大型应用程序,你可能希望限制可预先缓存的内容。这可以通过插件的白名单选项来实现:
module.exports = {
// ...
plugins: [
new GenerateSW({
chunks: ["main", "Favorites", "PedalDetail", "vendors"]
})
]
// ...
};我们可以借助白名单确保 service worker 只预先缓存我们想要缓存的脚本。想知道示例应用程序是如何使用 Workbox 的,请查看代码的 webpack-dynamic-splitting-precache 分支:
https://github.com/malchata/code-splitting-example/tree/webpack-dynamic-splitting-precache
使用 service worker 预先缓存脚本是提高应用程序加载性能的一种方法,但我们应该将其视为一种渐进式的增强。如果没有进行预缓存,你可能需要考虑进行预取或预加载。
rel = prefetch 和 rel = preload 用于指示在浏览器之前获取指定资源,它们都是通过屏蔽延迟来提高加载性能。乍一看它们非常相似,但它们的表现却截然不同:
rel = prefetch 是对以后要使用的非关键资源的低优先级获取,会在浏览器空闲时启动资源请求。
rel = preload 是对当前路由使用的关键资源的高优先级获取。资源请求可能发生在浏览器发现需要加载它们之前。不过,预加载机制十分微妙,你需要仔细阅读这个指南:
https://developers.google.com/web/fundamentals/performance/resource-prioritization#preload
和相关规范:https://www.w3.org/TR/preload/
如果你确定用户将访问或使用某些路由或功能,那么就可以为它们预取脚本。在我们的示例中,当我们将应用程序 Router 组件挂载到 index.js 的入口点时发生了预取:
render(<Router>
<Search path="/" default/>
<AsyncRoute path="/pedal/:id" getComponent={() => import(/* webpackChunkName: "PedalDetail" */ "./components/PedalDetail/PedalDetail").then(module => module.default)}/>
<AsyncRoute path="/favorites" getComponent={() => import(/* webpackPrefetch: true, webpackChunkName: "Favorites" */ "./components/Favorites/Favorites").then(module => module.default)}/>
</Router>, document.getElementById("app"));我们将 webpackPrefetch 内联指令添加到收藏夹页面的 AsyncRoute 中。如果没有为这个路由执行预取,用户遇到的延迟可能会像下面这样:

在网络连接速度较慢时,用户可能需要等待几秒钟才能收到收藏夹路由脚本。但是,因为使用了 webpackPrefetch,当用户第一次登陆应用程序时,我们可以在空闲时预取脚本,减少用户的等待时间:

通常来说,预取的风险较低,因为它们不会显著地争用带宽,预取具有较低的优先级,只在空闲时进行。也就是说,浪费带宽的可能性还是存在的,因此你需要确保预取的内容都会被用到。
预加载类似于预取,但本质上还是不一样。webpackPreload 内联指令用于预加载,就像 webpackPrefetch 用于预取一样。不过,从我的经验来看,使用 webpackPreload 预加载动态导入的脚本与将给定路由的所有功能捆绑到一个大块中所获得的好处大致相同。
在我看来,预加载用于渲染初始路由的关键脚本最有用。Twitter 通过预加载来加快 Twitter Lite 的加载速度:

可惜的是,webpackPreload 仅适用于动态 import(),因此,为了预加载示例应用程序初始路由比较重要的块,我们需要使用插件 preload-webpack-plugin,在安装了这个插件后,把它带到 webpack 配置中,如下所示:
const PreloadWebpackPlugin = require("preload-webpack-plugin");然后我们在 plugins 数组中添加插件实例以预加载 main 和 vendors 块:
plugins: [
// Other plugins omitted...
new PreloadWebpackPlugin({
rel: "preload",
include: ["main", "vendors"]
})
]这个配置将通过< head>中的元素为 vendors 和 main 块提供预加载提示。

虽然这并没有给示例应用程序带来很大的性能提升,但对于具有大量 JavaScript 和其他资源块的应用程序,加载性能会得到大幅提升,因为这些资源可能会争夺带宽。要想知道示例应用程序是如何进行预加载的,请查看 webpack-dynamic-splitting-preload 分支:
https://github.com/malchata/code-splitting-example/tree/webpack-dynamic-splitting-preload
毫无疑问,进行代码拆分并不容易。更重要的是,你需要花一些时间搞清楚如何在特定的应用程序中进行拆分代码。如果你想要了解更多信息,可以参考以下资源列表:
webpack 代码拆分官方文档:
https://webpack.js.org/guides/code-splitting/
Parcel.js 代码拆分官方文档:
https://parceljs.org/code_splitting.html
React 代码拆分官方文档:
https://reactjs.org/docs/code-splitting.html
Vue 代码拆分官方文档:
https://vuejsdevelopers.com/2017/07/03/vue-js-code-splitting-webpack/
Angular 代码拆分官方文档:
https://angular.io/guide/lazy-loading-ngmodules
动态 import() 指南:
https://developers.google.com/web/updates/2017/11/dynamic-import
不过请放心,代码拆分可以提高应用程序的性能,而且用户会发现你的应用更具吸引力且更易于使用。祝好运!
英文原文:
https://developers.google.com/web/fundamentals/performance/optimizing-javascript/code-splitting/
2019 年 5 月 6-8 日,QCon 与您相约北京国际会议中心,深度解析业界前沿领域及技术趋势。点击 「 阅读原文 」或识别二维码了解 QCon 十周年精心策划,现在购票即享 8 折限时折扣,立减 1760 元,团购还有更多优惠!有任何问题欢迎联系票务小姐姐 Ring:电话 010-53935761,微信 qcon-0410






