基于分布式框架Jepsen的X-Cluster正确性测试
1
概述
AliSQL X-Cluster(简称X-Cluster)是阿里巴巴数据库团队推出的兼容MySQL-5.7,提供数据强一致功能,支持全球部署的分布式数据库集群产品,其分布式核心组件X-Paxos是阿里巴巴数据库团队面向高性能、全球部署以及阿里业务特征等需求,实现高性能分布式强一致的Paxos独立基础库。Paxos算法作为分布式系统的基石,号称是最难理解的算法。Google的论文《Paxos made live》中说了下面一段话:
Paxos从理论到现实世界的实现之间有巨大的鸿沟,在真正实现一个Paxos的时候,往往需要对Paxos的经典理论做一些扩展,尤其是在实现一个高性能的Paxos的时候,扩展点更多,这往往会导致真正的Paxos实现都是基于一个未被证明的协议。
理论证明一个Paxos的实现,比实现这个Paxos还要难。因此一个成熟的Paxos实现很难独立产生,往往需要和一个系统结合在一起,通过一个或者多个系统来验证其可靠性和完备性。我们的愿景是希望提供一个经过实践检验的、高度成熟可靠的独立Paxos基础库。基于X-Paxos构建高可用、强一致、全球部署的分布式数据库集群X-Cluster。因此X-Cluster、X-Paxos的正确性验证就显得尤为重要。
Jepsen是一个开源的分布式一致性验证框架,可用于验证分布式数据库、分布式消息队列、分布式协调系统。Jepsen探索特定故障模式下分布式系统是否满足相应的一致性模型,其作者使用它验证过许多著名的分布式系统(etcd, CockroachDB,MongoDB,Galera,Percona,ZooKeeper ...),号称没有一个能完整的通过其测试。Jepsen作者Kyle Kingsbury的博客展示了其验证过程以及一些思考分析,帮助这些分布式系统发现问题。
我们扩展了Jepsen框架以适应阿里的应用场景,并使用扩展之后的框架验证X-Cluster、X-Paxos的正确性。针对上十种场景和特性,设计了相应的测试用例予以验证,用例涵盖所有Jepsen验证过的分布式数据库系统的场景和特性,另外还设计了新的独有的测试用例,验证过程中周期性的注入分布式环境下的各种错误。验证结果表明,X-Cluster、X-Paxos鲁棒性非常强。
2
X-Cluster、X-Paxos简介
X-Cluster是阿里巴巴数据库团队推出的兼容MySQL-5.7,提供数据强一致功能,支持全球部署的分布式数据库集群产品。说到X-Cluster就不能不提其分布式核心,一致性协议。X-Paxos是阿里巴巴自主研发的一致性协议库,目标是填补市面上高性能、易接入的一致性协议库的空白。市面上已开源的一致性协议实现,都存在或性能不够,或功能上无法满足复杂的现实应用场景需求的问题。 有了X-Paxos,可基于它打造一套强一致的分布式系统,X-Cluster是第一个接入X-Paxos生态的重要产品,利用了X-Paxos实现了自动选主,日志同步,集群内数据强一致,在线集群配置变更等功能。同时X-CLuster基于MySQL生态,兼容最新版本的MySQL-5.7,集成了AliSQL过去的各种功能增强。 MySQL的用户可以零成本迁移到X-Cluster上。
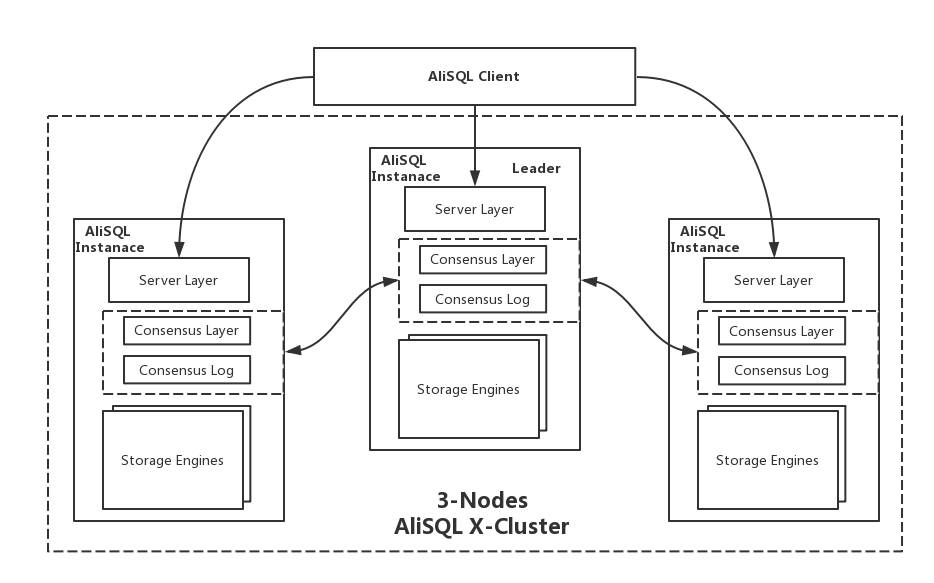
上图展示的是一个部署三个实例的X-Cluster集群。X-Cluster是一个单点写入,多点可读的集群系统。在同一时刻,整个集群中至多会有一个Leader节点来承担数据写入的任务。相比多点写入,单点写入不需要处理数据集冲突的问题,可以达到更好的性能与吞吐率。
X-Cluster 的每个实例都是一个单进程的系统,X-Paxos被深度整合到了数据库内核之中,替换了原有的复制模块。集群节点之间的增量数据同步完全是通过X-Paxos来驱动,如何复制,从哪个点回放不再需要运维人员或者外部工具来介入。 X-Cluster为了追求最高的性能,利用MySQL的Binlog进行深度改造和定制来作为X-Paxos的Consensus日志,实现了一系列的X-Paxos日志接口,赋予X-Paxos直接操纵MySQL日志的能力。
为了保证集群数据的一致性以及全球部署的能力,在事务提交、日志复制回放以及恢复上X-Cluster都进行了重新设计。
3
Jepsen简介
3.1 Jepsen架构
Jepsen是一个开源的分布式一致性验证框架,可用于验证分布式数据库、分布式消息队列、分布式协调系统。Jepsen探索特定故障模式下分布式系统是否满足一致性。Jepsen框架是一个Clojure程序库,Clojure是一门运行在JVM上的解释型的类Lisp语言。Jepsen测试程序是一个Clojure程序,它使用Jepsen框架来构建一个分布式系统,对其执行一系列操作,并验证这些操作的历史记录是否有意义。它还可以生成性能和可用性图,帮助描述系统如何响应不同故障。
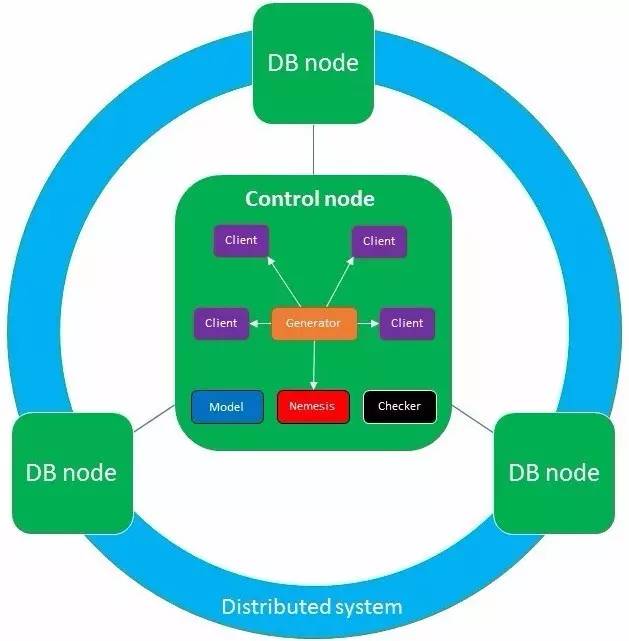
Jepsen测试程序在Control node上运行,使用SSH登录到一些DB node,在其上部署并启动相应的DB进程,DB进程组成待测试的分布式系统。测试开始后,Control node创建一组Client进程,每个Client都有自己的分布式系统客户端。Generator产生每个Client执行的operation,Client进程使用其客户端将operation应用于待测试的分布式系统。每个operation的开始和结束以及操作结果记录在历史记录中。同时,一个特殊的Client进程Nemesis将故障引入系统,其operation也来自Generator。测试结束后,DB将停止并卸载。Checker分析历史记录是否正确,并可生成报告、图表等。Checker在分析时可使用一个定义系统行为的Model。
3.2 Jepsen技术
3.2.1 黑盒系统测试
Jepsen测试真实集群上运行的真实二进制文件,这使得Jepsen测试系统而不用接触其源代码,不需要深入检查网络数据包、形式化系统设计等。Jepsen测试出的Bug 在生产环境中是可观察的,而不是理论上的。Jepsen也牺牲了形式化方法的一些优点,如测试是非确定性的,无法证明正确性,只能发现错误。
3.2.2 分布式环境错误模型
在生产环境中,网络可能分区,时钟可能不同步,节点可能失效,分布式系统应该正确应对这些错误。许多测试框架仅测试正常集群的行为,但生产环境中系统可能面临各种失效模式,Jepsen测试分布式系统在各种错误模型下的行为。
3.2.3 生成式随机测试
Jepsen构造随机的操作,将其应用于系统,包括正常的访问系统操作、错误注入操作。并发的操作结果将记在历史记录中,历史记录将按照事先定义好的模型分析其正确性。生成式的随机测试通常显示边缘的情况与巧妙的输入组合下的结果。
4
X-Cluster、X-Paxos验证
4.1 验证结果
X-Cluster、X-Paxos使用Jepsen验证,用例涵盖所有Jepsen验证过的分布式数据库系统的场景和特性,另外还设计了新的独有的测试用例。已验证的场景和特性如下表所示:
| 场景特性 | 说明 | 验证结果 | 备注 |
|---|---|---|---|
| 事务原子性 | 事务执行是否是原子的 | 通过 | |
| 事务隔离性 | 是否存在脏读、过期读等 | 通过 | Leader上 |
| 丢失更新 | 是否存在丢失更新 | 通过 | |
| 线性一致性 | 读操作是否返回最近的写结果 | 通过 | Leader上 |
| 顺序一致性 | 读到数据的顺序是否与写入的顺序一致 | 通过 | |
| 单调一致性 | 并发的同种操作是否按时间顺序执行 | 通过 | |
| 最终一致性 | 写入的数据是否终会被读到,读到的数据是否是之前写入的 | 通过 | |
| 严格可串行化 | 先提交的事务是否立即对后提交的事务可见 | 通过 | Leader上 |
| 副本一致性 | 数据的多个副本是否一致 | 通过 | |
| Adya | 事务依赖图中有环时是否一致。 如: T1 r(x)、T2 r(y)、 T1 w(y)、 T2 w(x), 则T1、T2最多只能有一个成功 | 通过 |
4.2 错误模型
验证过程中周期性注入分布式环境下的各种错误,过一段时间恢复正常,注入的错误模型如下表所示:
| 错误模型 | 说明 |
|---|---|
| partition-halves | 将网络分为尽量均衡的两个区域 |
| partition-random-halves | 将网络随机分为两个区域 |
| partition-random-node | 随机选一个节点将其与其余节点隔离 |
| partition-majorities-ring | 每个节点只能看到大多数节点,但没有两个节点看到相同的大多数 |
| node-start-stopper | 关闭(kill -9)某些节点上的相应进程,过一会重启 |
| hammer-time | 暂停(SIGSTOP)某些节点上的相应进程,过一会继续(SIGCONT) |
4.3 用例设计
4.3.1 事务原子性
验证事务是否是原子的执行,即事务中的操作要么全部完成,要么全部不完成。
模拟银行系统的转账业务,多个账户之间互相转账,但总的余额保持不变。一次转账事务包含两个操作步骤:转出账户余额减去转账金额,转入账户余额加上转账金额。两个操作必须原子的执行,否则将违反总额不变的不变式。
并发的进行转账操作,同时读取所有账户的余额,将所有账户的余额相加,验证是否与总额一致,若否则违反事务原子性(或者是产生了脏读、过期读,此验证也验证了事务隔离性)。
4.3.2 事务隔离性
验证并发情况下,是否存在脏读(Dirty Read)、过期读(Stale Read)。
如果每次写入的值唯一,则读到的数据具有如下特点:a.失败的写操作写入的值不会被读到; b.发生脏读或过期读时,读到的数据与正确读到的数据值不同。否则违反事务隔离性。
并发批量的将一批记录更新至某个相同的值,保证每次更新的记录值唯一,同时批量读取这批记录,检查读到的记录中,是否存在失败的写操作写入的值,是否出现不相同的值。若是则违反事务隔离性。
4.3.3 丢失更新
验证并发情况下,是否存在丢失更新(Lost Update)。
可将每次更新的值都记录下来,最后读取出来,检查更新记录的完整性,若不完整,则出现丢失更新。
创建一个text类型的字段,每次更新将更新的值拼接到该字段中,最后读出该字段,检查更新记录是否完整。为了增加用例的难度,我们还创建了一个version字段,更新前先读出version,更新时检查version是否已被其它事务覆盖,若否才更新记录并递增version。
4.3.4 线性一致性
验证系统是否满足线性一致性(Linearizability)。
写操作在一个全局时钟体系内立刻对所有客户端进程可见,检查读操作是否返回最近的写操作的结果,若否则不满足线性一致性。
关于线性一致性的测试已有很多研究成果。随机并发的进行read、write、cas(compare and set),记录操作结果以及开始和结束时间,检查是否满足可线性化。例如下图(图片出自Jepsen作者的博客):
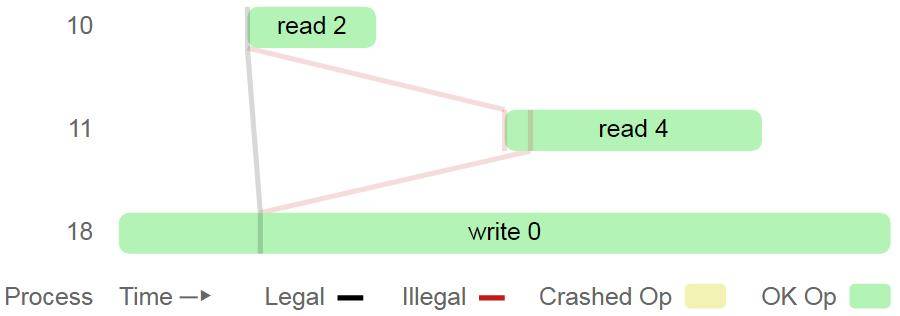
图中显示了三个进程(10,11,18)并发执行读取到2,读取到4和写入0的操作记录。从左到右为时间线,操作方框的左侧表示操作的开始时间,右侧表示结束时间,操作实际生效的时间可能在开始时间和结束时间之间的任意时刻。进程10读取到的值为2,该读取可以在进程18写入0的之前或之后,在进程11执行读取的时间段内,数据的值可能为0或者2,但不管数据的值为0还是2,都不允许进程11读取到4,因此不满足可线性化。
4.3.5 顺序一致性
验证系统是否满足顺序一致性(Sequential Consistency)。
写事务应该以写入的顺序对所有客户端可见,客户端如果读到某次写入的值,则在该写入之前写入的值都应该能被读到。否则违反顺序一致性。
使用一个客户端进程按顺序向不同的表中插入k1, k2, ... , 同时其它客户端进程尝试按照kn, ... , k2, k1的顺序读取,若读取结果不满足此顺序,则违反顺序一致性。
4.3.6 单调一致性
验证系统是否满足单调一致性(Monotonic Consistency)。
并发的插入操作应该按全局时间顺序执行,否则违反单调一致性。
在插入事务中,我们先查询表中最大的值,然后获取时间戳,将表中最大值加一后的值和时间戳插入表中,最后读出表中所有记录,按照时间戳排序,排序后值应该单调递增,否则违反单调一致性。
4.3.7 最终一致性
验证系统是否满足最终一致性(Eventually Consistency)。
所有成功写入的数据最终会被读到,读到的数据一定是之前写入的。否则违反最终一致性。
先不断插入新的记录,最后等待足够长一段时间后读取所有记录。检查所有成功插入的记录是否都被读到,读到的记录是否都是之前写入的。否则违反最终一致一性。
4.3.8 严格可串行化
验证系统是否满足严格可串行化(Strict Serializability) 。
并发情况下,事务是否按照提交顺序可串行化,先提交的事务是否对后提交的事务可见,若否则违反严格可串行化。
并发向多张表中插入记录,同时不断读取所有记录,读到的记录必然不断增加,检查是否有后插入的记录先出现在读到的结果中。若有则违反严格可串行化。
4.3.9 副本一致性
验证系统中同一数据的多个副本是否一致。
比较一条记录的多个副本是否具有相同的值,若否则违反副本一致性。
不断修改记录的值,并增加版本号字段,同时不断从所有副本读取记录,比较同一版本的不同副本上的记录值是否一致,若否则违反副本一致性。
4.3.10 Adya
Adya在其论文中讨论的场景,验证事务依赖图中有环时是否保证数据一致性,如T1 r(x)、T2 r(y)、T1 w(y)、T2 w(x),则T1、T2只能有一个成功。
构造并发的环形依赖的事务,检查事务执行结果,是否违反一致性。
并发向两张表中插入新的记录,插入事务先查询两张表中相应记录是否存在,若都不存在,则一个事务插入到其中一张表,另一个事务插入到另一张表,若记录存在于某张表中,则插入失败。对于一条记录,检查是否只有一个插入事务成功,若两张表都插入成功,则违反一致性。
5
验证总结
基于X-Paxos的X-Cluster是一个单点可写,多点可读的数据库集群,Leader上提供强一致性,Follower上数据落后,提供最终一致性。X-Cluster通过了所有的Jepsen测试,验证了X-Cluster的正确性,也间接的验证了X-Paxos的正确性。
验证过程中也发现X-Cluster和X-Paxos的一些特性可以加以改进:
Follower上数据落后,只提供最终一致性。针对数据强一致性要求的场景,X-Cluster可增加一个配置项,用于配置Follower上是否对外提供读功能,防止应用读到过期的数据。还可考虑实现Follower上的read lease,让Follwer也能提供强一致性读。
Follower被隔离时,仍对外提供读功能。此时并没有违反最终一致性,只是达到最终一致性的时间会延长至Follower重新与Leader连通之后。当Follower发现自己被隔离时,可对外禁止读操作,防止应用读到过老的数据。
只有Leader上提供了查询成员组信息的功能,Follwer上没有。Follwer可增加查询成员组信息的功能,便于应用重定向至Leader。
Paxos是分布式系统的基石,X-Paxos提供了一个经过实践检验的,高度成熟可靠的独立Paxos基础库。基于X-Paxos的X-Cluster实现了高可用、强一致、全球部署的分布式数据库集群。X-Paxos、X-Cluster后续还将不断改进、演化,实现更多的功能,更好的性能。
6
参考
AliSQL X-Cluster:AliSQL X-Cluster 基于X-Paxos的高性能强一致MySQL数据库
X-Paxos:X-Paxos — 阿里巴巴的高性能分布式强一致Paxos独立基础库
Paxos made live: https://research.google.com/archive/paxos_made_live.pdf
Jepsen: https://github.com/jepsen-io/jepsen
Jepsen作者博客: https://aphyr.com/tags/jepsen
Consistency model: https://en.wikipedia.org/wiki/Consistency_model
Clojure: https://clojure.org/
Linearizability: http://cs.brown.edu/~mph/HerlihyW90/p463-herlihy.pdf
Linearizabilty Testing: http://www.cs.ox.ac.uk/people/gavin.lowe/LinearizabiltyTesting/paper.pdf
Sequential Consistency: http://lamport.azurewebsites.net/pubs/multi.pdf
Monotonic Consistency: https://en.wikipedia.org/wiki/Consistency_model#Monotonic_Read_Consistency
Eventual Consistency: https://en.wikipedia.org/wiki/Eventual_consistency
Strict Serializability: http://www.bailis.org/blog/linearizability-versus-serializability/
Adya: http://pmg.csail.mit.edu/papers/adya-phd.pdf
作者:严祥光(祥光),2017年新加入阿里巴巴数据库内核团队,具有多个大型分布式系统研发经验,在分布式计算、分布式存储、分布式一致性、分布式事务,以及C/C++上具有深厚的积累。
如有对Jepsen或者分布式方面感兴趣的,亦可通过知乎@祥光或者微博@严祥光交流探讨。