![]()
![]()
论文标题:
Ekko: A Large-Scale Deep Learning Recommender System with Low-Latency Model Update
收录会议:
OSDI 2022
论文链接:
https://www.usenix.org/system/files/osdi22-sima.pdf
![]()
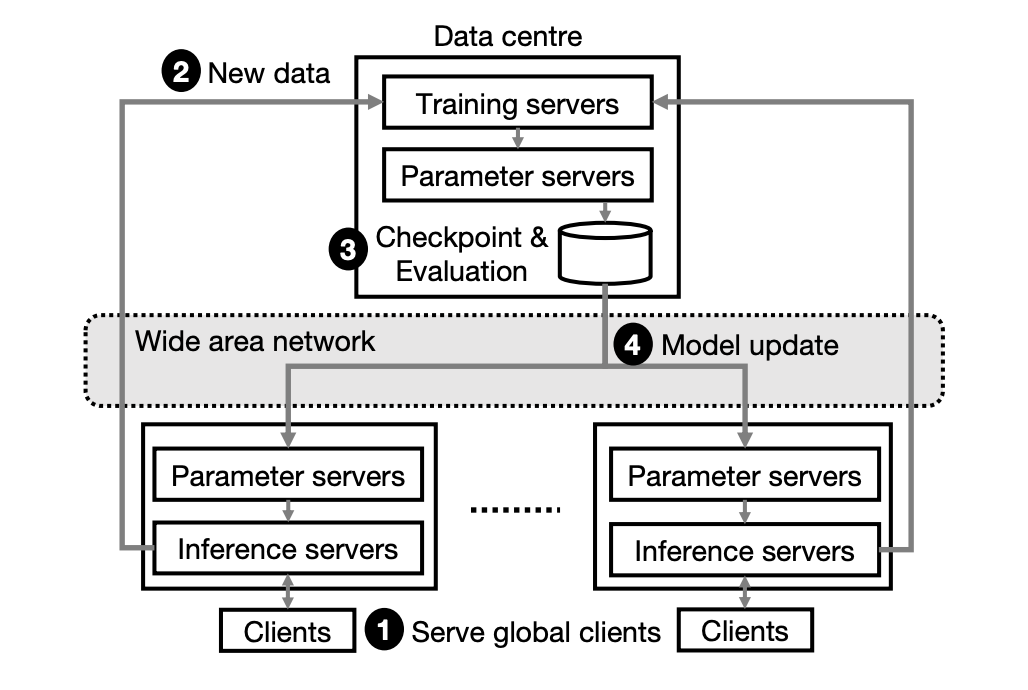
基于深度学习的推荐系统(Deep Learning Recommender System, DLRS)是众多大型技术公司和组织的关键基础设施。一个典型的 DLRS 架构如下图所示,它通常包含了大量参数服务器以支撑众多的机器学习模型,例如嵌入特征表、深度神经网络。这些参数服务器在不同地区的数据中心进行备份,从而和处于全球不同地区的用户进行容错、低延迟的通信。
为了保证对新用户和新内容进行快速服务,DLRS 必须持续地更新机器学习模型。这一过程首先利用训练服务器收集新的训练数据,并计算模型梯度;接着利用广域网将模型更新传播到各个参数服务器的备份模型。
![]()
大规模 DLRS 需要为十亿级别的用户提供服务,因此必须实现关于延迟指标的服务级别目标(Service-Level Objective, SLO),例如将一个新上传内容提供给用户的延迟时间。并且,DLRS 在模型更新方面需要满足一些新的低延迟需求,从而应对以下实际场景中的新因素、最好地实现 SLO:
1. 最近的 DLRS 应用,例如 YouTube、抖音,使用户能够生产海量的短视频、文章、图片内容。这些内容需要在几分钟、甚至几秒内提供给其他用户;
2. 如 GDPR 等数据保护法规允许 DLRS 用户进行匿名,而匿名用户的行为必须进行在线学习;
3. 实际生产中越来越多的机器学习模型,例如强化学习,被用于提升应用的推荐质量。这些模型需要进行持续的在线更新,以达到最佳模型效果。
不幸的是,实现上述低延迟模型更新在现有的 DLRS 中极其困难。现有系统通过离线方法进行模型更新:采集新训练数据后,离线对模型参数计算梯度,验证模型检查点(checkpoint),将模型更新传输到所有数据中心。这样的离线流程需要花费长达数小时进行模型更新。一个替代方法是使用广域网优化的机器学习系统,或联邦学习系统。这些系统使用本地收集的数据更新模型,并 lazy 同步到重复的模型副本中。但 lazy 同步技术不可避免地造成相当程度的异步更新,这通常对系统实现 SLO 造成一定的负面影响。
本文希望探索一种 DLRS 系统设计方案,能够在不降低 SLO 的前提下实现低延迟的模型更新。本文的关键思想是允许训练服务器在线更新模型并立即将模型更新传输到所有模型推理集群。这一设计允许我们绕过离线训练、模型检查、验证、传播等高延迟步骤,从而减少模型更新延迟。
为了实现这一设计,我们需要解决以下几个关键挑战
:1)面对带宽限制、异构网络结构等问题,怎样基于广域网高效地传输模型更新;2)当发生网络拥塞、关键模型更新传输发生延迟时,怎样保证 SLO 的实现;3)怎样处理对模型准确率有害的有偏(biased)模型更新,以保证 SLO 的实现。
![]()
应对上述问题和挑战,本文实现了 Ekko 系统,一个创新的大规模 DLRS,能够全局地更新模型备份并实现低延迟。Ekko 系统设计的主要贡献包括以下两个方面:
1. 高效点对点模型更新传输。
现有参数服务器通常采用 primary-backup replication 数据备份协议进行模型更新。然而当面对海量模型更新,这一协议由于高更新延迟和 leader 瓶颈,出现扩展性不足的问题。为了解决这一问题,我们探索性地进行了点对点模型更新传输。我们针对分布于不同地理位置的 DLRS 设计了一种高效的无日志基于状态的同步算法。由于模型更新常常关注于部分热点参数,因此这一算法能够只传输最近的模型参数版本(即状态)进行有效 DLRS 更新。
Ekko 允许参数服务器高效地通过点对点方式找出模型状态的差别。针对这一点,我们采取了如下设计:模型更新缓存,允许参数服务器高效地追踪并比对模型状态;共享版本,在对比模型状态时显著降低网络带宽开销;广域网优化的传输拓扑,允许参数服务器优先采用带宽宽裕的DC内网路径,而不是采用带宽紧张的 DC 间网络路径。
2. SLO 保护机制。
Ekko 允许模型更新在不进行离线模型验证的情况下到达模型推理集群。这样的设计方案使得一些 SLO 面对网络拥塞和有偏更新十分脆弱,特别是那些和新鲜度以及推荐质量相关的 SLO。应对网络拥塞,我们设计了一种面向 SLO 的模型更新调度算法。这一算法通过计算各类 SLO 相关指标进行调度,包括新鲜度优先级、更新显著性优先级、模型优先级。这些指标用于预测模型更新对 SLO 造成的影响,从而使调度算法能够再现计算各个模型更新的优先级。
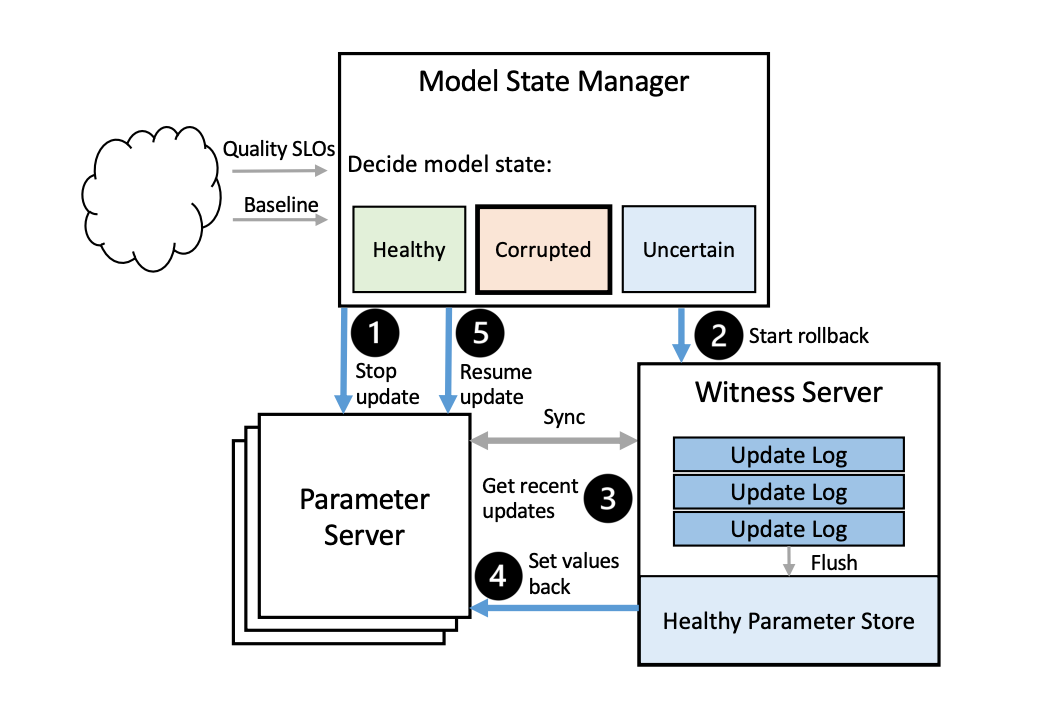
我们在不改变 Ekko 点对点模型更新传输这一分散架构的前提下,将这一调度算法整合到参数服务器中。应对有偏模型更新,Ekko 采用了一种创新的推理模型状态管理算法。管理算法对每组推理模型创建一个基线方法。这一基线方法只接受少量的用户流量,作为推理模型的基准。管理算法持续地监控基线方法和推理模型在关于质量的 SLO 上的表现。当有偏模型更新对推理模型状态产生负面影响时,管理算法通知见证服务器(witness server)将模型状态进行回滚。
Ekko 是一个地理分散的 DLRS,它在中心化的数据中心进行模型更新,然后将更新的模型传输到地理分散的数据中心,从而更接近分布于全球的平台用户。Ekko 将模型划分为多个碎片,并存储在键值对(key-value pair)中。存储碎片的键值对集合被称为参数仓库,参数仓库通过哈希映射为模型碎片分配键值对。此外,模型大小常常随时间变化,因为模型经常需要整合新的商品和特征。Ekko 通过基于软件的路由方法,将参数请求对应至模型碎片。在训练 DC 网络中,路由算法为模型碎片指定对应的参数服务器,并且这一过程引入了碎片管理算法,对不同参数请求进行负载均衡。
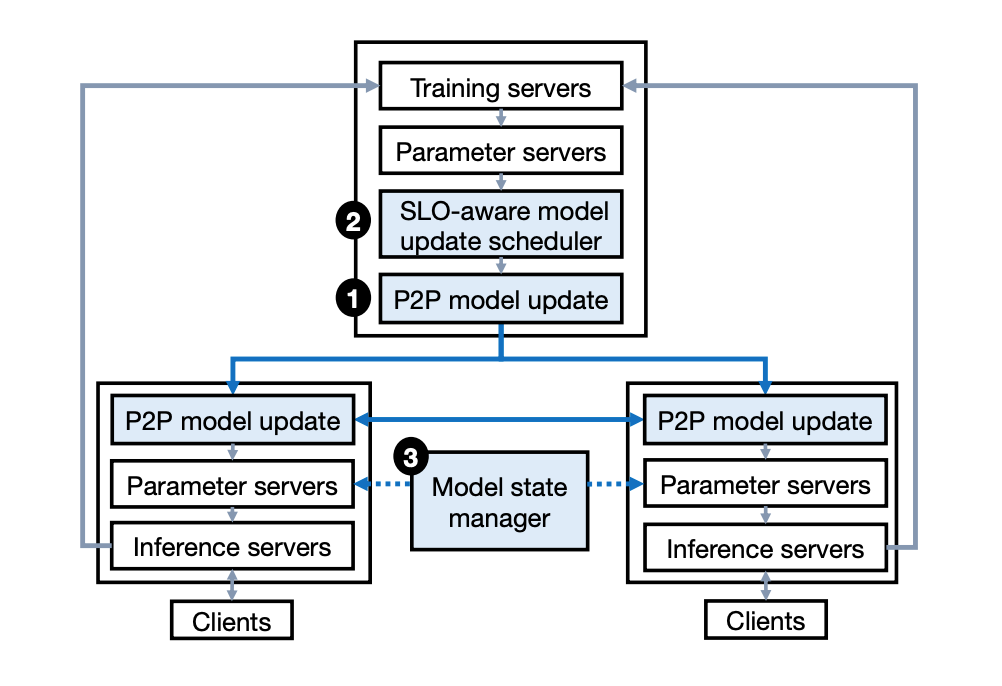
Ekko 的整体系统架构设计如下图所示。其中包含几个特点:
1. 针对参数服务器的高效点对点模型更新,这一模型更新算法避免了核心的训练数据中心广播更新模型,而是利用所有网络通路进行高吞吐量的点对点更新。这一做法不使用中心化的协调算法,每个数据中心能够独立地选择最优间隔进行模型更新同步;
2
. 基于面向 SLO 的模型更新调度算法,Ekko 支持同时大规模模型更新,调度算法选择所有更新中最有利于实现 SLO 的模型更新进行网络资源分配;
3. 基于模型状态管理算法,Ekko 能够通过计算 SLO 相关的模型推理指标,保护模型推理服务器免受有偏模型更新的影响。
![]()
Ekko 的高效点对点模型更新机制应当满足以下几个目标:
1. Ekko 需要协调数千个分布于全球的参数服务器完成每次参数更新。为了避免出现网络延迟造成的掉队服务器,我们设计了一种无日志的参数服务器同步方法;
2. 作为一个共享的 DLRS,Ekko 需要支持数千个机器学习模型。这些模型可能以高达十亿级别每秒的速度产生海量的线上更新。为了支持这一点,Ekko 的参数服务器能够通过点对点方式高效地发现模型更新,并在不使用大量计算和网络资源的情况下获取更新;
3. Ekko 需要支持地理分散部署,这通常涉及广域网之间的异构网络架构,和服务器或网络错误。针对这一点,Ekko 的系统设计能够提升广域网发送模型更新的吞吐量并降低延迟,同时容错服务器和网络错误。
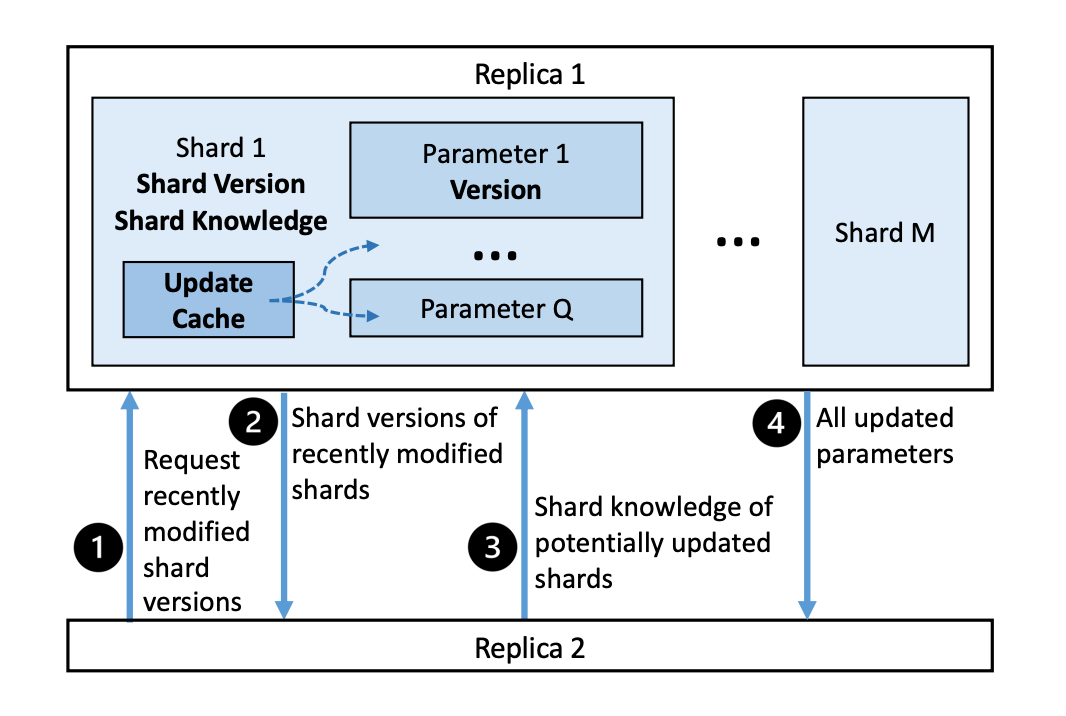
下图展示了 Ekko 进行点对点模型更新时涉及的系统模块和步骤。假设我们希望对图中碎片 1(shard 1)对两个副本(replica 1 和 replica 2)进行更新。和所有其他模型碎片一样,碎片 1 包括了:碎片知识(shard knowledge),为对参数更新的总结;更新缓存(update cache),基于参数版本对最近的模型更新进行追踪;碎片版本(shard version),能够用于判断该碎片是否可能需要进行参数同步。碎片知识、更新缓存和碎片版本共同加速了不同参数服务器之间的参数同步过程。
![]()
为了完成模型更新,副本 2 从副本 1 中请求最近修改的碎片版本。收到请求后,副本 1 返回最近修改碎片版本的列表,副本 2 随机将副本 1 的所有碎片版本与本地版本进行对比,并发送相关的碎片知识给副本 1。最终,副本 1 发送所有更新的参数给副本 2。通过这些步骤,Ekko 能够保证模型更新最终能低延迟地传输到所有副本,并保持最终一致性。
在实际的 DLRS 运行过程中,我们发现最终一致性是可以接受的。即便深度神经网络的不同副本可能在一小段时间中出现差异,他们通常表现出相近、甚至完全一致的模型推理结果。这是因为深度神经网络通常用浮点数表示模型参数,在只有少量参数数值差别的情况下,模型副本一般会产生相近的预测结果。
为了追踪模型参数状态,Ekko 给每个键值对(即模型参数碎片)分配了一个参数版本,包含一个不重复的副本编号,和一个基于物理时间的时间戳。为了保证同一个副本上的参数版本不出现重复,Ekko 对物理时间戳额外扩充了一个计数器。值得注意的是,相对于逻辑时间戳,在分布式 DLRS 中使用物理时间戳十分重要。当需要进行回滚时,物理时间戳可以确认不同副本中更新版本之间的先后顺序,从而保证更好的模型更新不会被覆盖。
在对参数版本进行标记后,Ekko 需要决定如何对不同副本进行同步。我们观察到一个 DLRS 通常会覆盖之前的参数,并只将最后一次参数状态写入。我们因此决定只发送最后一个版本的参数。
Ekko 需要决定副本间同步的时间间隔。我们可以使用一种基于日志的同步算法,这些算法选择一个同步间隔,使得模型更新的发送频率不会超过网络中最慢连接的带宽。然而这些算法使得网络中的很多连接不能得到充分利用。更重要的是,这种算法常常造成掉队服务器(straggler),显著增加了同步延迟,使参数服务器更容易因为回滚而保持陈旧的参数状态。因此,我们想要在参数服务器中实现一种无日志的参数同步方法,使这些服务器可以根据和其他节点间的带宽动态地选择同步间隔。
我们提出使用碎片知识来实现无日志参数同步。在每个副本中,所有碎片维护一个对应的碎片知识,它通过版本向量实现,总结了他们所学到的参数更新。碎片数据反映了一个空白的碎片,采用来自其他副本进行参数更新的状态。
为了减少参数同步对参数服务器造成的额外开销,Ekko 采用参数更新缓存和碎片版本控制来实现高效副本间参数同步。由于模型碎片包含了大量参数,简单地便利所有参数来回应每个同步请求可能会造成较大的计算开销。
针对这一问题,我们设计了参数更新缓存来减少参数同步的计算开销。这种设计基于我们在 DLRS 中观察到的稀疏性和时间局部性特点。不像稠密深度神经网络的训练那样,DLRS 中每次模型更新只针对模型参数的子集(即参数更新的稀疏性)。例如,在我们实际运行的 DLRS 中,每小时仅有 3.08% 的模型参数进行了更新。此外,在一个时间窗口中,通常会重复更新模型的特定参数(即时间局部性)。这是因为 DLRS 通常存在潮流商品和用户,对应的参数会在短时间内进行大量更新。
除了参数更新缓存,我们采用碎片版本维护来捕捉碎片数据和副本之间的因果关系。碎片版本中包括了一个单调递增的不重复计数器,以及与这一版本相关的副本 id。基于这一碎片版本维护机制,副本间可以通过交换和对比碎片版本列表,确认哪些碎片可能需要更新,从而高效地寻找各个副本中需要更新的模型碎片。
Ekko 允许直接将模型更新传输至模型推理集群中的参数服务器,这对完成推荐服务的 SLO 造成了两大挑战:1)网络拥塞可能造成重要模型更新延后送达;2)基于小批量训练的模型更新可能由于数据中的 bias 产生负面模型预测效果。
1. 新鲜度,这一指标衡量为新内容和新用户提供模型推理服务的延迟性。这一 SLO 对线上推荐服务至关重要,特别是例如抖音和 YouTube 这样和用户进行实时交互的平台应用。这类应用需要及时捕捉用户的实时交互行为和潮流商品的实时状况,否则用户很容易因失去兴趣而离开推荐平台。提升新鲜度通常会导致更好的用户体验,并能够更快地对新内容进行更合适的曝光;
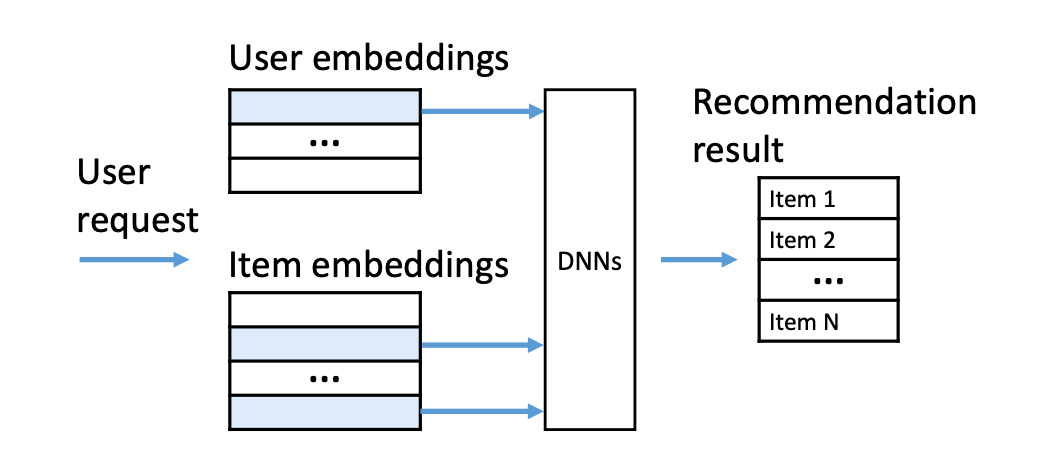
2. 质量 SLO,这一指标衡量对用户体验和参与度,例如推荐视频中用户点击对数量、用户观看时长,反映了对用户偏好预测的准确情况。下图展示了 DLRS 中一个模型推理服务器的工作流程。
![]()
为了防止新鲜度和质量 SLO 同时被网络拥塞影响,Ekko 采用一种面向 SLO 的模型更新调度算法,并将其整合进点对点模型更新传输过程中。具体来说,Ekko 使用如下几个指标去衡量每个模型更新的优先级,并根据优先级分配网络资源进行传输:
1. 更新新鲜度优先级,这一优先级指标是基于在实际生产中的观察而设计的。如果一个参数最近被创建,则该参数拥有较高优先级,否则它的优先级较低。这是由于,新创建的模型参数相对于过去一段时间的模型参数,通常对模型推理效果产生更大对影响;
2. 更新显著性优先级,我们使用模型更新梯度的大小来衡量该参数是否被显著更新。具体来说,我们使用模型参数的 1 范数模除以平均值。这种做法直观上可以反映模型参数被更新的显著程度;
3. 模型优先级,在 DLRS 中不同模型通常收到不同频率的预测请求,这反映了他们在满足整体 SLO 中的不同重要程度。基于这一点,Ekko 优先分配网络资源给具有较多更新的模型。
Ekko 使用一种推理模型状态管理算法来防止 SLO 由于有害的模型更新受到影响。这一管理算法监控推理模型的健康(即质量 SLO)并根据需求进行低延迟的模型状态回滚。
对于一个 DLRS 系统,Ekko 为它的所有推理模型创建基线模型,基线模型对少量用户流量(通常<1%)进行处理,并且不需要保证其训练数据的时效性。基于普通推理模型和基线模型的用户预测各类指标,Ekko 的状态管理器通过异常检测算法判断当前模型状态是否健康。管理算法的判断包含三种情况:健康、不健康、或不确定,当管理算法确定当前模型状态不健康时,会重定向当前用户请求到备选推理模型,并发起一次模型状态回滚。
Ekko 采用见证服务器对不健康模型状态进行回滚。见证服务器参与副本同本,但不参与模型训练。与参数服务器不同,见证服务器不会立即将更新的参数储存进参数仓库,并且不会在同步中运行优先级调度。具体来说,Ekko 将未存储的参数更新插入日志中,每篇日志与同步的物理时间戳对应。当短时间内有多个同步操作时,Ekko 对其进行合并以节省空间。下图展示了回滚模型状态的工作过程。
![]()
![]()
本文对 Ekko 系统进行了测试台测试和实际生产环境验证。测试台环境为一个包括 30 台服务器的集群,我们将每三个服务器组成一个数据中心,以模拟多数据中心场景。其中一个数据中心被用于训练,从训练服务器中接受模型更新,其他数据中心作为推理服务器。
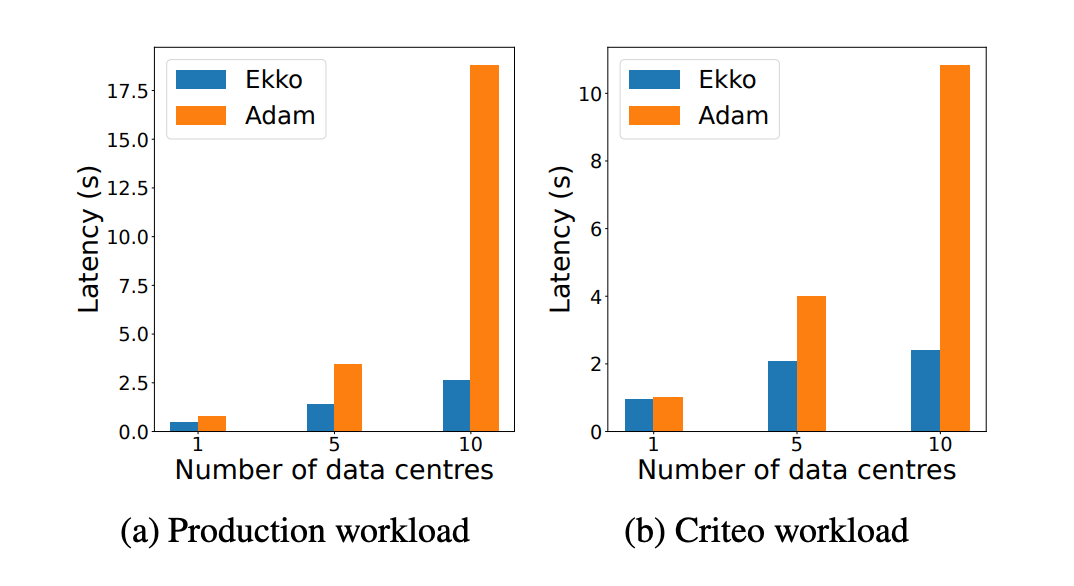
本文在一个同构广域网上测试了 Ekko 的更新延迟性,对比方法为常用于同步模型更新的 Adam 方法。下图展示了在不同数据中心数量多情况下,Ekko 和 Adam 多延迟秒数。从结果中可以看出,Ekko 相对于 Adam 取得了明显更低的延迟,这主要归因于 Ekko 具有较强扩展能力的点对点同步架构。同时,对比与另一个基线系统 Checkpoint-Boradcast,在基于广域网进行 4GB 参数同步时,基线方法相对于 Ekko 花费了 7 秒更多的延迟时间。
![]()
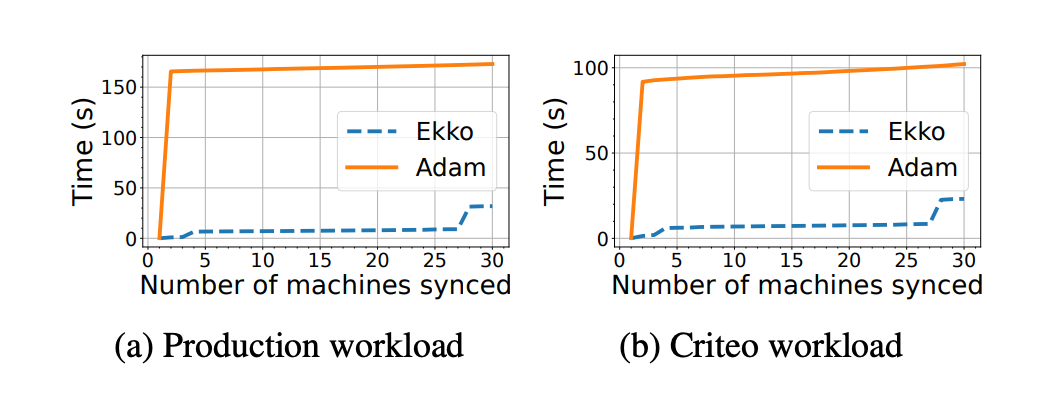
同时,本文也在异构广域网上进行了实验,对比 Ekko 系统和 Adam 系统在不同同步机器数量的情况下的延迟时间,实验效果如下所示,同样验证了 Ekko 的低延迟性能。
![]()
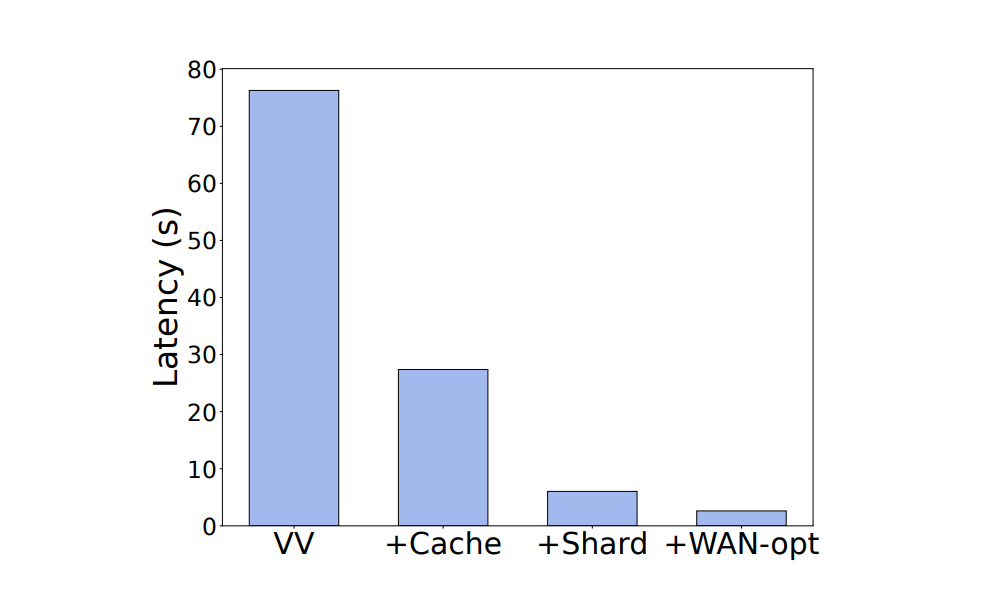
为了进一步探究 Ekko 进行同步时各个模块的单独时间开销,我们进一步分解模型模块,以验证其对 Ekko 低延迟性能的贡献,结果如下图所示。首先,我们构建了一个只使用碎片知识的 Ekko 系统,在下图中标记为 VV。之后,我们分别在这一基线模型基础上添加更新缓存(+Cache)、碎片版本(+Shared)以及广域网优化(+WAN-opt)。从下图结果中可以看出各个模块对降低同步延迟的作用。
![]()
针对 Ekko 的 SLO 保护机制,我们进一步测试了在网络拥塞情况下 Ekko 的延迟状况和 SLO 相关指标。实验通过 A/B 测试进行,Ekko 在降低同步流量的同时,保持了显著参数更新的延迟性。同时,控制组在基于 SLO 的指标中下降了 2.32%。这一结果验证了 Ekko 的 SLO 保护机制的有效性。
![]()
本文提出了 Ekko,一个创新的深度学习推荐系统,能够低延迟地进行大规模模型参数更新。Ekko 包括一个高效的点对点更新算法,能够协调十亿级别的模型更新,进行高效传输至地理分散数据中心的副本。它进一步设计了一种 SLO 保护机制,能够保护模型状态不受网络拥塞和有害模型更新的影响。实验结果显示 Ekko 能够大幅降低深度学习推荐系统的延迟,验证了其创新设计的有效性。
![]()
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
![]()