线上系统性问题定位与方法论
前言
一线程序员在工作中经常需要处理线上的问题或者故障,但工作几年下来发现,有些同事其实并不知道该如何去分析和解决这些问题,毫无章法的猜测和尝试,虽然在很多时候可以最终解决问题,但往往也会浪费大量的时间,时间就是金钱,对线上系统而言甚至是生命。
本文讲什么:本文尝试将本人工作过程中对线上问题的处理经验加以总结精炼,并给出一套相对有规律的问题定位处理模式,希望能够在排查问题的过程中可以帮助大家节省一些时间,尽快找出问题的关键点并修复。
本文不讲什么:1. 这不是一篇linux命令的教程,虽然文章里会提到一些命令,但只会简单介绍他们的作用和应用场景,详细使用说明请大家自行google。2. 本文不打算为所有问题寻找解决方案,事实上下面列出的方法只对大部分Java编写的web系统比较有意义,一些特别个性化的案例也不再讨论范围之内。
了解你的系统
什么样的现象应该列为“系统问题”?某个服务的QPS达到1000?对于一般系统或许算是,但是对大型电商网站,或许这只是常态。
很显然对于不同规模,不同功能的系统,这个问题无法一概而论。因此快速发现问题的前提是深入了解你的系统。
通常情况下,我们可以把系统简单的划分为下面三个层次:
系统层
也就是我们的部署软硬件环境。通常包含CPU、磁盘、内存、网络IO等。我们的系统是分布式的,还是单机应用?CPU是几核的?物理机还是虚机?内存、磁盘是多大?网卡的规格?
软件层
也是我们部署的软件环境。负载均衡服务器?JDK版本?web服务器(Tomcat等)以及JVM参数设置?数据库、缓存使用的是哪种产品?
应用层
也就是我们的系统本身。关键接口的平均响应时间(RT)是多少?服务的QPS是多少?某个接口的并发数能承受多少?
以上这些问题你是否能回答出来?这些问题的了解多寡,决定了你对系统的熟悉程度,也在很大程度上决定了你能否及时的发现问题,甚至在其真正造成影响之前就将问题解决。
现在你或许能回答:某个服务的QPS达到1000,究竟算不算是线上问题。
评估问题影响范围
一个问题究竟影响了多大范围的用户?在多大程度上影响用户的正常使用?如果是集群系统,那么这个问题是全局性的还是只在单台机器上出现?不同的问题范围会直接影响到问题处理的优先级,一些极端情况下的个案,甚至可以不急于处理(至少不用过于焦虑)。
问题信息的搜集来源,有如下途径:
系统、业务监控报警
一般稍微上规模的公司,都会有配套的监控系统,通常监控系统报警都意味着问题已经影响到系统的正常运行了,此时属于比较严重的生成事故,需要第一时间处理。此类问题由于可以重现,因此比较容易排查。
关联系统故障追溯
关联系统发现问题,通过追溯发现是由本系统的问题引发的,此时问题的触发的往往已经比较明确,需要根据关联系统的故障程度决定问题处理的优先级。但此类问题很容易牵扯出隐藏的其他问题(如系统改造时沟通不善造成的适配问题等),紧急修复后还需要进行进一步仔细排查。
生产事件上报(客服上报)
此类问题往往来自用户投诉,最重要的就是问题现象的复现。
主动发现
通过线上监控,或者日志,主动发现线上系异常的情况。需要确认是否是问题,可能只是偶发性的系统抖动。
快速恢复
说回问题本身,一旦确定是系统bug,该如何处理?立即去检查代码?且不说线上bug往往不那么容易检查出来,及时能够快速定位,修复又会耗费大量时间,这期间不知有多少用户受到影响。
线上问题处理的核心是快速修复。有以下两类处理方案:
1. 无法快速定位到问题根源
回滚:当最近有新版本上线时,多半首选这种方案
重启:CPU高,或者连接数飙升时,会采取这种方法
扩容:线上访问压力大,重启也无法解决时
2. 可以定位到问题点的
临时方案或者功能降级
无论哪种方式,目标都是以最快速度恢复服务。但这种方式是临时的,为了彻底解决问题,都需要保留事故现场。基本方式如下:
a. 执行top命令,若CPU空闲程度较低:shift+p按CPU使用率倒排,记录最耗资源的进程信息。
b. 执行free –m命令,若内存使用量高:执行top,shift+m按内存使用率倒排,记录最耗资源的进程信息。
c. 对嫌疑进程执行ps xuf | grep java,打印进程详细信息并记录。
d. 使用jstack <PID> >jstack.log收集线程信息(反复多取几次)。
e. 使用jstat–gcutil <PID> 查看Old区占用率,对接近100%的进程执行jmap<PID> > jmap.log保留内存信息。
定位与修复
下图展示了常规情况下我们系统故障的原因:
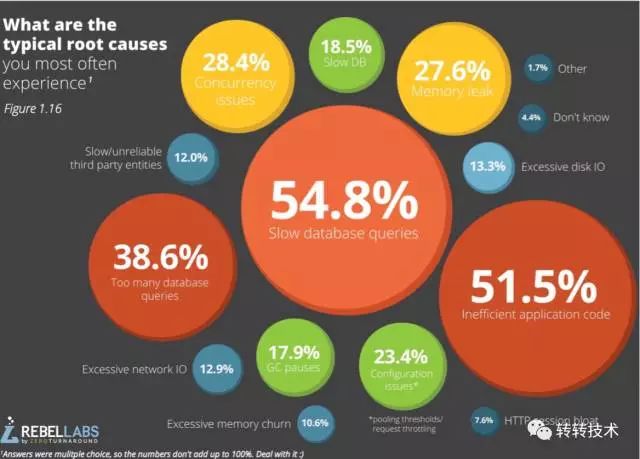
图1-系统故障原因
由此可见,多数情况下,系统的故障都会反映为系统的一项或者多项指标异常。如最初所说,我们可以将整个系统抽象成为几个模块,那么对应的,每个模块也有一些工具供我们进行问题的分析与定位。
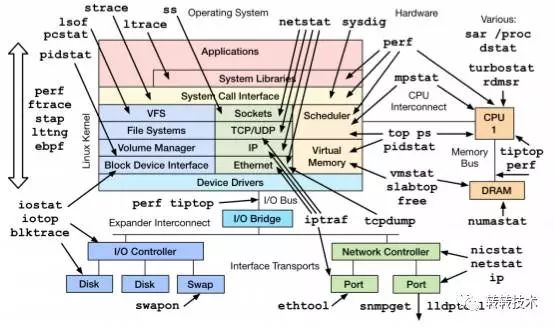
图2-Linux常用工具集
以下是常见的问题排查工具箱:
CPU:top –Hp
系统内存:free –m
IO:iostat
磁盘:df –h
网络链接:netstat
gc:jstat –gcutil
线程:jstack
Java内存:jmap
辅助工具:MAT,btrace,jprofile
具体的使用方法不再赘述
方法论
有了基本的系统模块划分,以及每个模块对应的分析工具,我们可以尝试将问题的排查抽象成一个相对固定的流程。大致的思路是:
先逐个模块排查,确认问题现象
再根据问题现象,定位问题进程
进一步分析线程以及内存情况
最终找到问题的触发点。
基本流程如下图所示:
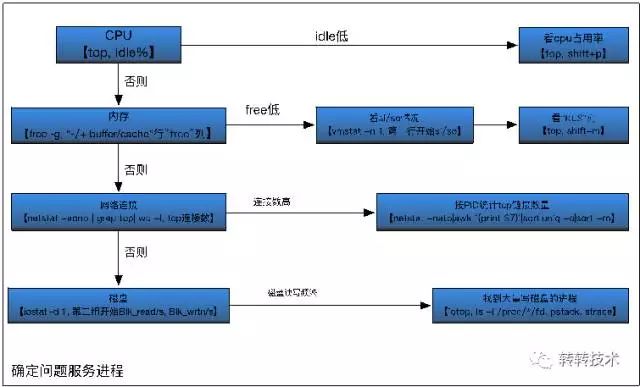
图3-逐步排查,锁定问题进程
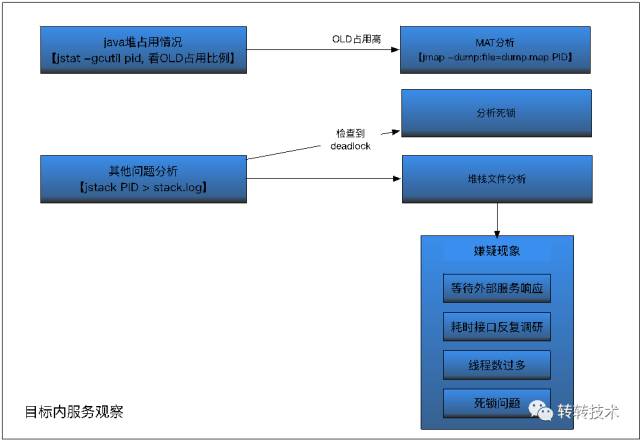
图4-详细分析目标进程
为故障与失败做设计
随着系统规模的逐渐扩大,更多的功能被引入,更多的代码被添加进来,从这个角度来看线上的问题几乎是无可避免的。以上说的都是问题发生后的消极应对措施。事实上,无论我们的设计多么的完善,故障仍然是无法避免的。而且大多数时候,失败、故障都会从一个我们无法预期的角度发生,令人猝不及防。
因此在系统架构时需要设计一种机制,使得失败、故障发生时能将系统的损失降到最低,在故障发生时尽可能维持核心功能的可用性。
1. 设置合理的超时机制
处理网络上第三方依赖时,需要对接口的响应时间有一个合理预期,当请求超时时能够主动断开连接,避免请求堆积。
本地服务相互调用时也需要合理的设置超时时间。
2. 服务降级
对于无法正常响应的应用程序应对可以自动切换到较低版本的实现。
对于一些次重要级的接口,可以考虑返回一个系统默认值。
3. 主动抛弃
对于响应过慢的第三方接口,如果非核心调用,也可以采取直接抛弃的方式。
无论是降级或者抛弃,系统都应当具备适当的重试机制,使得依赖在回复之后可以自动恢复正常调用。
作者简介
孙思,转转交易系统负责人,08年北航计算机系虚拟现实实验室研究生毕业。毕业后入职中国民航信息网络股份有限公司(TravelSky),负责机票发布平台(EasyFare)的研发和维护工作。2010年进入互联网行业,先后供职于网易(北京)、搜狐和去哪儿网,参与过网易电商基础平台建设,活动及促销运营平台的设计与实现;搜狐新闻客户端的开发、重构,以及去哪儿网旗下当地人产品的交易、支付系统的升级改造。2016年04月加入转转公司,担任中台技术部交易系统负责人,整体负责转转的交易系统、支付中心以及活动促销运营等系统的研发工作。对大规模电商平台、分布式系统的设计和实现有较深入的了解。
出处:https://mp.weixin.qq.com/s/4HTW3BmW1HfGyVmomO1Wrw
版权申明:内容来源网络,版权归原创者所有。除非无法确认,我们都会标明作者及出处,如有侵权烦请告知,我们会立即删除并表示歉意。谢谢。
-END-

架构文摘
ID:ArchDigest
互联网应用架构丨架构技术丨大型网站丨大数据丨机器学习

更多精彩文章,请点击下方:阅读原文