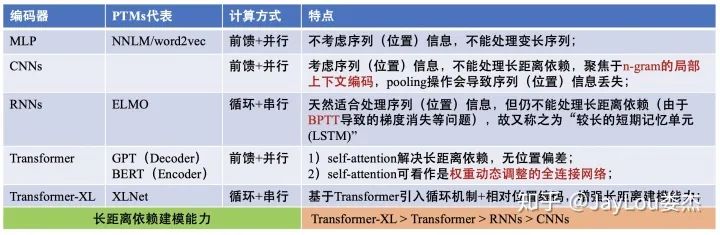
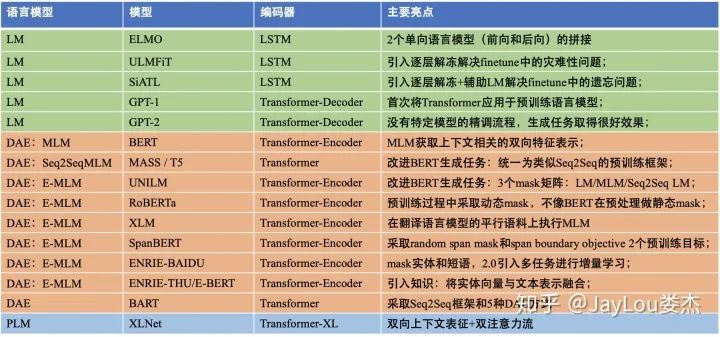
预训练模型(Pre-trained Models,PTMs)的出现将NLP带入了一个全新时代。2020年3月18日,邱锡鹏老师发表了关于NLP预训练模型的综述《Pre-trained Models for Natural Language Processing: A Survey》,这是一篇全面的综述,系统地对PTMs进行了归纳分类。
[1] Pre-trained Models for Natural Language Processing: A Survey https://arxiv.org/abs/2003.08271v2 [2] A neural probabilistic language model. [3] Distributed representations of words and phrases and their compositionality. [4] GloVe: Global vectors for word representation [5] Character-aware neural language models. [6] Enriching word vectors with subword information. [7] Neural machine translation of rare words with subword units. [8] Skip-thought vectors [9] Context2Vec: Learning generic context embedding with bidirec- tional LSTM. [10] https://zhuanlan.zhihu.com/p/110805093 [11] Deep contextualized word representations. [12] Improving language understanding by generative pre-training. [13] abBERT: pre-training of deep bidirectional trans- formers for language understanding [14] abcXLnet: Generalized Autoregressive Pretraining for Language Understanding [15] Learned in translation: Contextualized word vectors. [16] abSelf-supervised Visual Feature Learning with Deep Neural Networks: A Survey [17] abcdSelf-supervised Learning 再次入门 https://zhuanlan.zhihu.com/p/108906502 [18] Language models are unsuper- vised multitask learners [19] ULMFiT:Universal Language Model Fine-tuning) [20] SiATL:An Embarrassingly Simple Approach for Transfer Learning from Pretrained Language Models [21] MASS: masked sequence to sequence pre-training for language generation. [22] Exploring the limits of transfer learning with a uni- fied text-to-text transformer [23] abRoBERTa: A ro- bustly optimized BERT pretraining approach [24] Unified language model pre-training for natural language un- derstanding and generation. [25] abCross-lingual lan- guage model pretraining. [26] SpanBERT: Improving pre- training by representing and predicting spans. [27] ERNIE: enhanced representation through knowledge integration [28] ERNIE 2.0: A continual pre-training framework for language understanding [29] BERT is not a knowledge base (yet): Factual knowledge vs. name-based reasoning in unsupervised QA [30] ERNIE: enhanced language representation with informative entities [31] BART: denoising sequence-to- sequence pre-training for natural language generation, transla- tion, and comprehension. [32] Neural autoregressive distribution estimation [33] 他们创造了横扫NLP的XLNet:专访CMU博士杨植麟 [34] A theoretical analysis of contrastive unsupervised representation learning. [35] A mutual information maximization perspective of language representation learning [36] Noise-contrastive estimation: A new estimation principle for unnormalized sta- tistical models. [37] ELECTRA: Pre-training text encoders as discriminators rather than generators [38] Pretrained encyclopedia: Weakly supervised knowledge-pretrained language model [39] aALBERT: A lite BERT for self-supervised learning of language representations. [40] StructBERT: Incorporating language struc- tures into pre-training for deep lanuage understanding [41] BERTje: A dutch BERT model [42] Informing unsupervised pre- training with external linguistic knowledge [43] Sentilr: Linguistic knowledge enhanced lan- guage representation for sentiment analysis [44] SenseBERT: Driving some sense into BERT [45] Knowledge enhanced contextual word representations [46] KG-BERT: BERT for Knowledge Graph Completion [47] K-BERT: Enabling lan- guage representation with knowledge graph [48] K-adapter: Infusing knowledge into pre-trained models with adapters [49] KEPLER: A unified model for knowledge embedding and pre-trained language representation [50] Enhancing pre-trained language representations with rich knowledge for machine reading comprehension. [51] Compressing BERT: Studying the effects of weight pruning on transfer learning [52] REDUCING TRANSFORMER DEPTH ON DEMAND WITH STRUCTURED DROPOUT [53] Q- BERT: Hessian based ultra low precision quantization of BERT. [54] Q8BERT: Quantized 8bit BERT. [55] BERT-of-Theseus: Compressing BERT by pro- gressive module replacing [56] DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter. [57] MT-DNN:Improving Multi-Task Deep Neural Networks via Knowledge Distillation for Natural Language Understanding [58] TinyBERT: Distilling BERT for natural language understanding [59] MobileBERT: Task-agnostic com- pression of BERT by progressive knowledge transfer [60] MiniLM: Deep self-attention distillation for task-agnostic compression of pre-trained transformers. [61] Extreme language model compression with optimal subwords and shared projections [62] Distilling task-specific knowledge from BERT into simple neural networks [63] VideoBERT: A joint model for video and language representation learning [64] Contrastive bidirectional transformer for temporal representation learning [65] Univilm: A unified video and language pre-training model for multimodal under- standing and generation. [66] ViL- BERT: Pretraining task-agnostic visiolinguistic representa- tions for vision-and-language tasks [67] LXMERT: learning cross- modality encoder representations from transformers. [68] VisualBERT: A simple and performant base- line for vision and language. [69] Fusion of detected objects in text for visual question answering. [70] Unicoder-vl: A universal encoder for vision and language by cross-modal pre-training [71] UNITER: learning universal image-text representations [72] VL-BERT: pre-training of generic visual- linguistic representations [73] SpeechBERT: Cross-modal pre-trained language model for end-to-end spoken question answering. [74] BioBERT: a pre-trained biomedical language representation model for biomedical text mining. [75] SciBERT: A pre- trained language model for scientific text [76] Clin-icalBERT: Modeling clinical notes and predicting hospital readmission. [77] BERT-based rank- ing for biomedical entity normalization. [78] PatentBERT: Patent clas- sification with fine-tuning a pre-trained BERT model. [79] SentiLR: Linguistic knowledge enhanced lan- guage representation for sentiment analysis. [80] Progress notes clas- sification and keyword extraction using attention-based deep learning models with BERT. [82] Unicoder: A universal language encoder by pre-training with multiple cross-lingual tasks. [83] Pre-training with whole word masking for chinese BERT [84] ZEN: pre-training chinese text encoder enhanced by n-gram representations. [85] NEZHA: Neural contextualized representa- tion for chinese language understanding [86] BERTje: A dutch BERT model. [87] CamemBERT: a tasty french language model [88] FlauBERT: Unsupervised language model pre-training for french [89] Rob-BERT: a dutch RoBERTa-based language model. [90] Multi-task deep neural networks for natural language understanding. [91] https://zhuanlan.zhihu.com/p/114785639 [92] Transformer-XL: Atten- tive language models beyond a fixed-length context.