20种鸟类,14311条自然音频,智源研究院联合百鸟数据发布大型鸟鸣数据集Birdsdata


声音是自然界的馈赠,除了带来愉悦的体验外,更是作为监测生态系统健康与否的重要指标。通过分析自然采集声音中的各类元素(例如:环境声音、物种种类与突发状况声音等),可以极大改善保护地监测数量不足与质量不高等问题,增进对自然的理解和保护,为保护地长期监测大数据积累做出积极贡献。
但目前国内鲜有专门的声学材料库,尤其是经由相关专业人员手工标记及检验过的标准自然来源声音数据,因而本数据集的建立在积累大量中国本土自然声音的同时,也为后续相关模型算法的测试提供了坚实的基础。
Birdsdata 数据集(公开部分)包含 14311 条自然音频,每条长度均为 2s;目前总共包含 20 种鸟类且以一定速度增加,该部分未包含各种环境音的标记数据。智源数据分享平台上 Birdsdata 数据集(公开部分)共包含了以下两个部分:
① BirdsData-BirdsSong-2s-30min-20spec.zip
包含中国常见鸟种 20 种鸟鸣合集,共有声音片段 14311 个,该部分处理过程为:
A. 实际收集+网络采集鸟鸣声音文件,标记出目标鸟鸣准确时间段。
B. 将鸟鸣文件按标记时间段切割,并进行 2s 标准化切割,清除小于 2s 的声音文件。
C. 检验切割质量,遴选 30min 标准声音。
D. 按鸟种编号分目录存储。
② BirdsData-BirdsList.txt
包含第一部分所涉及鸟种的标准中文名对应关系。例如,第二部分的第一行“0009 灰雁”,即对应第一部分的 0009 子目录,表示该子目录为灰雁。
调用方式示例:
1. 按行读取第二部分txt中记录,读取至内存。
2. 循环遍历第一部分的子目录,提取特征值,推荐特征矩阵为 mel 频谱三维向量,并按目录编号与第二部分的记录做对应,可存为 pickle 文件(硬盘文件)。
3. 根据特征值,选择机器学习框架进行训练,训练集和测试集比例推荐为 7:3,推荐模型为 CRNN,并保存训练模型或权重文件。
4. 编写验证程序,分割验证声音为 2s 片段,使用模型验证,推荐形成 web 接口,反馈对应的物种名称和可靠度。
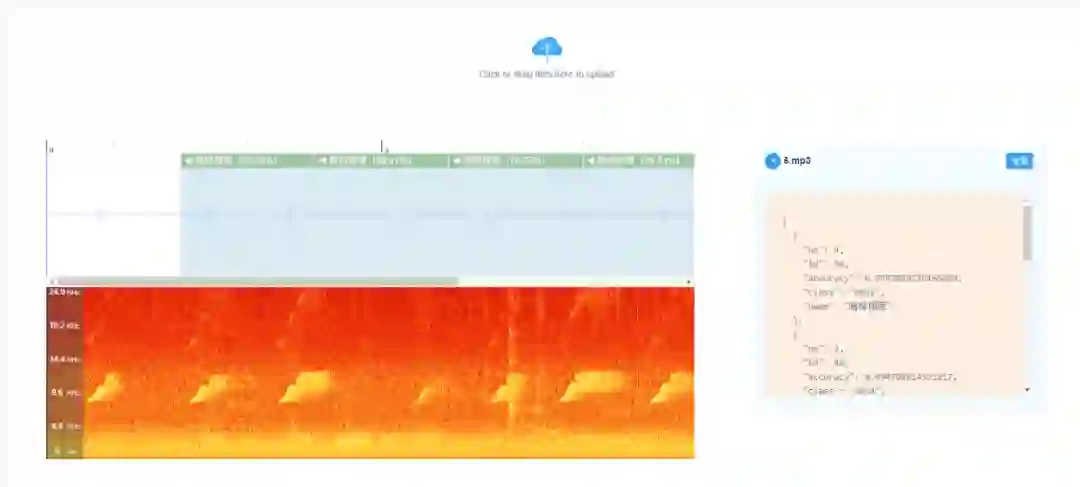
验证程序示例
下载链接:https://pan.baidu.com/s/1M-3AQhle_TigrbjjT-z0pw (提取码:61g6)



登录查看更多
相关内容






相关VIP内容
相关资讯