AI寒冬将至?「人工智能衰退论」再起,却遭LeCun怒斥
作者:Filip Piekniewski
机器之心编译
《AI Winter is Well on its Way》是计算机视觉和 AI 领域专家 Filip Piekniewski 所写的一篇文章,文中提到了很多深度学习顶级研究者的观点,如 Geoff Hinton、吴恩达、Yan LeCun、李飞飞、Gary Marcus 等,并以「谷歌、Facebook 等公司对 AI 的研究兴趣正在衰退」作为论据。本文主要涉及「深度学习蒙尘」、对深度学习扩展能力和自动驾驶的讨论、对该领域炒作的批判,最终结论是 AI 寒冬必将到来。对此,Yann LeCun 认为这篇文章「very uninformed」,并列出了几点理由。

近日,一篇名为《AI Winter is Well on its Way》的文章刷屏了(嗯哼,即将刷屏,微笑),对此 Yan Lecun 的评价是:
这篇文章非常无知。Facebook、谷歌、微软等企业近期增加了他们在 AI 方面的努力。
Facebook 现在拥有一个专注于 AI 研究的大型组织,还有人工智能副总裁。微软事业部的名称里就有「AI」(而没有提到「Windows」或「Office」)。谷歌将其整个研究组织重命名为「Google AI」。
这三家公司在雇佣 AI 科学家和工程师方面一直在加速。目前来看并没有平台期或者减速现象。
《AI Winter is Well on its Way》究竟在讲什么呢?机器之心对该文章进行了编译介绍:
近几年来,深度学习一直处于所谓「人工智能革命」的前沿,许多人认为,正是这颗银色的子弹将把我们带到技术奇点的神奇世界(通用人工智能)。很多企业在 2014、2015 和 2016 年进行了多次押注,当时人工智能还有一些新的进展,如 AlphaGo 等。特斯拉等公司宣布,人类距离全自动驾驶汽车已近在咫尺,特斯拉甚至已经开始向客户推销这一概念,以便未来的软件更新能够将其实现。
现在已到 2018 年中,情况已经发生了变化,虽然表面上还看不出来。NIPS 会议仍被过度炒作,企业公关的新闻稿中仍然充斥着人工智能,马斯克依然承诺制造自动驾驶汽车,谷歌 CEO 不断重复吴恩达的口号——「人工智能的影响大于电力」(AI is bigger than electricity)。但这种表述开始出现漏洞。正如我在之前的文章(https://blog.piekniewski.info/2016/11/15/ai-and-the-ludic-fallacy/)中所预测的那样,最明显的漏洞是自动驾驶这一技术在现实世界中的实际应用。
深度学习蒙尘
当 ImageNet 问题得到有效解决(注意,这并不意味着视觉问题得到解决),该领域的许多著名研究人员(甚至包括一贯低调的 Geoff Hinton)都在积极地接受新闻采访,在社交媒体上发表文章(如 Yann LeCun、吴恩达、李飞飞)。总的来说,我们正面临着一场巨大的革命,从现在开始,一切只能加速。几年过去,这些人的 Twitter feeds 变得不那么活跃了,以吴恩达的 Twtter 为例:
2013 年:每天 0.413 条推文
2014 年:每天 0.605 条推文
2015 年:每天 0.320 条推文
2016 年:每天 0.802 条推文
2017 年:每天 0.668 条推文
2018 年:每天 0.263 条推文(截至 5 月 24 日)
或许这是因为吴恩达骇人的主张现在受到了社区更多的审视,如以下推文所示:
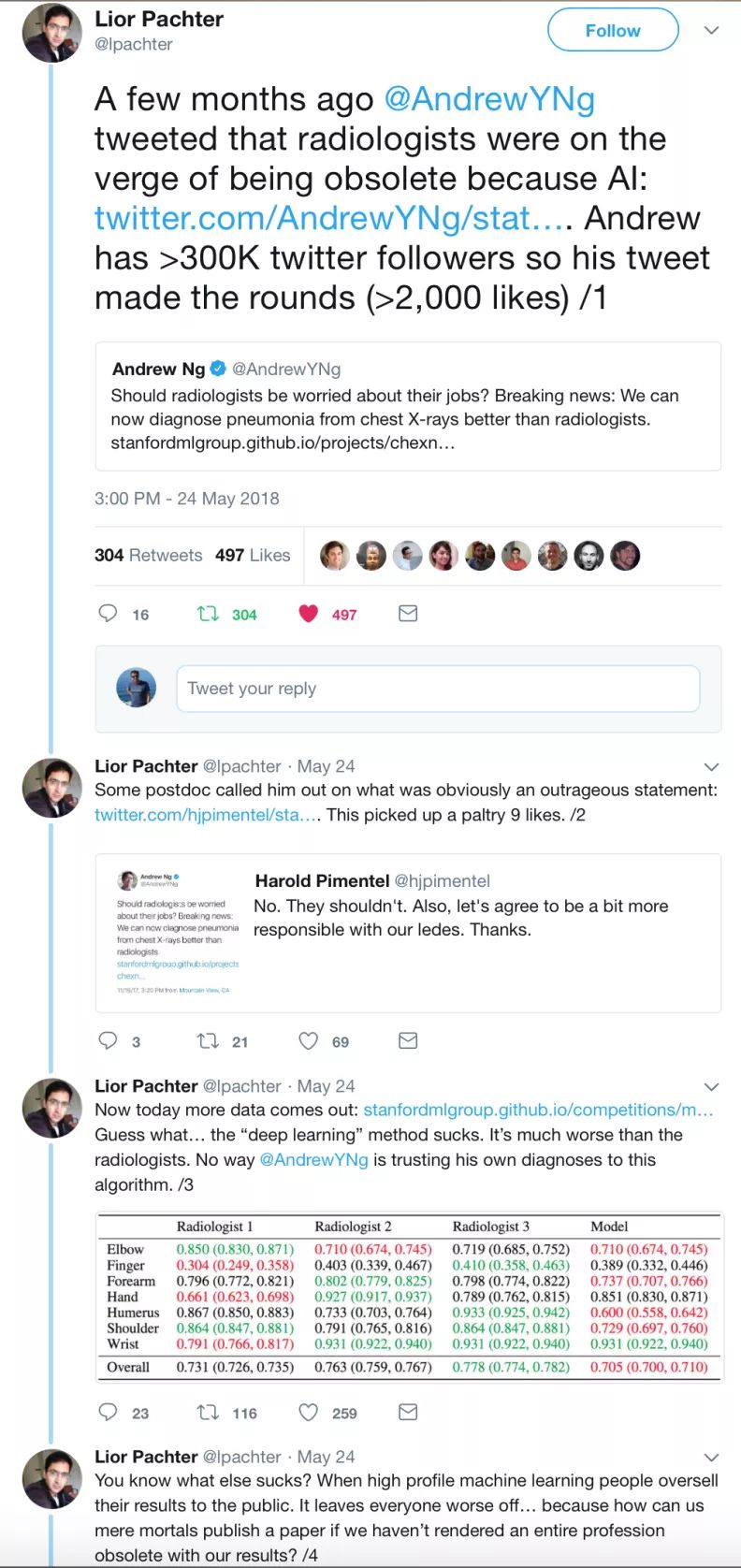
很明显,人气已经大幅下滑,称赞深度学习是终极算法的推特少之又少,论文不再那么具有颠覆性,而是被视为一种发展演变。自从发布 AlphaGo Zero 以后,DeepMind 再也没有什么突破性进展,即使是 AlphaGo Zero 也没有那么令人兴奋,因为只需要大量的计算,而且只适用于游戏(参见莫拉维克悖论)。OpenAI 相当安静,他们最后一篇爆款文章是《Dota 2》(我想这一突破应该会像 AlphaGo 一样引起轰动,但却很快就销声匿迹了)。实际上,有文章甚至称谷歌也不知道该如何处理 DeepMind,因为它们的结果显然不像原来预期的那样实际……著名的研究人员一般都是去加拿大或法国与政府官员会面,以争取未来的资助,Yann LeCun 甚至从 Facebook 研究负责人的位置退了下来,成为首席人工智能科学家(颇具象征意义)。从有钱的大公司到政府资助机构的逐渐转变让我觉得,其实这些公司(我想到了谷歌和 Facebook)对这类研究的兴趣正在慢慢消退。这些都是早期的迹象,他们没有大声说出来,只给出了肢体语言。
深度学习(并没有)扩展
其中一个关键口号是不停重复说「深度学习几乎可以毫不费力地实现扩展」。2012 年 AlexNet 出现,拥有大约 6 千万参数,那么现在我们的模型或许具备至少 1000 倍的参数吧?或许是的,但是问题在于:性能也是之前的 1000 倍吗?或者 100 倍?OpenAI 的一项研究显示:
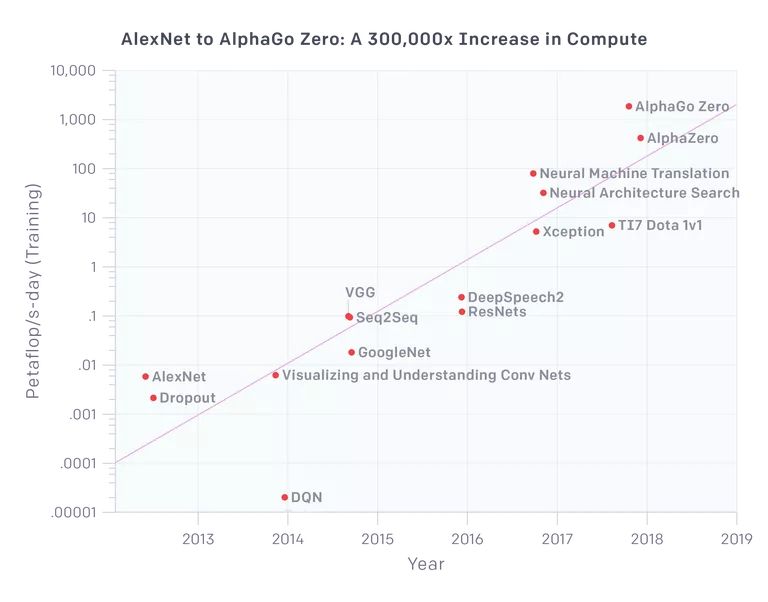
在视觉应用领域,我们可以看到 VGG 和 ResNet 在计算资源到达一定数量级之后逐渐饱和(参数数量实际上减少了)。Xception 是谷歌 Inception 架构的变体,事实上它在 ImageNet 数据集上的性能仅比 Inception 好一点点,也只是稍微优于其他模型,因为 AlexNet 本质上解决了 ImageNet 问题。那么即使我们使用的计算量是 AlexNet 的 100 倍,我们得到的也是饱和的架构,不论是视觉模型还是图像分类。神经机器翻译是所有网络搜索公司都参与的一次大型「战役」,也无怪乎它使用了能使用的所有计算资源(尽管 Google Translate 效果比之前好了一些,但仍然不够优秀)。上图的最后三个点非常有趣地展示了强化学习相关项目,它们被应用于 DeepMind 和 OpenAI 的游戏中。尤其是 AlphaGo Zero 和更通用的 AlphaZero 耗费的计算量大到荒谬,而且无法在现实应用中使用,因为相当一部分计算量用在了模拟和生成数据上,此类模型需要大量数据。那么我们现在可以在几分钟内训练 AlexNet,而不用花费数天时间,但是我们可以在几天时间内训练出 1000 倍大的 AlexNet,并取得更好的性能吗?明显不能……
事实上,上图原本旨在展示深度学习扩展的优异性,但是却达到了相反的效果。我们无法扩展 AlexNet,并得到更好的结果,我们必须使用特定的架构,且高效额外的计算量在缺乏数量级增长的数据样本的情况下无法带来较大的性能改进,而这么多数据只有在模拟游戏环境中才能获得。
自动驾驶车祸
目前对深度学习最大力的鼓吹在自驾汽车领域(我曾在很长时间内对此有所期待)。起初,人们认为端到端深度学习可以在某种程度上解决这个问题,这也是英伟达曾大肆宣扬的假设。虽然不敢保证,但我不认为这个世界上还有人会相信这个说法。看看去年的加州 DMV 脱离报告中,英伟达的汽车无法在没有脱离的情况下驾驶十公里。2016 年以来发生了好几起特斯拉自动导航引起的事故,有些甚至是致命的。可以认为特斯拉的自动导航不应该和自驾混淆,但至少在核心上它们是依赖于相同的技术。在今天,除了偶尔的特大失误,它仍然无法在十字路口停车、识别交通灯或通过交通环岛。这还是在 2018 年 5 月,在承诺穿越美国东西海岸(coast to coast)的特斯拉自动驾驶旅程(并没有发生,虽然谣言称他们曾尽力尝试,但并不能在没有约 30 次脱离的条件下成功)的几个月之后的状况。在几个月前(2018 年 2 月),马斯克在一次电话会议中被问及 coast to coast 自驾时重复道:
「我们本来应该完成穿越东西海岸的自动驾驶行程,但它需要太多的专用代码才能有效地执行,这令其变得脆弱,才能在特定的路径中工作,而不能得到通用的解决方案。因此我认为我们可以在相同的路径下重复使用一个方案,但却不适用于任何其它路径,这根本不是真正的解决方案...」
「神经网络领域的进展令我感到兴奋。它和那些呈指数级增长的技术发展趋势类似,起初并没有什么进展、并没有什么进展... 然后突然间就 Wow~。自驾汽车可能也是这样。」
看看上面那张来自 OpenAI 的图,似乎并没有出现指数级的增长趋势。本质上,以上马斯克的声明应该这样解释:「我们目前并没有能安全实现可以横跨美国的自动驾驶技术,虽然我们可以假装有,如果想的话(可能是这样)。我们非常希望神经网络的能力的指数级增长能很快出现,并把我们从耻辱和大量诉讼中解救出来。」
但目前为止,对 AI 泡沫的最重一击是 Uber 自驾汽车在亚利桑那州撞死行人的事故。从 NTSB 的初步报告中,我们可以看到惊人的论述:

在这份报告中,除了通常的系统设计失败之外,令人惊讶的是它们的系统用了很长的时间来确定它在前面到底看到了什么(那是行人、自行车、汽车,还是别的什么),而不是在这样的场景中做出唯一符合逻辑的决策,即确保不会撞到前面的事物。有这么几个原因:首先,人们通常使用言语表达来传递事实。因此人类通常会这样说:「我看到了一个骑自行车的人,因此我必须左转来避开他。」而大量的心理物理学文献提出相当不同的解释:人类看到的事物在其神经系统的快速感知回路中被很快地理解为障碍,因此他做出了快速回应来避开障碍,在很长时间后他才意识到发生了什么,并提供言语解释。
我们每天都做出了大量未被言语化的决策,在驾驶过程中就包含很多这样的决策。言语化是很费时费力的,现实中通常没有这样的时间。这些经历了十亿年进化而出现的机制让我们保持安全,而驾驶场景(虽然是现代的)使用了很多这样的反射。由于这些反射不是特定为驾驶而演化的,它们可能导致错误。在汽车里由于被胡蜂蛰而导致的膝跳反射可能导致很多事故和死伤。但我们对三维空间、速度的一般理解,预测智能体行为和出现在我们路径上的物理对象行为的能力是一种本能,在一亿年前也发挥着和当前一样的作用,并在进化过程中得到了充分的磨砺。
但是由于这些能力大部分很难用言辞表达,因此我们很难去衡量它们,也无法基于它们优化机器学习系统。现在这只在英伟达的端到端方法上是可行的:学习图像 → 动作映射,该方法跳过了任何言语表达,某种程度上这是正确的做法,但……问题在于输入空间的维度非常高,而动作空间的维度非常低。因此「标签」的「数量」与输入信息量相比非常小。在这种情况下,很容易学到虚假关系,正如深度学习对抗样本中那样。我们需要一种不同的方法,我假设整个感知输入的预测和动作是使系统抽象出世界语义的第一步,而非虚假关系。
事实上,如果我们从深度学习爆发中学到了什么的话,那就是(10k+ 维度的)图像空间中有足够多的虚假模式,以至于它们能够泛化至很多图像,且给人一种印象,即我们的分类器实际上理解它们所看到的事物。这就是事实,甚至 AI 领域顶级研究者也这么认为(参见论文《Measuring the tendency of CNNs to Learn Surface Statistical Regularities》)。根据我的观察,实际上很多顶级研究者不应该那么愤怒,Yann Lecun 曾经提醒过人们对 AI 的过度兴奋以及 AI 寒冬,即使 Geoffrey Hinton 在一次采访中也承认这可能是个死胡同,我们需要重新再来。现在的炒作太厉害了,甚至没有人听该领域创始人的看法。
Gary Marcus 和他对炒作的反对
我应该提一下意识到这种狂妄并敢于公开发表反对意见的人。其中一个活跃人物就是 Gary Marcus。尽管我并不完全认同他在 AI 方面的观点,但是我们有一点共识,即深度学习现状并不如炒作宣传所描绘的图景那样强大。事实上还差得远。参见《Deep Learning: A Critical Appraisal》和《In defense of skepticism about deep learning》,在文章中他非常细致地解构了深度学习炒作。我非常尊重 Gary,他的行为是一个真正的科学家应该做的,而所谓的「深度学习明星」的行为则是廉价的。
结论
预测 AI 寒冬就像预测股市崩盘一样——你不可能知道它什么时候发生,但这是一个必然事件。就像股市崩盘之前一样,大多数人被宣传冲昏了头脑,忽略了熊市的先兆,即使事实就摆在眼前。在我看来,已经有迹象表明深度学习的衰退已经临近(可能在 AI 方面,现在这个名词已经被公司的宣传滥用了),事实是如此的明显,但由于越来越多的宣传报道,大部分人还毫无预料。这样的寒冬会有多「冷」?我不知道。下一个热点是什么?我也不知道。但我非常清楚变革即将来临,而且很快就会发生。

原文链接:https://blog.piekniewski.info/2018/05/28/ai-winter-is-well-on-its-way/





