基础| 实现网页瞬开,indexedDB的这几个基本操作你必须懂
前端爱好者的知识盛宴

嗨
这里是IMWEB
一个想为更多的前端人
享知识
助发展
觅福利
有情怀有情调的公众号
欢迎关注转发
让更多的前端技友一起学习发展~
引语
indexedDB 简介:
indexedDB 是一种使用浏览器存储大量数据的方法。它创造的数据可以被查询,并且可以离线使用。
indexedDB 有以下特点:
1.indexedDB 是 WebSQL 数据库的取代品
2.indexedDB遵循同源协议(只能访问同域中存储的数据,而不能访问其他域的)
3.API包含异步API和同步API两种:多数情况下使用异步API; 同步API必须同 WebWorkers 一起使用, 目前没有浏览器支持同步API
4.indexedDB 是事务模式的数据库, 使用 key-value 键值对储存数据
5.indexedDB 不使用结构化查询语言(SQL). 它通过索引(index)所产生的指针(cursor)来完成查询操作
正文
一、使用indexedDB的基本模式
1.打开数据库并且开始一个事务。
2.创建一个 objecStore。
3.构建一个请求来执行一些数据库操作,像增加或提取数据等。
4.通过监听正确类型的 DOM 事件以等待操作完成。
在操作结果上进行一些操作(可以在 request 对象中找到)
二、创建、打开数据库
indexedDB 存在于全局对象window上, 它最重要的一个方法就是open方法, 该方法接收两个参数:
•dbName // 数据库名称 [string]
•version // 数据库版本 [整型number]
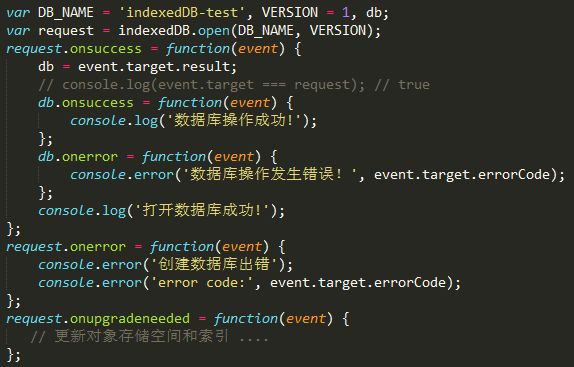
若是本域下不存在名为DB_NAME的数据库,则上述代码会创建一个名为DB_NAME、版本号为VERSION的数据库; 触发的事件依次为: upgradeneeded、 success.
若是已存在名为DB_NAME的数据库, 则上述代码会打开该数据库; 只触发success/error事件,不会触发upgradeneeded事件.
db是对该数据库的引用.
三、创建对象存储空间和索引
在关系型数据库(如mysql)中,一个数据库中会有多张表,每张表有各自的主键、索引等;
在key-value型数据库(如indexedDB)中, 一个数据库会有多个对象存储空间,每个存储空间有自己的主键、索引等;
创建对象存储空间的操作一般放在创建数据库成功回调里:
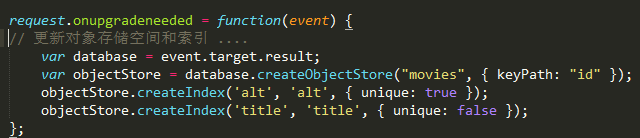
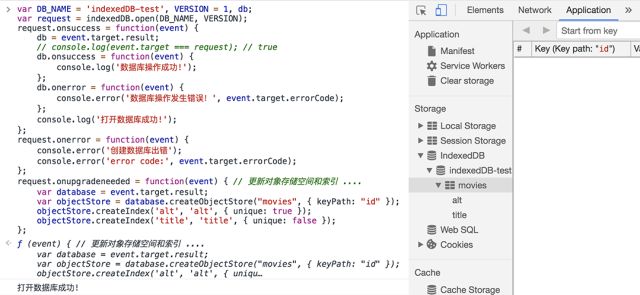
onupgradeneeded 是我们唯一可以修改数据库结构的地方。在这里面,我们可以创建和删除对象存储空间以及构建和删除索引。
在数据库对象database上,有以下方法可供调用:
1.createObjectStore(storeName, configObj) 创建一个对象存储空间
a.storeName // 对象存储空间的名称 [string]
b.configObj // 该对象存储空间的配置 [object] (其中的keyPath属性值,标志对象的该属性值唯一)
2.createIndex(indexName, objAttr, configObj) 创建一个索引
a.indexName // 索引名称 [string]
b.objAttr // 对象的属性名 [string]
c.configObj // 该索引的配置对象 [object]
四、增加和删除数据
对数据库的操作(增删查改等)都需要通过事务来完成,事务具有三种模式:
•readonly 只读(可以并发进行,优先使用)
•readwrite 读写
•versionchange 版本变更
向数据库中增加数据
前面提到,增加数据需要通过事务,事务的使用方式如下:
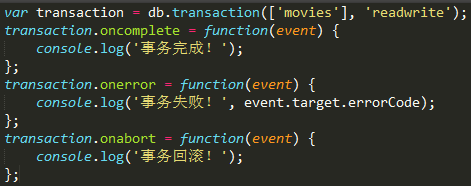

insert-data-web数据库对象的transaction()方法接收两个参数:
•storeNames // 对象存储空间,可以是对象存储空间名称的数组,也可以是单个对象存储空间名称,必传 [array|string]
•mode // 事务模式,上面提到的三种之一,可选,默认值是readonly [string]
这样,我们得到一个事务对象transaction, 有三种事件可能会被触发: complete, error, abort. 现在,我们通过事务向数据库indexedDB-test的 对象存储空间movies中插入数据:
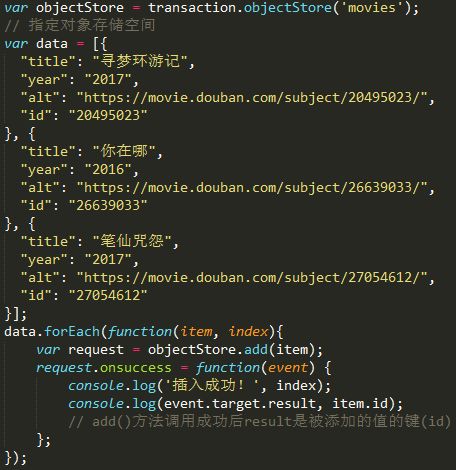
通过事务对象transaction,在objectStore()方法中指定对象存储空间,就得到了可以对该对象存储空间进行操作的对象objectStore.
向数据库中增加数据,add()方法增加的对象,若是数据库中已存在相同的主键,或者唯一性索引的键值重复,则该条数据不会插入进去;
增加数据还有一个方法: put(), 使用方法和add()不同之处在于,数据库中若存在相同主键或者唯一性索引重复,则会更新该条数据,否则插入新数据。
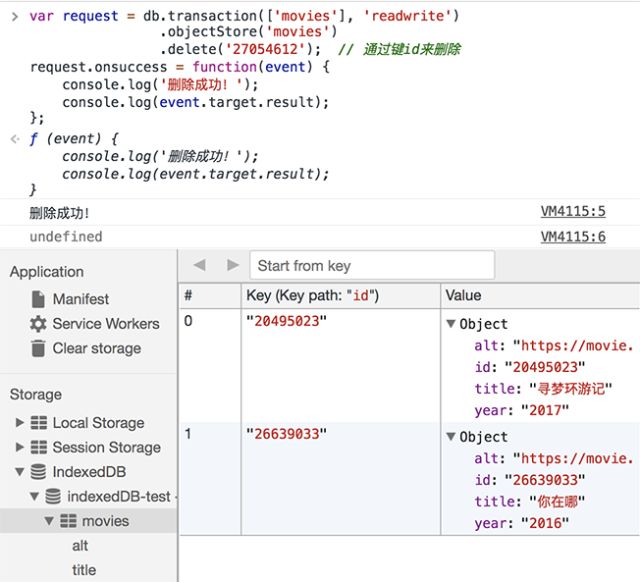
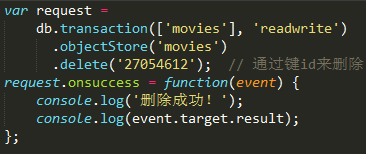
从数据库中删除数据
删除数据使用delete方法,同上类似:
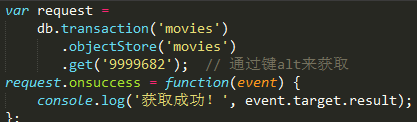
从数据中获取数据
获取数据使用get方法,同上类似:
五、使用索引
在前面,我们创建了两个索引alt和title, 配置对象里面的unique属性标志该值是否唯一
现在我们想找到alt属性值为https://movie.douban.com/subject/26639033/
的对象,就可以使用索引。
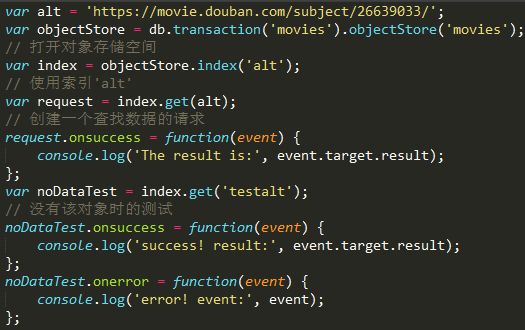
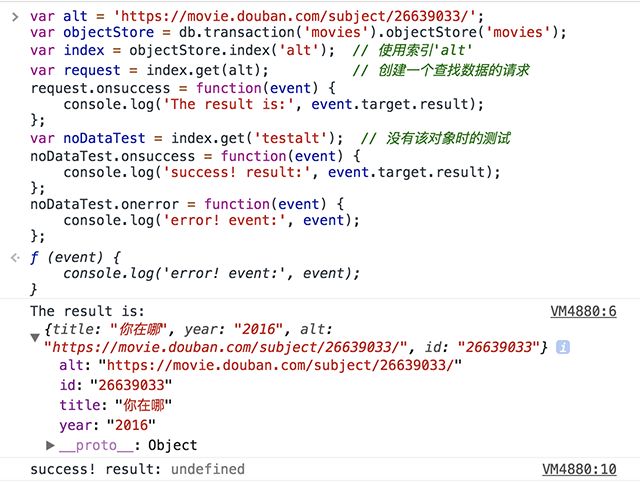
使用唯一性索引,我们可以得到唯一的一条数据(或者undefined),那么使用非唯一性索引呢?
我们向数据库中插入一条数据,使title重复:
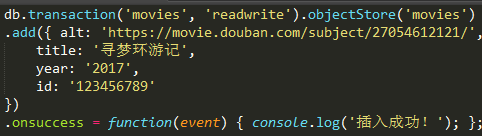
使用索引title获取title值为寻梦环游记的对象:
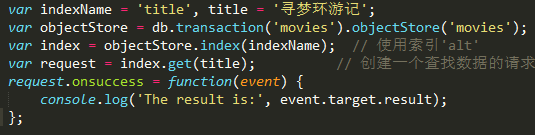
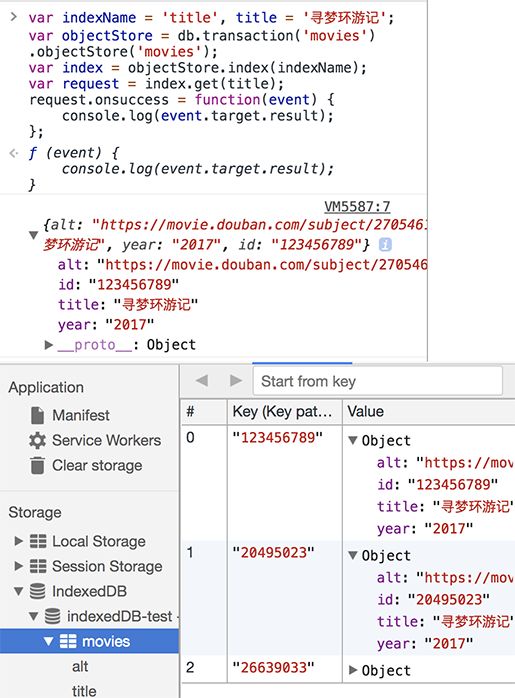
我们得到的是键值最小的那个对象.
使用一次索引,我们只能得到一条数据; 如果我们需要得到所有title属性值为寻梦环游记的对象,我们可以使用游标.
六、使用游标
得到一个可以操作游标的请求对象有两个方法:
•openCursor(keyRange, direction)
•openKeyCursor(keyRange, direction)
这两个方法接收的参数一样, 两个参数都是可选的: 第一个参数是限制值得范围,第二个参数是指定游标方向
游标的使用有以下几处:
•在对象存储空间上使用: var cursor = objectStore.openCursor()
•在索引对象上使用: var cursor = index.openCursor()
在对象存储空间上使用游标
使用游标常见的一种模式是获取对象存储空间上的所有数据.
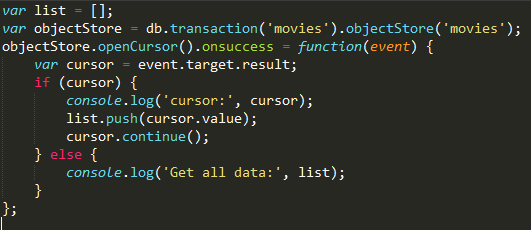

使用游标时,需要在成功回调里拿到result对象,判断是否取完了数据:
若数据已取完,result是undefined;
若未取完,则result是个IDBCursorWithValue对象,需调用continue()方法继续取数据。 也可以根据自己需求, 对数据进行过滤。
在indexedDB2规范中,在对象存储空间对象上纳入了一个getAll()方法,可以获取所有对象:

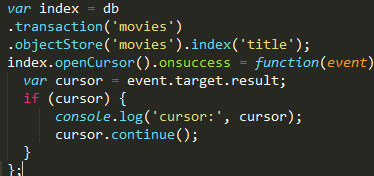
在索引上使用游标
接着本文上述使用索引的例子,在索引title上使用openCursor()方法时,若不传参数,则会遍历所有数据,在成功回调中的到的result对象有以下属性:
•key 数据库中这条对象的title属性值
•primaryKey 数据库中这条对象的alt值
•value 数据库中这条对象
•direction openCursor()方法传入的第二个对象,默认值为next
source IDBIndex对象 举例如下:
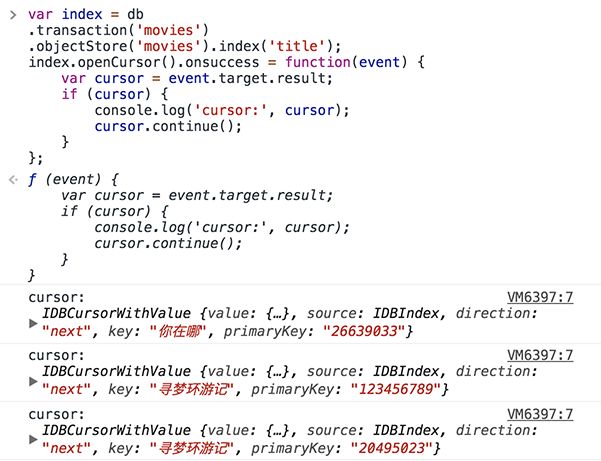
在索引title上使用openKeyCursor()方法,若不传参数,同样也会遍历所有数据,result对象属性如下:
•key 数据库中这条对象的title属性值
•primaryKey 数据库中这条对象的alt值
•direction openCursor()方法传入的第二个对象,默认值为next
•source altBIndex对象
和openCursor()方法相比,得到的数据少一个value属性,是没有办法得到存储对象的其余部分
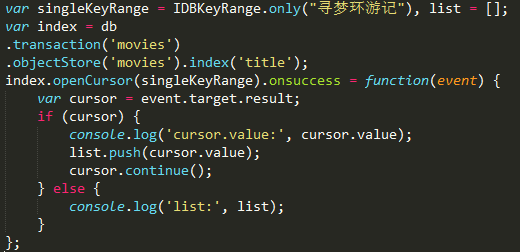
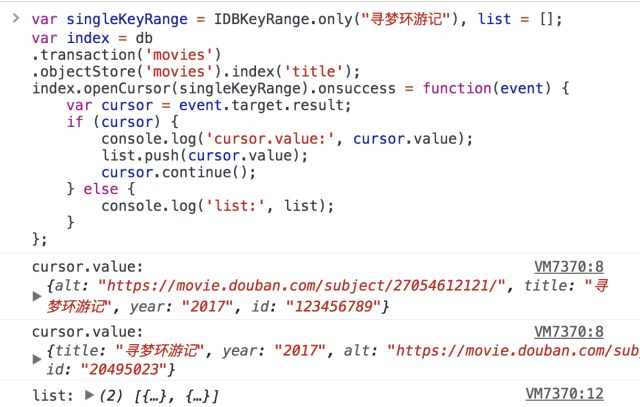
前面说到,我们要根据索引title获取所有title属性值为寻梦环游记的对象,要使用游标,而又不想遍历所有数据,这时就要用到openCursor()的第一个参数:keyRange
keyRange是限定游标遍历的数据范围,通过IDBKeyRange的一些方法设置该值:
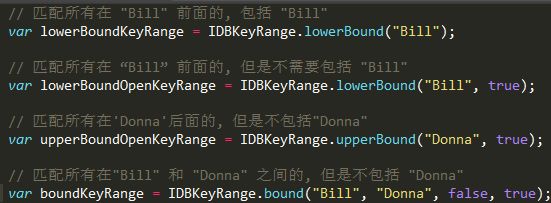
IDBKeyRange其他一些方法:
更多请参考 MDN|IDBKeyRange
游标默认遍历方向是按主键从小到大,有时候我们倒序遍历,此时可以给openCursor()方法传递第二个参数: direction: next|nextunique|prev|prevunique
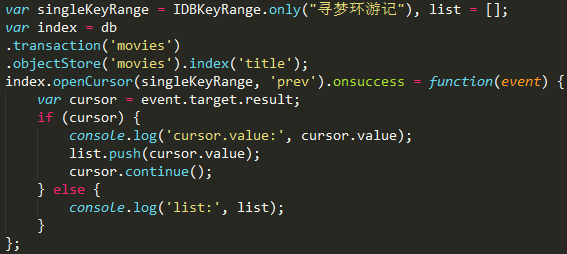
传了prev的结果是按倒序遍历的.
因为 “name” 索引不是唯一的,那就有可能存在具有相同 name 的多条记录。 要注意的是这种情况不可能发生在对象存储空间上,因为键必须永远是唯一的。
如果你想要在游标在索引迭代过程中过滤出重复的,你可以传递 nextunique(或prevunique, 如果你正在向后寻找)作为方向参数。 当 nextunique 或是 prevunique 被使用时,被返回的那个总是键最小的记录。
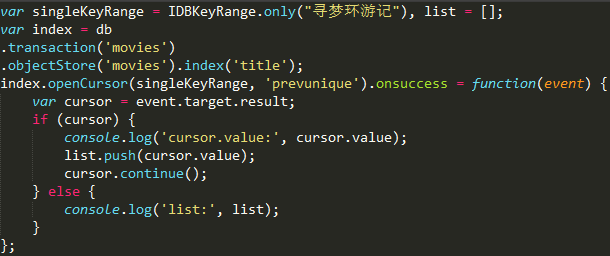
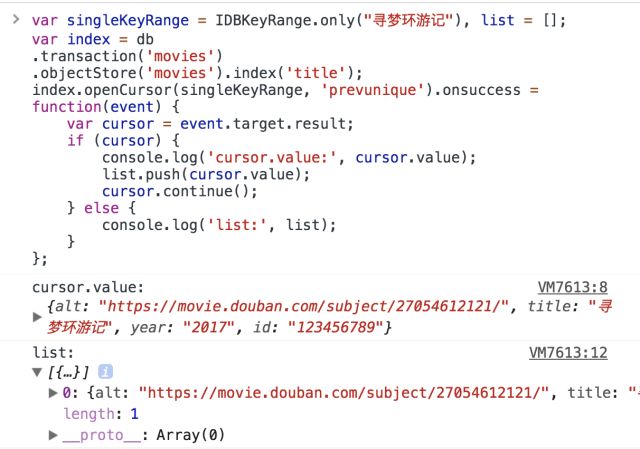
七、关闭和删除数据库
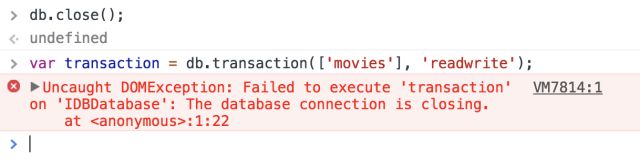
关闭数据库只需要在数据库对象db上调用close()方法即可
db.close();
关闭数据库后,db对象仍然保存着该数据库的相关信息,只是无法再开启事务(调用开启事务方法会报错,提示数据库连接已断开):
删除数据库则需要使用indexedDB.deleteDatabase(dbName)方法
window.indexedDB.deleteDatabase(dbName);
八、indexedDB的局限性
以下情况不适合使用IndexedDB:
•全球多种语言混合存储。国际化支持不好。需要自己处理。
•和服务器端数据库同步。你得自己写同步代码。
•全文搜索。
注意,在以下情况下,数据库可能被清除:
•用户请求清除数据。
•浏览器处于隐私模式。最后退出浏览器的时候,数•据会被清除。
•硬盘等存储设备的容量到限。
•不正确的
•不完整的改变.
总结
1.使用indexedDB.open(dbName, version)打开一个数据库连接
2.使用indexedDB.deleteDatabase(dbName)删除一个数据库
3.在数据库对象db上使用createObjectStore(storeName, config)创建对象存储空间
4.在对象存储空间objectStore上使用createIndex(indexName, keyName, config)创建索引
5.对数据库的操作都需要通过事务完成: var transction = db.transaction([storeName], mode)
6.数据库的增删改查均通过objectStore对象完成,var objectStore = transaction.objectStore(storeName)
7.对数据库数据操作有: add()、get()、delete()、put等方法
8.查找数据可以使用索引: objectStore.index(indexName)
9.遍历和过滤数据可以使用游标: openCursor(keyRange, direction)
参考
•IndexedDB的基本概念-MDN
•使用 IndexedDB-MDN
•IndexedDB API接口-MDN
•Indexed Database API 2.0 – w3c
关注小编
留言夸夸小编
转发文章给小编加鸡腿
跟更多的人一起学习
让我们又爱又恨的前端