修补DBA短板:监控SQL优化案例两则

作者介绍
蒋健,云趣网络科技联合创始人,11g OCM,多年Oracle设计、管理及实施经验,精通数据库优化,Oracle CBO及并行原理,曾为多个行业的客户的Oracle系统实施小型机到X86跨平台迁移和数据库优化服务。云趣鹰眼监控核心设计和开发者,资深Python Web开发者。
一、表空间信息查询慢
前几天跟销售拜访潜在客户时,客户提到他们近期很头疼的问题:他们自己写的一个查询表空间的语句从上周开始跑不出来了,做了很多尝试未果,比较苦恼,毕竟作为DBA不知道库的空间使用情况,客户心里是有点发毛的。
听完客户描述,我也马上回复说这个问题很常见,都在我们日常巡检的范围内,解决起来很简单。一般查询表空间的语句都是用到了DBA_FREE_SPACE这张视图,查询起来慢,常见原因一般如下:
数据字典信息/固化视图统计信息过旧;
回收栈内对象过多。
处理方式:
exec dmbs_stats.gather_fixed_objects_stats;
exec dbms_stats.gather_dictionary_stats(degree =>8,cascade =>true);
purge recyclebin;
客户听完介绍的解决方案,表示认同并希望现场帮他们处理好问题,热情地带我去他的工位。虽然库并非生产数据库,但访问这个库依然需要通过堡垒机,而且命令需要手敲。
客户通过shell脚本SQLplus进入数据库后运行语句类似以下SQL:
SELECT UPPER(F.TABLESPACE_NAME) AS "表空间名称",
ROUND(D.AVAILB_BYTES ,2) AS "表空间大小(G)",
ROUND(D.MAX_BYTES,2) AS "最终表空间大小(G)",
ROUND((D.AVAILB_BYTES - F.USED_BYTES),2) AS "已使用空间(G)",
TO_CHAR(ROUND((D.AVAILB_BYTES - F.USED_BYTES) / D.AVAILB_BYTES * 100,
2), '999.99') AS "使用比",
ROUND(F.USED_BYTES, 6) AS "空闲空间(G)",
F.MAX_BYTES AS "最大块(M)"
FROM (
SELECT TABLESPACE_NAME,
ROUND(SUM(BYTES) / (1024 * 1024 * 1024), 6) USED_BYTES,
ROUND(MAX(BYTES) / (1024 * 1024 * 1024), 6) MAX_BYTES
FROM SYS.DBA_FREE_SPACE
GROUP BY TABLESPACE_NAME) F,
(SELECT DD.TABLESPACE_NAME,
ROUND(SUM(DD.BYTES) / (1024 * 1024 * 1024), 6) AVAILB_BYTES,
ROUND(SUM(DECODE(DD.MAXBYTES, 0, DD.BYTES, DD.MAXBYTES))/(1024*1024*1024),6) MAX_BYTES
FROM SYS.DBA_DATA_FILES DD
GROUP BY DD.TABLESPACE_NAME) D
WHERE D.TABLESPACE_NAME = F.TABLESPACE_NAME
ORDER BY 4 DESC
客户运行了脚本,果然卡住了一样,无返回结果。演示完,客户让出了座位,示意我可以上机操作了。因为不是生产库,客户也表示可以随意操作,于是没有去进一步确认信息,顺利完成了上面列的操作。
客户开始验证效果的时候,比较尴尬,依然卡在那儿。客户地方没有监控,也没有我习惯的脚本,客户打开plSQLdeveloper后,我看了一下在运行的SQL等待事件是单块儿读,我有点犹豫要不要手敲那些工具SQL的时候,有趣的地方也来了~ 客户的DBA开始讨论起了原因:
一个客户DBA说,他觉得是IO太慢,因为库不是放在存储上的,而且raid可能用的是raid 5之类。
另一个客户DBA说,可能是数据库太大了,性能有影响。
为了避免问题走偏,我快速打了个快照,做了awr报告,确认了一下单块读约3ms,数据文件个数约800个。证伪了以上假设。
那到底为什么SQL查询还是不快呢?我有点犹豫,毕竟堡垒机命令都手敲不能直接跑自己的脚本包。客户主要负责的DBA此时主动给台阶让我下,让我找时间再看看,回去了再研究,毕竟他们也快下班了。
这个台阶当然不能下…… 在10046跟moitor报告中,个人还是更倾向monitor报告,于是脚本加了monitor的hint,打算再跑一次。另外一个会话准备编写脚本的时候,SQL瞬间出了结果。常用脚本这里也贴一下:
set pagesize 0 echo off timing off linesize 1000 trimspool on trim on long 2000000 longchunksize 2000000 feeDBAck off
spool &1..&2
--active/html/EM
select dbms_SQLtune.report_SQL_monitor(type=>'&2', SQL_id=>'&1', SQL_exec_id=>null, report_level=>'ALL') monitor_report from dual;
spool off
客户DBA说这个hint有效果,但是我也不打算糊弄客户,跟客户解释了这个hint跟跑起来快了没什么关系,并用 /*+ xxx */这个改动,再次运行,果然也很快。客户运行原来的语句,依然跑不出来。这时候,基本已经知道原因了。
虽然讲道理,收集了统计,SQL的执行计划应该是会失效,并重新解析的,这里显然那个SQL的执行计划应该还是原来的,没有变动。考虑到不是生产库,就直接flush了shared pool。再次运行那个问题SQL,顺利秒出结果。
二、ASH信息采集慢
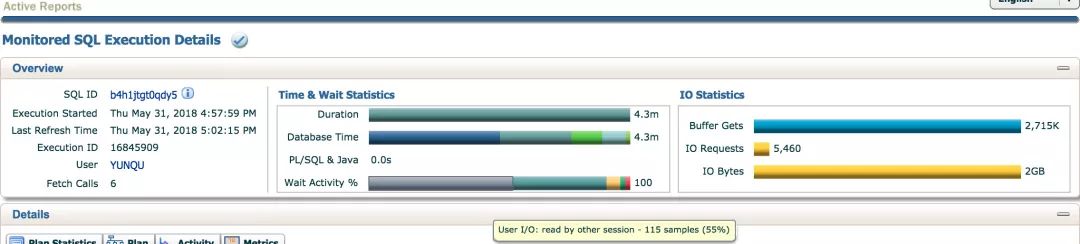
某客户反馈监控上线后,在监控的数十套数据库中有一套库监控SQL的数据库时间占比较高,监控自身显示是一条采集ASH数据的语句。经过了解,其他库该语句执行均在1s以内,在其中一个数据库上运行时间可达4分钟,监控中我们马上发现了该SQL的监视报告。
打开报告,通过Wait Activity中可发现55%时间是read by other session等待事件,还有36%为gc相关等待事件,结合2GB的IO,可以基本可知问题原因为SQL读取IO量过多,在RAC高并发环境下,性能问题被放大。
那么,这2GB的IO来源于哪儿呢?执行计划很长,截取部分如下:
第一部分IO占54%来源WRH$_ACTIVE_SESSION_HISTORY:

第二部分IO占46%来源WRH$_ACTIVE_SESSION_HISTORY:

通过报告可明显观察到整个SQL消耗的IO基本来源于WRH$_ACTIVE_SESSION_HISTORY这张表。监视报告中选中plan,再以Tabular方式查看,可查看访问表的谓词,正常情况下这个表是会分区的,目前看起来数据都集中在了一个分区。
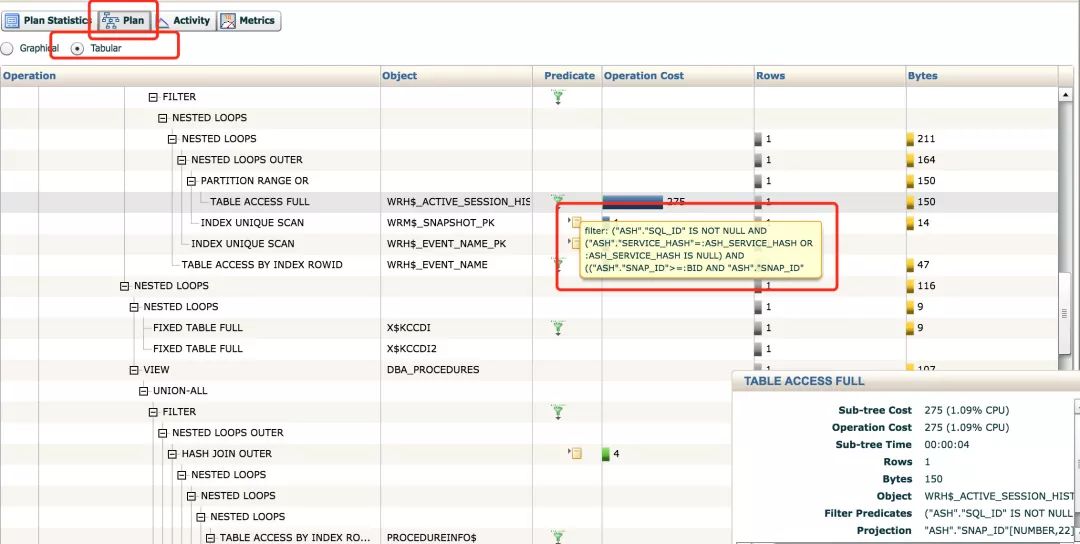
运行以下代码段确认信息:
(上下滑动查看完整代码)
如下可发现表并自动未分区:
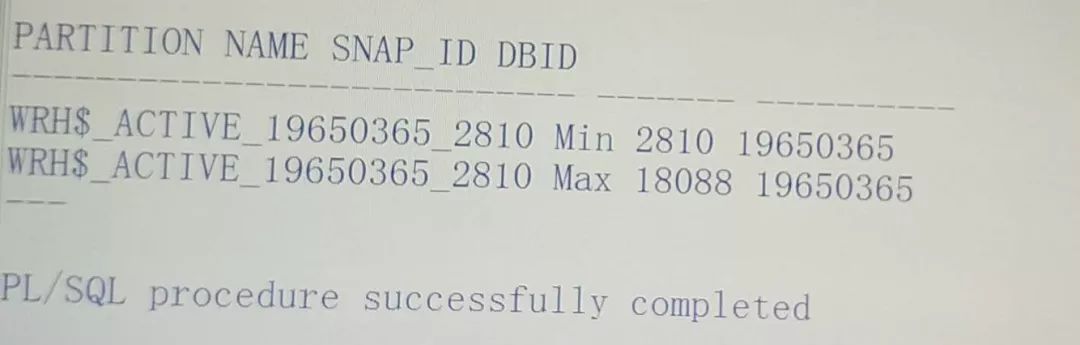
正常情况下分区是自动创建并清理的,如下:
PARTITION NAME SNAP_ID DBID
--------------------------- ------- ----------
WRH$_ACTIVE_1489418862_4171 Min 4180 1489418862
WRH$_ACTIVE_1489418862_4171 Max 4181 1489418862
---
WRH$_ACTIVE_1489418862_4182 Min 4182 1489418862
WRH$_ACTIVE_1489418862_4182 Max 4194 1489418862
---
WRH$_ACTIVE_1489418862_4195 Min 4195 1489418862
WRH$_ACTIVE_1489418862_4195 Max 4218 1489418862
---
WRH$_ACTIVE_1489418862_4219 Min 4219 1489418862
WRH$_ACTIVE_1489418862_4219 Max 4242 1489418862
---
WRH$_ACTIVE_1489418862_4243 Min 4243 1489418862
WRH$_ACTIVE_1489418862_4243 Max 4266 1489418862
---
WRH$_ACTIVE_1489418862_4267 Min 4267 1489418862
WRH$_ACTIVE_1489418862_4267 Max 4290 1489418862
---
WRH$_ACTIVE_1489418862_4291 Min 4291 1489418862
WRH$_ACTIVE_1489418862_4291 Max 4314 1489418862
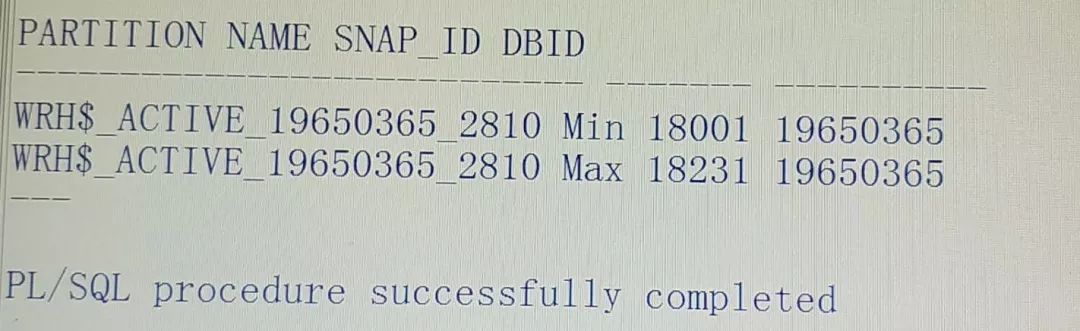
以下为清除ASH数据的方式:
exec DBMS_WORKLOAD_REPOSITORY.DROP_SNAPSHOT_RANGE(low_snap_id =>2810,high_snap_id =>18000);
alter table WRH$_ACTIVE_SESSION_HISTORY shrink space;
DROP_SNAPSHOT_RANGE 处理方式上本质为delete相关数据,实际执行时间很长(这次夜间执行用了6小时),shrink操作也是执行了半个小时。可以考虑直接把这个大分区truncate掉(当然会丢部分性能数据)。
上述操作完成后,SQL已经能秒出了,然而源头问题分区表WRH$_ACTIVE_SESSION_HISTORY 是否能自动新建分区,并自动清理过期ASH数据通过以下命令(官方推荐处理方式,参考文档 387914.1)并不一定达到想要的效果。
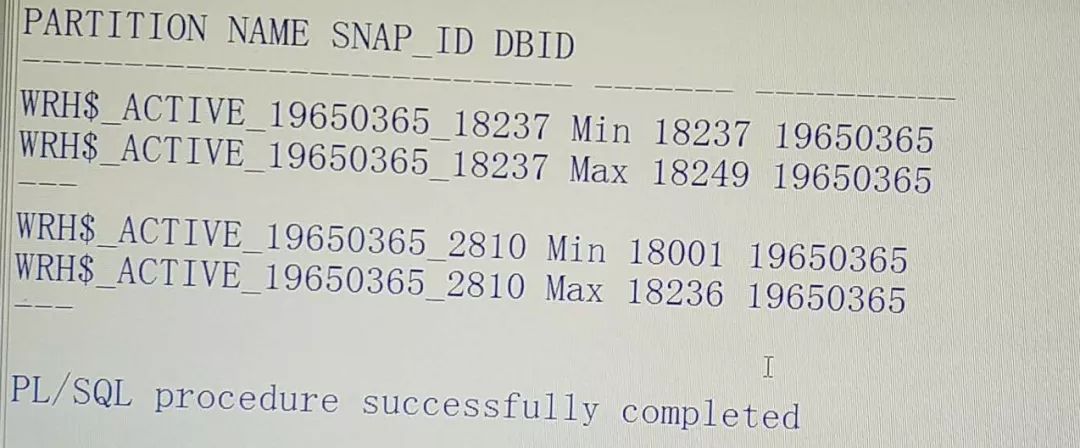
本文处理时有点经验主义,这步操作没抱太大期望,结果顺利达到预期效果。也有相当部分场景执行命令后还是不能自动分区,这时候,没错要打补丁了。数据库版本从11.2.0.2到12.1.0.1,可在线打。


近期热文
近期活动






