Gary Marcus | 提出对深度学习的系统性批判,指明其面临的十大挑战

在人们对于AI技术的应用逐步走向正轨的同时,人工智能的先驱者们却早已将目光投向远方。2018年伊始,纽约大学教授、前Uber AI Lab主管Gary Marcus就发表了一篇长文对深度学习的现状及局限性进行了批判性探讨。在文中,Marcus表示:我们必须走出深度学习,这样才能迎来真正的通用人工智能。
文章地址:https://arxiv.org/ftp/arxiv/papers/1801/1801.00631.pdf

Gary Marcus在机器之心GMIS 2017大会上
尽管深度学习历史可追溯到几十年前,但这种方法,甚至深度学习一词都只是在5年前才刚刚流行,也就是该领域被类似于Krizhevsky、Sutskever和Hinton等人合作的论文这样的研究成果重新点燃的时候。他们的论文如今是ImageNet上经典的深度网络模型。
在随后5年中,该领域都发现了什么?在语音识别、图像识别、游戏等领域有可观进步,主流媒体热情高涨的背景下,我提出了对深度学习的十点担忧,且如果我们想要达到通用人工智能,我建议要有其他技术补充深度学习。
在深度学习衍生出更好解决方案的众多问题上(视觉、语音),在2016-2017期间而变得收效衰减。——François Chollet, Google, Keras 作者,2017.12.18
「科学是踩着葬礼前行的」,未来由极其质疑我所说的一切的那批学生所决定。——Geoffrey Hinton,深度学习教父,谷歌大脑负责人,2017.9.15
1. 深度学习撞墙了?
尽管,深度学习的根源可追溯到几十年前(Schmidhuber,2015),但直到5年之前,人们对于它的关注还极其有限。2012年,Krizhevsky、Sutskever和Hinton发布论文ImageNet Classification with Deep Convolutional Neural Networks (Krizhevsky, Sutskever, & Hinton, 2012),在ImageNet目标识别挑战赛上取得了顶尖结果(Deng et al.)。随着这样的一批高影响力论文的发表,一切都发生了本质上的变化。当时,其他实验室已经在做类似的工作(Cireşan, Meier, Masci,&Schmidhuber, 2012)。在2012年将尽之时,深度学习上了纽约时报的头版。然后,迅速蹿红成为人工智能中最知名的技术。训练多层神经网络的思路并不新颖(确实如此),但因为计算力与数据的增加,深度学习第一次变得实际可用。
自此之后,深度学习在语音识别、图像识别、语言翻译这样的领域产生了众多顶尖成果,且在目前众多的AI应用中扮演着重要的角色。大公司也开始投资数亿美元挖深度学习人才。深度学习的一位重要拥护者,吴恩达,想的更远并说到,「如果一个人完成一项脑力任务需要少于一秒的考虑时间,我们就有可能在现在或者不久的未来使用AI使其自动化。」(A,2016)。最近纽约时报星期天杂志的一篇关于深度学习的文章,暗示深度学习技术「做好准备重新发明计算本身」。
如今,深度学习可能临近墙角,大部分如同前面我在深度学习崛起之时(Marcus 2012)预期到的,也如同Hinton(Sabour, Frosst, & Hinton, 2017)、Chollet(2017)这样的重要人物近几月来暗示的那样。
深度学习到底是什么?它展示了智能的什么特性?我们能期待它做什么?预计什么时候它会不行?我们离「通用人工智能」还有多远?多近?在解决不熟悉的问题上,什么时候机器能够像人类一样灵活?该文章的目的既是为了缓和非理性的膨胀,也是为了考虑需要前进的方向。
该论文同时也是写给该领域的研究人员,写给缺乏技术背景又可能想要理解该领域的AI消费者。如此一来,在第二部分我将简要地、非技术性地介绍深度学习系统能做什么,为什么做得好。然后在第三部分介绍深度学习的弱点,第四部分介绍对深度学习能力的误解,最后介绍我们可以前进的方向。
深度学习不太可能会消亡,也不该消亡。但在深度学习崛起的5年后,看起来是时候对深度学习的能力与不足做出批判性反思了。
2. 深度学习是什么?深度学习能做好什么?
深度学习本质上是一种基于样本数据、使用多层神经网络对模式进行分类的统计学技术。深度学习文献中的神经网络包括一系列代表像素或单词的输入单元、包含隐藏单元(又叫节点或神经元)的多个隐藏层(层越多,网络就越深),以及一系列输出单元,节点之间存在连接。在典型应用中,这样的网络可以在大型手写数字(输入,表示为图像)和标签(输出,表示为图像)集上进行训练,标签代表输入所属的类别。
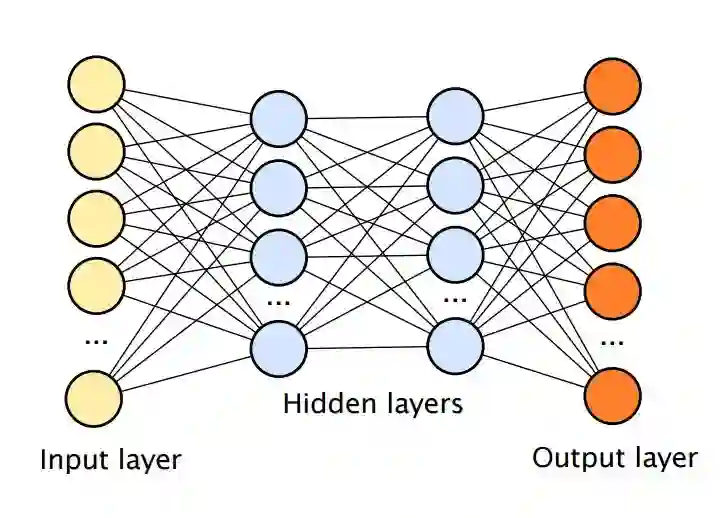
随着时间的进展,一种叫作反向传播的算法出现了,它允许通过梯度下降过程调整单元之间的连接,以使任意给定输入可以有对应的输出。
大体上,我们可以把神经网络所学习的输入与输出之间的关系理解为映射。神经网络,尤其是具备多个隐藏层的神经网络尤其擅长学习输入-输出映射。
此类系统通常被描述为神经网络,因为输入节点、隐藏节点和输出节点类似生物神经元,不过已经大大简化。节点之间的连接类似神经元之间的连接。
大部分深度学习网络大量使用卷积技术(LeCun, 1989),该技术约束网络中的神经连接,使它们本能地捕捉平移不变性(translational invariance)。这本质上就是物体可以围绕图像滑动,同时又保持自己的特征;正如上图中,假设它是左上角的圆,即使缺少直接经验,也可以最终过渡到右下角。
深度学习还有一个著名的能力——自生成中间表示,如可以响应横线或图结构中更复杂元素的内部单元。
原则上,对于给定的无限多数据,深度学习系统能够展示给定输入集和对应输出集之间的有限确定性「映射」,但实践中系统是否能够学习此类映射需要依赖于很多因素。一个常见的担忧是局部极小值陷阱,即系统陷入次最优解,附近求解空间内没有更好的解。(专家使用多种技术避免此类问题,达到了比较好的效果。)在实践中,大型数据集的结果通常比较好,因其具备大量可能的映射。
例如,语音识别中,神经网络学习语音集和标签(如单词或音素)集之间的映射。目标识别中,神经网络学习图像集和标签集之间的映射。在DeepMind的Atari游戏系统(Mnih et al., 2015)中,神经网络学习像素和游戏杆位置之间的映射。
深度学习系统最常用作分类系统,因其使命是决定给定输入所属的类别(由神经网络的输出单元定义)。只要有足够的想象力,那么分类的能力是巨大的;输出可以表示单词、围棋棋盘上的位置等几乎所有事物。
在拥有无限数据和计算资源的世界,可能就不需要其他技术了。
3. 深度学习的局限性
深度学习的局限性首先是这个逆否命题:我们居住的世界具备的数据并不是无穷多的。依赖于深度学习的系统经常要泛化至未见过的数据,这些数据并不是无穷大的,确保高质量性能的能力更是有限。
我们可以把泛化当作已知样本之间的内插和超出已知训练样本空间的数据所需的外插(Marcus, 1998a)。
对于泛化性能良好的神经网络,通常必须有大量数据,测试数据必须与训练数据类似,使新答案内插在旧的数据之中。在Krizhevsky等人的论文(Krizhevsky, Sutskever, & Hinton, 2012)中,一个具备6000万参数和65万节点的9层卷积神经网络在来自大概1000个类别的约100万不同样本上进行训练。
这种暴力方法在ImageNet这种有限数据集上效果不错,所有外部刺激都可以被分类为较小的类别。它在稳定的领域效果也不错,如在语音识别中,数据可以一种常规方式映射到有限的语音类别集中,但是出于很多原因,深度学习不是人工智能的通用解决方案。
以下是当前深度学习系统所面临的十个挑战:
3.1 目前深度学习需要大量数据
人类只需要少量的尝试就可以学习抽象的关系。如果我告诉你schmister是年龄在10岁到21岁之间的姐妹。可能只需要一个例子,你就可以立刻推出你有没有schmister,你的好朋友有没有schmister,你的孩子或父母有没有schmister等等。
你不需要成百上千甚至上百万的训练样本,只需要用少量类代数的变量之间的抽象关系,就可以给schmister下一个准确的定义。
人类可以学习这样的抽象概念,无论是通过准确的定义还是更隐式的手段(Marcus,2001)。实际上即使是7月大的婴儿也可以仅在两分钟内从少量的无标签样本中学习抽象的类语言规则(Marcus, Vijayan, Bandi Rao, & Vishton, 1999)。随后由Gervain与其同事做出的研究(2012)表明新生儿也能进行类似的学习。
深度学习目前缺少通过准确的、语词的定义学习抽象概念的机制。当有数百万甚至数十亿的训练样本的时候,深度学习能达到最好的性能,例如DeepMind在棋牌游戏和Atari上的研究。正如Brenden Lake和他的同事最近在一系列论文中所强调的,人类在学习复杂规则的效率远高于深度学习系统(Lake, Salakhutdinov, &Tenenbaum, 2015; Lake, Ullman, Tenenbaum, &Gershman, 2016)(也可以参见George等人的相关研究工作,2017)。我和Steven Pinker在儿童与神经网络的过度规则化误差的对比研究也证明了这一点。
Geoff Hinton也对深度学习依赖大量的标注样本表示担忧,在他最新的Capsule网络研究中表达了这个观点,其中指出卷积神经网络可能会遭遇「指数低效」,从而导致网络的失效。还有一个问题是卷积网络在泛化到新的视角上有困难。处理转换(不变性)的能力是网络的内在性质,而对于其他常见类型的转换不变性,我们不得不在网格上的重复特征检测器之间进行选择,该过程的计算量是指数式增长的,或者增加标记训练集的规模,其计算量也是指数式增长的。
对于没有大量数据的问题,深度学习通常不是理想的解决方案。
3.2 深度学习目前还是太表浅,没有足够的能力进行迁移
这里很重要的一点是,需要认识到「深」在深度学习中是一个技术的、架构的性质(即在现代神经网络中使用大量的隐藏层),而不是概念上的意义(即这样的网络获取的表征可以自然地应用到诸如「公正、「民主」或「干预」等概念)。
即使是像「球」或「对手」这样的具体概念也是很难被深度学习学到的。考虑DeepMind利用深度强化学习对Atari游戏的研究,他们将深度学习和强化学习结合了起来。其成果表面上看起来很棒:该系统使用单个「超参数」集合(控制网络的性质,如学习率)在大量的游戏样本中达到或打败了人类专家,其中系统并没有关于具体游戏的知识,甚至连规则都不知道。但人们很容易对这个结果进行过度解读。例如,根据一个广泛流传的关于该系统学习玩打砖块Atari游戏Breakout的视频,「经过240分钟的训练,系统意识到把砖墙打通一个通道是获得高分的最高效的技术。」
但实际上系统并没有学到这样的思维:它并不理解通道是什么,或者砖墙是什么;它仅仅是学到了特定场景下的特定策略。迁移测试(其中深度强化学习系统需要面对和训练过程中稍有不同的场景)表明深度强化学习方法通常学到很表明的东西。例如,Vicarious的研究团队表明DeepMind的更高效的进阶技术——Atari系统「Asynchronous Advantage Actor-Critic」(也叫A3C)在玩多种Breakout的微改动版本(例如改变球拍的Y坐标,或在屏幕中央加上一堵墙)时遭遇了失败。这些反例证明了深度强化学习并不能学习归纳类似砖墙或球拍这样的概念;更准确地说,这样的评论就是生物心理学中的过度归因所造成的Atari系统并没有真正地学习到关于砖墙的鲁棒的概念,而只是在高度训练的情景的狭隘集合中表面地打破了砖墙。
我在初创公司Geometric Intelligence的研究团队(后来被Uber收购)的滑雪游戏情景中发现了类似的结果。2017年,伯克利和OpenAI的一个研究团队发现可以轻易地在多种游戏中构造对抗样本,使得DQN(原始的 DeepMind 算法)、A3C和其它的相关技术(Huang, Papernot, Goodfellow, Duan, &Abbeel, 2017)都失效。
最近由Robin Jia和Percy Liang(2017)做的实验在不同的领域(语言)表明了类似的观点。他们训练了多种用于问答系统任务(被称为 SQuAD,Stanford Question Answering Database)的神经网络,其中任务的目标是在特定的段落中标出和给定问题相关的单词。例如,有一个已训练系统可以基于一段短文准确地识别出超级碗XXXIII的胜利者是John Elway。但jia和Liang表明仅仅插入干扰句(例如宣称谷歌的Jeff Dean在另一个杯赛中获得了胜利)就可以让准确率大幅下降。在16个模型中,平均准确率从75%下降了到了36%。
通常情况下,深度学习提取的模式,相比给人的第一印象,其实更加的表面化。
3.3 迄今深度学习没有自然方式来处理层级架构
对乔姆斯基这样的语言学家来说,对Robin Jia和Percy Liang记录的难题并不惊讶。基本上,目前大部分深度学习方法基于语言模型来将句子表达为纯粹的词序列。然而,乔姆斯基一直以来都认为语言具有层级架构,也就是小的部件循环构建成更大的结构。(例如,在句子「the teenager who previously crossed the Atlantic set a record for flying around the world」中,主句是「the teenager set a record for flying around the world」,「who previously crossed the Atlantic」是指明青年身份的一个字句。
在上世纪80年代,Fodor和Pylyshyn(1988)也表达了同样的担忧,这是关于神经网络的一个早期分支。我在2001年的文章中也同样揣测到,单个循环神经网络(SRN;是今天基于循环神经网络(也就是 RNN)的更复杂的深度学习方法的前身;Elman,1990) 难以系统表达、扩展各种不熟悉语句的递归结构(从引用论文查看具体是哪种类型)。
2017早些时候,Brenden Lake和Marco Baroni测试了这样的悲观揣测是否依然正确。就像他们文章标题中写的,当代神经网络「这么多年来依然不体系」。RNN可能「在训练与测试差别... 很小的时候泛化很好,但当需要系统地组合技能做泛化时,RNN极其失败。」
类似的问题在其他领域也可能会暴露出来,例如规划与电机控制,这些领域都需要复杂的层级结构,特别是遇到全新的环境时。从上面提到的Atari游戏AI难以迁移问题上,我们可以间接看到这一点。更普遍的是在机器人领域,系统一般不能在全新环境中概括抽象规划。
至少,目前深度学习显现的核心问题是它学习特征集相对平滑或者说非层级的关联关系,犹如简单的、非结构化列表,每个特征都平等。层级结构(例如,句子中区分主句和从句的语法树)在这样的系统中并不是固有的,或者直接表达的,结果导致深度学习系统被迫使用各种根本不合适的代理,例如句子中单词的序列位置。
像Word2Vec(Mikolov, Chen, Corrado, &Dean, 2013) 这样的系统将单个单词表达为向量,有适当的成功。也有一批系统使用小技巧试图在深度学习可兼容的向量空间中表达完整语句 (Socher, Huval, Manning, &Ng, 2012)。但是,就像Lake和Baroni的实验表明的,循环网络能力依然有限,不足以准确可靠地表达和概括丰富的结构信息。
3.4 迄今为止的深度学习无法进行开放推理
如果你无法搞清「John promised Mary to leave」和「John promised to leave Mary」之间的区别,你就不能分清是谁离开了谁,以及接下来会发生什么。目前的机器阅读系统已经在一些任务,如SQuAD上取得了某种程度的成功,其中对于给定问题的答案被明确地包含在文本中,或者整合在多个句子中(被称为多级推理)或整合在背景知识的几个明确的句子中,但并没有标注特定的文本。对于人类来说,我们在阅读文本时经常可以进行广泛的推理,形成全新的、隐含的思考,例如仅仅通过对话就能确定角色的意图。
尽管Bowman等人(Bowman,Angeli,Potts&Manning,2015;Williams,Nangia&Bowman,2017)在这一方向上已经采取了一些重要步骤,但目前来看,没有深度学习系统可以基于真实世界的知识进行开放式推理,并达到人类级别的准确性。
3.5 迄今为止的深度学习不够透明
神经网络「黑箱」的特性一直是过去几年人们讨论的重点(Samek、Wiegand & Müller,2017;Ribeiro、Singh & Guestrin,2016)。在目前的典型状态里,深度学习系统有数百万甚至数十亿参数,其开发者可识别形式并不是常规程序员使用的(「last_character_typed」)人类可识别标签,而是仅在一个复杂网络中适用的地理形式(如网络模块k中第j层第i个节点的活动值)。尽管通过可视化工具,我们可以在复杂网络中看到节点个体的贡献(Nguyen、Clune、Bengio、Dosovitskiy&Yosinski,2016),但大多数观察者都认为,神经网络整体看来仍然是一个黑箱。
从长远看来,目前这种情况的重要性仍不明确(Lipton,2016)。如果系统足够健壮且自成体系,则没有问题;如果神经网络在更大的系统中占据重要的位置,则其可调试性至关重要。
为解决透明度问题,对于深度学习在一些领域如金融或医疗诊断上的潜力是致命的,其中人类必须了解系统是如何做出决策的。正如Catherine O. Neill(2016)指出的,这种不透明也会导致严重的偏见问题。
3.6 迄今为止,深度学习并没有很好地与先验知识相结合
深度学习的一个重要方向是解释学,就是将自身与其他潜在的、有用的知识隔离开来。深度学习的工作方式通常包含寻找一个训练数据集,与输入相关联的各个输出,通过任何精巧的架构或变体,以及数据清理和/或增强技术,随后通过学习输入和输出的关系来学会解决问题的方法。这其中只有少数几个例外,如LeCun对神经网络连接卷积约束的研究(LeCun,1989)中,先验知识被有意最小化了。
因此,例如Lerer等人(2016)提出的系统学习从塔上掉落物体的物理性质,在此之上并没有物理学的先验知识(除卷积中所隐含的内容之外)。在这里,牛顿定律并没有被编码,系统通过(在一些有限的层面上)通过原始像素级数据学习了这一定律,并近似它们。正如在我即将发表的论文中所指出的那样,深度学习研究者似乎对于先验知识有着很强的偏见,即使(如在物理上)这些先验知识是众所周知的。
一般来说,将先验知识整合到深度学习系统中并不简单:一部分是因为深度学习系统中的知识表征主要是特征之间的关系(大部分还是不透明的),而非抽象的量化陈述(如凡人终有一死),参见普遍量化一对一映射的讨论(Marcus,2001),或 generics(可违反的声明,如狗有四条腿或蚊子携带尼罗河病毒(Gelman、Leslie、Was&Koch,2015))。
这个问题根植于机器学习文化中,强调系统需要自成一体并具有竞争力——不需要哪怕是一点先验的通用知识。Kaggle机器学习竞赛平台正是这一现象的注解,参赛者争取在给定数据集上获取特定任务的最佳结果。任意给定问题所需的信息都被整齐地封装好,其中包含相关的输入和输出文件。在这种范式下我们已经有了很大的进步(主要在图像识别和语音识别领域中)。
问题在于,当然,生活并不是一场Kaggle竞赛;孩子们并不会把所有数据整齐地打包进一个目录里。真实世界中我们需要学习更为零散的数据,问题并没有如此整齐地封装起来。深度学习在诸如语音识别这种有很多标记的问题上非常有效,但却几乎没有人知道如何将其应用于更开放的问题。如何把卡在自行车链条上的绳子挑出来?我专业该选数学还是神经科学?训练集不会告诉我们。
与分类离得越远,与常识离得越近的问题就越不能被深度学习来解决。在近期对于常识的研究中,我和Ernie Davis(2015)开始,从一系列易于得出的推论开始进行研究,如威廉王子和他的孩子乔治王子谁更高?你可以用聚酯衬衫来做沙拉吗?如果你在胡萝卜上插一根针,是胡萝卜上有洞还是针上有洞?
据我所知,目前还没有人常识让深度学习回答这样的问题。
这些对于人类而言非常简单的问题需要整合大量不同来源的知识,因此距离深度学习受用风格的分类还有很长一段距离。相反,这或许意味着若想要达到人类级别的灵活认知能力,我们需要与深度学习完全不同的工具。
3.7 到目前为止,深度学习还不能从根本上区分因果关系和相关关系
如果因果关系确实不等同于相关关系,那么这两者之间的区别对深度学习而言也是一个严重的问题。粗略而言,深度学习学习的是输入特征与输出特征之间的复杂相关关系,而不是固有的因果关系表征。深度学习系统可以将人群看作是一个整体而轻松学习到身高与词汇量是相关的,但却更难表征成长与发育之间相互关联的方式(孩子在学会更多词的同时也越长越大,但这并不意味着长高会导致他们学会更多词,学会更多词也不会导致他们长高)。因果关系在其它一些用于人工智能的方法中一直是核心因素(Pearl, 2000),但也许是因为深度学习的目标并非这些难题,所以深度学习领域传统上在解决这一难题上的研究工作相对较少。[9]
3.8 深度学习假设世界是大体稳定的,采用的方式可能是概率的
深度学习的逻辑是:在高度稳定的世界(比如规则不变的围棋)中效果很可能最佳,而在政治和经济等不断变化的领域的效果则没有那么好。就算把深度学习应用于股票预测等任务,它很有可能也会遭遇谷歌流感趋势(Google Flu Trends)那样的命运;谷歌流感趋势一开始根据搜索趋势能很好地预测流行病学数据,但却完全错过了2013年流感季等事件(Lazer, Kennedy, King, &Vespignani, 2014)。
3.9 到目前为止,深度学习只是一种良好的近似,其答案并不完全可信
这个问题部分是本节中提及的其它问题所造成的结果,深度学习在一个给定领域中相当大一部分都效果良好,但仍然很容易被欺骗愚弄。
越来越多的论文都表明了这一缺陷,从前文提及的Jia和Liang给出的语言学案例到视觉领域的大量示例,比如有深度学习的图像描述系统将黄黑相间的条纹图案误认为校车(Nguyen, Yosinski, &Clune, 2014),将贴了贴纸的停车标志误认为装满东西的冰箱(Vinyals, Toshev, Bengio, &Erhan, 2014),而其它情况则看起来表现良好。
最近还有真实世界的停止标志在稍微修饰之后被误认为限速标志的案例(Evtimov et al., 2017),还有3D打印的乌龟被误认为步枪的情况(Athalye, Engstrom, Ilyas, &Kwok, 2017)。最近还有一条新闻说英国警方的一个系统难以分辨裸体和沙丘。[10]
最早提出深度学习系统的「可欺骗性(spoofability)」的论文可能是Szegedy et al(2013)。四年过去了,尽管研究活动很活跃,但目前仍未找到稳健的解决方法。
3.10 到目前为止,深度学习还难以在工程中使用
有了上面提到的那些问题,另一个事实是现在还难以使用深度学习进行工程开发。正如谷歌一个研究团队在2014年一篇重要但仍未得到解答的论文(Sculley, Phillips, Ebner, Chaudhary, & Young, 2014)的标题中说的那样:机器学习是「高利息的技术债务信用卡」,意思是说机器学习在打造可在某些有限环境中工作的系统方面相对容易(短期效益),但要确保它们也能在具有可能不同于之前训练数据的全新数据的其它环境中工作却相当困难(长期债务,尤其是当一个系统被用作另一个更大型的系统组成部分时)。
Leon Bottou (2015) 在ICML的一个重要演讲中将机器学习与飞机引擎开发进行了比较。他指出尽管飞机设计依靠的是使用更简单的系统构建复杂系统,但仍有可能确保得到可靠的结果,机器学习则缺乏得到这种保证的能力。正如谷歌的Peter Norvig在2016年指出的那样,目前机器学习还缺乏传统编程的渐进性、透明性和可调试性,要实现深度学习的稳健,需要在简洁性方面做一些权衡。
Henderson及其同事最近围绕深度强化学习对这些观点进行了延展,他们指出这一领域面临着一些与稳健性和可复现性相关的严重问题(Henderson et al., 2017)。
尽管在机器学习系统的开发过程的自动化方面存在一些进展(Zoph, Vasudevan, Shlens, &Le, 2017),但还仍有很长的路要走。
3.11 讨论
当然,深度学习本身只是数学;上面给出的所有问题中没有任何一个是因为深度学习的底层数学存在某种漏洞。一般而言,在有足够的大数据集时,深度学习是一种用于优化表征输入与输出之间的映射的复杂系统的完美方法。
真正的问题在于误解深度学习擅长做什么以及不擅长做什么。这项技术擅长解决封闭式的分类问题,即在具备足够多的可用数据以及测试集与训练集接近相似时,将大量潜在的信号映射到有限数量的分类上。
偏离这些假设可能会导致问题出现;深度学习只是一种统计技术,而所有的统计技术在偏离假设时都会出问题。
当可用训练数据的量有限或测试集与训练集有重大差异或样本空间很广且有很多全新数据时,深度学习系统的效果就没那么好了。而且在真实世界的限制下,有些问题根本不能被看作是分类问题。比如说,开放式的自然语言理解不应该被视为不同的大型有限句子集合之间的映射,而应该被视为可能无限范围的输入句子与同等规模的含义阵列之间的映射,其中很多内容在之前都没遇到过。在这样的问题中使用深度学习就像是方枘圆凿,只能算是粗略的近似,其它地方肯定有解决方案。
通过考虑我在多年前(1997)做过的一系列实验,可以获得对当前存在错误的直观理解,当时我在一类神经网络(之后在认知科学中变得很流行)上测试了语言开发的一些简单层面。这种网络比现今的模型要更简单,他们使用的层不大于三个(1 个输入层、1 个隐藏层、1 个输出层),并且没有使用卷积技术。他们也使用了反向传播技术。
在语言中,这个问题被称为泛化(generalization)。当我听到了一个句子「John pilked a football to Mary」,我可以从语法上推断「John pilked Mary the football」,如果我知道了pilk是什么意思,我就可以推断一个新句子「Eliza pilked the ball to Alec」的含义,即使是第一次听到。
我相信将语言的大量问题提取为简单的例子在目前仍然受到关注,我在恒等函数f(x) =x上运行了一系列训练三层感知机(全连接、无卷积)的实验。
训练样本被表征二进制数字的输入节点(以及相关的输出节点)进行表征。例如数字7,在输入节点上被表示为4、2和1。为了测试泛化能力,我用多种偶数集训练了网络,并用奇数和偶数输入进行了测试。
我使用了多种参数进行了实验,结果输出都是一样的:网络可以准确地应用恒等函数到训练过的偶数上(除非只达到局部最优),以及一些其它的偶数,但应用到所有的奇数上都遭遇了失败,例如 f(15)=14。
大体上,我测试过的神经网络都可以从训练样本中学习,并可以在n维空间(即训练空间)中泛化到这些样本近邻的点集,但它们不能推断出超越该训练空间的结果。
奇数位于该训练空间之外,网络无法将恒等函数泛化到该空间之外。即使添加更多的隐藏单元或者更多的隐藏层也没用。简单的多层感知机不能泛化到训练空间之外(Marcus, 1998a; Marcus, 1998b; Marcus, 2001)。
上述就是当前深度学习网络中的泛化挑战,可能会存在二十年。本文提到的很多问题——数据饥饿(data hungriness)、应对愚弄的脆弱性、处理开放式推断和迁移的问题,都可以看作是这个基本问题的扩展。当代神经网络在与核心训练数据接近的数据上泛化效果较好,但是在与训练样本差别较大的数据上的泛化效果就开始崩塌。
广泛应用的卷积确保特定类别的问题(与我的身份问题类似)的解决:所谓的平移不变性,物体在位置转换后仍然保持自己的身份。但是该解决方案并不适用于所有问题,比如Lake近期的展示。(数据增强通过扩展训练样本的空间,提供另一种解决深度学习外插挑战的方式,但是此类技术在2d版本中比在语言中更加有效。)
目前深度学习中没有针对泛化问题的通用解决方案。出于该原因,如果我们想实现通用人工智能,就需要依赖不同的解决方案。
4. 过度炒作的潜在风险
当前AI过度炒作的一个最大风险是再一次经历AI寒冬,就像1970年代那样。尽管现在的AI应用比1970年代多得多,但炒作仍然是主要担忧。当吴恩达这样的高知名度人物在《哈佛商业评论》上撰文称自动化即将到来(与现实情况有很大出入),过度预期就带来了风险。机器实际上无法做很多普通人一秒内就可以完成的事情,从理解世界到理解句子。健康的人类不会把乌龟错认成步枪或把停车牌认成冰箱。
大量投资AI的人最后可能会失望,尤其是自然语言处理领域。一些大型项目已经被放弃,如Facebook的M计划,该项目于2015年8月启动,宣称要打造通用个人虚拟助手,后来其定位下降为帮助用户执行少数定义明确的人物,如日历记录。
可以公平地说,聊天机器人还没有达到数年前炒作中的预期。举例来说,如果无人驾驶汽车在大规模推广后被证明不安全,或者仅仅是没有达到很多承诺中所说的全自动化,让大家失望(与早期炒作相比),那么整个AI领域可能会迎来大滑坡,不管是热度还是资金方面。我们或许已经看到苗头,正如 Wired 最近发布的文章After peak hype, self-driving cars 14 enter the trough of disillusionment中所说的那样(https://www.wired.com/story/self-driving-cars-challenges/)。
还有很多其他严重的担忧,不只是末日般的场景(现在看来这似乎还是科幻小说中的场景)。我自己最大的担忧是AI领域可能会陷入局部极小值陷阱,过分沉迷于智能空间的错误部分,过于专注于探索可用但存在局限的模型,热衷于摘取易于获取的果实,而忽略更有风险的「小路」,它们或许最终可以带来更稳健的发展路径。
我想起了Peter Thiel的著名言论:「我们想要一辆会飞的汽车,得到的却是140个字符。」我仍然梦想着Rosie the Robost这种提供全方位服务的家用机器人,但是现在,AI六十年历史中,我们的机器人还是只能玩音乐、扫地和广告竞价。
没有进步就是耻辱。AI有风险,也有巨大的潜力。我认为AI对社会的最大贡献最终应该出现在自动科学发现等领域。但是要想获得成功,首先必须确保该领域不会陷于局部极小值。
5. 什么会更好?
尽管我勾画了这么多的问题,但我不认为我们需要放弃深度学习。相反,我们需要对其进行重新概念化:它不是一个普遍的解决办法,而仅仅只是众多工具中的一个。我们有电动螺丝刀,但我们还需要锤子、扳手和钳子,因此我们不能只提到钻头、电压表、逻辑探头和示波器。
在感知分类方面,如果有大量的数据,那么深度学习就是一个有价值的工具。但在其它更官方的认知领域,深度学习通常并不是那么符合要求。那么问题是,我们的方向应该是哪?下面有四个可能的方向。
5.1 无监督学习
最近深度学习先驱Geoffrey Hinton和Yann LeCun都表明无监督学习是超越有监督、少数据深度学习的关键方法。但是我们要清楚,深度学习和无监督学习并不是逻辑对立的。深度学习主要用于带标注数据的有监督学习,但是也有一些方法可以在无监督环境下使用深度学习。但是,许多领域都有理由摆脱监督式深度学习所要求大量标注数据。
无监督学习是一个常用术语,往往指的是几种不需要标注数据的系统。一种常见的类型是将共享属性的输入「聚类」在一起,即使没有明确标记它们为一类也能聚为一类。Google的猫检测模型(Le et al., 2012)也许是这种方法最突出的案例。
Yann LeCun等人提倡的另一种方法(Luc, Neverova, Couprie, Verbeek, &LeCun, 2017)起初并不会相互排斥,它使用像电影那样随时间变化的数据而替代标注数据集。直观上来说,使用视频训练的系统可以利用每一对连续帧替代训练信号,并用来预测下一帧。因此这种用第t帧预测第t+1帧的方法就不需要任何人类标注信息。
我的观点是,这两种方法都是有用的(其它一些方法本文并不讨论),但是它们本身并不能解决第3节中提到的问题。这些系统还有一些问题,例如缺少了显式的变量。而且我也没看到那些系统有开放式推理、解释或可调式性。
也就是说,有一种不同的无监督学习概念,它虽然很少有人讨论,但是仍然非常有意思:即儿童所进行的无监督学习。孩子们通常会为自己设置一个新的任务,比如搭建一个乐高积木塔,或者攀爬通过椅子的窗口。通常情况下,这种探索性的问题涉及(或至少似乎涉及)解决大量自主设定的目标(我该怎么办?)和高层次的问题求解(我怎么把我的胳膊穿过椅子,现在我身体的其他部分是不是已经通过了?),以及抽象知识的整合(身体是如何工作的,各种物体有哪些窗口和是否可以钻过去等等)。如果我们建立了能设定自身目标的系统,并在更抽象的层面上进行推理和解决问题,那么人工智能领域将会有重大的进展。
5.2 符号处理和混合模型的必要性
另一个我们需要关注的地方是经典的符号AI,有时候也称为GOFAI(Good Old-Fashioned AI)。符号AI的名字来源于抽象对象可直接用符号表示这一个观点,是数学、逻辑学和计算机科学的核心思想。像f=ma这样的方程允许我们计算广泛输入的输出,而不管我们以前是否观察过任何特定的值。计算机程序也做着同样的事情(如果变量x的值大于变量y的值,则执行操作a)。
符号表征系统本身经常被证明是脆弱的,但是它们在很大程度上是在数据和计算能力比现在少得多的时代发展起来的。如今的正确之举可能是将善于感知分类的深度学习与优秀的推理和抽象符号系统结合起来。人们可能会认为这种潜在的合并可以类比于大脑;如初级感知皮层那样的感知输入系统好像和深度学习做的是一样的,但还有一些如Broca区域和前额叶皮质等领域似乎执行更高层次的抽象。大脑的能力和灵活性部分来自其动态整合许多不同计算法的能力。例如,场景感知的过程将直接的感知信息与关于对象及其属性、光源等复杂抽象的信息无缝地结合在一起。
现已有一些尝试性的研究探讨如何整合已存的方法,包括神经符号建模(Besold et al., 2017)和最近的可微神经计算机(Graves et al., 2016)、通过可微解释器规划(Bošnjak, Rocktäschel, Naradowsky, &Riedel, 2016)和基于离散运算的神经编程(Neelakantan, Le, Abadi, McCallum, &Amodei, 2016)。虽然该项研究还没有完全扩展到如像full-service通用人工智能那样的探讨,但我一直主张(Marcus, 2001)将更多的类微处理器运算集成到神经网络中是非常有价值的。
对于扩展来说,大脑可能被视为由「一系列可重复使用的计算基元组成 - 基本单元的处理类似于微处理器中的一组基本指令。这种方式在可重新配置的集成电路中被称为现场可编程逻辑门阵列」,正如我在其它地方(Marcus,Marblestone,&Dean,2014)所论述的那样,逐步丰富我们的计算系统所建立的指令集会有很大的好处。
5.3 来自认知和发展心理学的更多洞见
另一个有潜在价值的领域是人类认知(Davis&Marcus, 2015; Lake et al., 2016; Marcus, 2001; Pinker&Prince, 1988)。机器没有必要真正取代人类,而且这极易出错,远谈不上完美。但是在很多领域,从自然语言理解到常识推理,人类依然具有明显优势。借鉴这些潜在机制可以推动人工智能的发展,尽管目标不是、也不应该是精确地复制人类大脑。
对很多人来讲,从人脑的学习意味着神经科学;我认为这可能为时尚早。我们还不具备足够的神经科学知识以真正利用反向工程模拟人脑。人工智能可以帮助我们破译大脑,而不是相反。
不管怎样,它同时应该有来自认知和发展心理学的技术与见解以构建更加鲁棒和全面的人工智能,构建不仅仅由数学驱动,也由人类心理学的线索驱动的模型。
理解人类心智中的先天机制可能是一个不错的开始,因为人类心智能作为假设的来源,从而有望助力人工智能的开发;在本论文的姊妹篇中(Marcus,尚在准备中),我总结了一些可能性,有些来自于我自己的早期研究(Marcus, 2001),另一些则来自于Elizabeth Spelke的研究(Spelke & Kinzler, 2007)。来自于我自己的研究的那些重点关注的是表示和操作信息的可能方式,比如用于表示一个类别中不同类型和个体之间不同变量和差异的符号机制;Spelke的研究则关注的是婴儿表示空间、时间和物体等概念的方式。
另一个关注重点可能是常识知识,研究方向包括常识的发展方式(有些可能是因为我们的天生能力,但大部分是后天学习到的)、常识的表示方式以及我们如何将常识用于我们与真实世界的交互过程(Davis & Marcus, 2015)。Lerer 等人(2016)、Watters及其同事(2017)、Tenenbaum及其同事(Wu, Lu, Kohli, Freeman, &Tenenbaum, 2017)、Davis和我(Davis, Marcus, &Frazier-Logue, 2017)最近的研究提出了一些在日常的实际推理领域内思考这一问题的不同方法。
第三个关注重点可能是人类对叙事(narrative)的理解,这是一个历史悠久的概念,Roger Schank和Abelson在1977年就已提出,并且也得到了更新(Marcus, 2014; Kočiský et al., 2017)。
5.4. 更大的挑战
不管深度学习是保持当前形式,还是变成新的东西,抑或被替代,人们也许认为大量的挑战问题会将系统推进到有监督学习无法通过大型数据集学习到知识。以下是一些建议,它们部分摘自最近一期的AI Magazine特刊(Marcus, Rossi, Veloso - AI Magazine, &2016, 2016),该杂志致力于超越我和 Francesca Rossi、Manuelo Veloso 一起编辑的杂志Turing Test:
理解力挑战(Paritosh&Marcus, 2016; Kočiský et al., 2017)需要系统观看一个任意的视频(或者阅读文本、听广播),并就内容回答开放问题(谁是主角?其动机是什么?如果对手成功完成任务,会发生什么?)。没有专门的监督训练集可以涵盖所有可能的意外事件;推理和现实世界的知识整合是必需的。
科学推理与理解,比如艾伦人工智能研究所的第8级的科学挑战(Schoenick, Clark, Tafjord, P, &Etzioni, 2017; Davis, 2016)。尽管很多基本科学问题的答案可轻易从网络搜索中找到,其他问题则需要清晰陈述之外的推理以及常识的整合。
一般性的游戏玩法(Genesereth, Love, &Pell, 2005),游戏之间可迁移(Kansky et al., 2017),这样一来,比如学习一个第一人称的射击游戏可以提高带有完全不同图像、装备等的另一个游戏的表现。(一个系统可以分别学习很多游戏,如果它们之间不可迁移,比如DeepMind的Atari游戏系统,则不具备资格;关键是要获取累加的、可迁移的知识。)
物理具化地测试一个人工智能驱动的机器人,它能够基于指示和真实世界中与物体部件的交互而不是大量试错,来搭建诸如从帐篷到宜家货架这样的系统(Ortiz Jr, 2016)。
没有一个挑战可能是充足的。自然智能是多维度的(Gardner, 2011),并且在世界复杂度给定的情况下,通用人工智能也必须是多维度的。
通过超越感知分类,并进入到推理与知识的更全面整合之中,人工智能将会获得巨大进步。
6.结语
为了衡量进步,有必要回顾一下5年前我写给《纽约客》的一篇有些悲观的文章,推测「深度学习只是构建智能机器面临的15个更大挑战的一部分」,因为「这些技术缺乏表征因果关系(比如疾病与症状)的方法」,并在获取「兄弟姐妹」或「相同」等抽象概念时面临挑战。它们没有执行逻辑推理的显式方法,整合抽象知识还有很长的路要走,比如对象信息是什么、目标是什么,以及它们通常如何使用。
正如我们所见,尽管特定领域如语音识别、机器翻译、棋盘游戏等方面出现重大进展,尽管在基础设施、数据量和算力方面的进展同样令人印象深刻,但这些担忧中的很多依然存在。
有趣的是,去年开始不断有其他学者从不同方面开始强调类似的局限,这其中有Brenden Lake和Marco Baroni (2017)、François Chollet (2017)、Robin Jia 和 Percy Liang (2017)、Dileep George及其他Vicarious同事 (Kansky et al., 2017)、 Pieter Abbeel及其Berkeley同僚 (Stoica et al., 2017)。
也许这当中最著名的要数Geoffrey Hinton,他勇于做自我颠覆。上年8月接受Axios采访时他说自己「深深怀疑」反向传播,因为他对反向传播对已标注数据集的依赖性表示担忧。
相反,他建议「开发一种全新的方法」。与Hinton一样,我对未来的下一步走向深感兴奋。
📚往期文章推荐

🔗Google称2029年人类开始实现永生不死!疾病,衰老,痛苦将彻底消失?
🔗Yann LeCun | 怒喷Sophia:这就是彻头彻尾的骗局
🔗晴天霹雳!国防科大哲学社会科学领军人物刘戟锋教授因病昨日于长沙离世,享年60岁

德先生公众号 | 往期精选
在公众号会话位置回复以下关键词,查看德先生往期文章!
人工智能|机器崛起|区块链|名人堂
虚拟现实|无人驾驶|智能制造|无人机
科研创新|网络安全|数据时代|人机大战
……
更多精彩文章正在赶来,敬请期待!


点击“阅读原文”,移步求知书店,可查阅选购德先生推荐书籍。



