深度 | AI 芯片之智能边缘计算的崛起
AI 科技评论按:本文作者为线性资本黄松延,原文首发于微信公众号:线性资本(ID: LinearVenture),AI 科技评论获其授权转载。
黄松延,浙江大学人工智能博士,前华为数据科学家,对深度学习及其应用有深入的研究,阅后若有所感,欢迎添加微信号( ID: Nikola_629 )与他交流。线性资本,致力于打造最好的数据智能基金。
基础层、算法层与应用层是人工智能产业链的三个组成部分。人工智能(AI)正在作为基础技术,改变不同的行业,并具有极其广阔的应用市场。考虑到深度学习等AI算法开源的发展趋势,基础层的数据与芯片将在未来竞争中占据越来越重要的地位。作为人工智能发展支柱的AI芯片(特指专门针对AI算法做了特定设计的芯片)更是人工智能行业的核心竞争力。
基于深度神经网络(DNN)在各个应用中表现出的巨大优势,本文的AI仅限于深度学习。下文将从AI计算与AI芯片出发,分析不同种类AI芯片间的区别,探索应用于终端推断(Edge Inference,EI)的AI芯片,即AI-EI芯片,并给出AI-EI芯片硬件架构特性,讨论多家AI-EI芯片公司,最后给出AI-EI芯片发展趋势及投资逻辑。
一、AI计算及AI芯片
近几年,深度神经网络(DNN)在图像识别、自然语言处理等方向上取得了前所未有的成功,并推动相关行业的快速发展。但是,这些应用中使用的深度神经网络的参数量巨大,模型训练(training)与推断(inference)都需要大量的计算,传统计算芯片的算力无法满足DNN计算需求。具有高算力的AI芯片能够满足AI行业计算需求并得到了快速发展。
2016年AI芯片全球市场规模为23.88亿美元,有机构预计到2020年AI芯片全球市场规模将达到146.16亿美元(终端AI芯片的市场规模),发展空间巨大。另外,各国纷纷把AI芯片定为自己的战略发展方向。
与传统CPU不同的是,AI芯片具有大量的计算单元,能够适合大规模并行计算的需求。基于通用性与计算性能的不同,可以把AI芯片分为GPU、FPGA、ASIC三大类。深度神经网络的基本运算单元是“乘-加”(MAC)操作。每次MAC中存储器读写操作如图1所示。
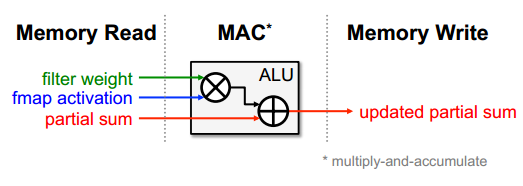
在AI应用中,CPU与AI芯片的计算能力是由芯片所具备的MAC能力及如何发挥芯片的MAC能力两个因素决定。
CPU是通用芯片,CPU的大部分面积都被控制单元与缓存单元所占,只有少量的计算单元。另外,CPU的指令执行过程包括取指令、指令译码与指令执行三部分。只有在指令执行的时候,计算单元才能发挥作用。因而,CPU在发挥芯片的MAC能力方面亦比较一般。为了提高指令执行效率,CPU采用指令流水处理方式。
GPU有大量的计算单元,适合大规模并行计算。但是,GPU也是通用芯片,其指令执行过程也由取指令、指令译码与指令执行三部分组成。该特征是制约GPU计算能力的主要原因之一。
FPGA,即,现场可编程逻辑门阵列,是一种更接近I/O的高性能、低功耗芯片。FPGA是算法即电路,软硬合一的芯片。基于硬件描述语言,可以把算法逻辑直接编译为晶体管电路组合。由于FPGA的硬件电路是由算法定制的,其不需要取指令与指令译码过程,因而,FPGA能够充分发挥芯片的计算能力。另外,FPGA可以重复编程,因而具备一定的灵活性。
ASIC,即,专用集成电路。类似于FPGA,ASIC采用的也是算法即电路的逻辑,亦不需要取指令与指令执行过程。另外,ASIC是为了特定的需求而专门定制的芯片,因而,能够最大程度发挥芯片的计算能力。但是,不同于FPGA的可重复编程,ASIC的设计制造一旦完成,就无法再改变,其灵活性较差。
在评价一个芯片架构性好坏时,有多种指标可供参考。其中,能耗与峰值计算能力(芯片结构中每秒计算操作数的总和,用OPS表示)是两个重要的衡量指标。不同指标间会相互制衡,一个指标的增高可能是以牺牲其它指标为代价而获取的。因而,常采用归一化的指标单位能耗算力(OPS/W),即,能效,来衡量芯片计算性能。实质上看,上述的四种芯片是通用性与能效trade-off的结果。能效方面,ASIC>FPGA>GPU>CPU。通用性则反之。
对于AI芯片,从市场格局来看,NVIDIA是GPU行业的绝对龙头。对于FPGA,XILINX、ALTERA(现并入INTEL)、LATTICE、MICROSEMI四家占据全球99%的市场份额。其中,XILINX、ALTERA两家占据全球90%的市场份额。另外,FPGA四大巨头拥有6000多项行业专利,形成该行业极高的技术壁垒。对于ASIC芯片,目前还未形成巨头垄断的市场格局,但是对于不同垂直领域,其情况不同,我们将在下文中给出详细分析。
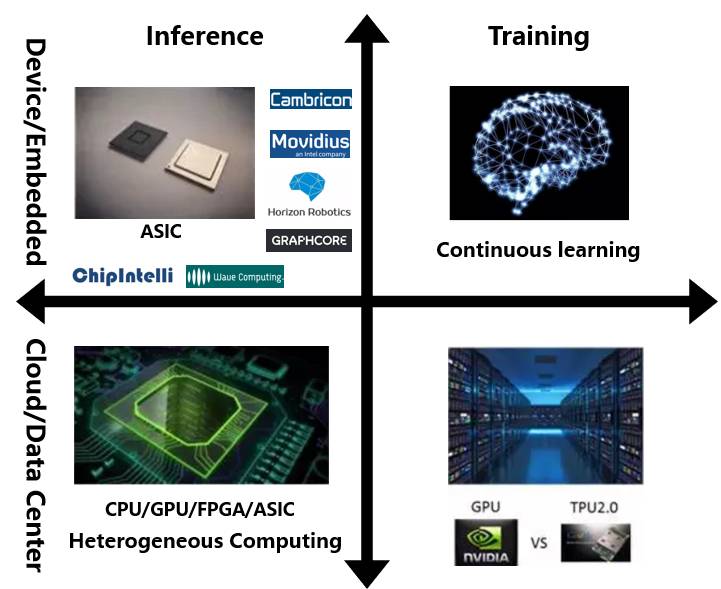
深度学习分为两个阶段:模型训练与智能推断,如图2所示。模型训练需要大量的训练样本,基于梯度下降法,模型优化收敛到局部最优点。深度学习的模型训练需要几小时到多天的迭代优化,因而,现阶段,模型训练都在云端完成(我们认为具备持续学习能力是智能终端未来发展的方向,因而这里并不认为训练一定只在云端完成)。模型训练好之后,则能够基于该模型与输入数据,计算得到输出,完成智能推断。相比于模型训练,推断的计算量要小很多,可以在云端与终端完成。
现阶段,由于终端设备的计算力普遍有限,模型训练与推断大都在云端服务器上完成。在云端模型训练中,NVIDIA的GPU占主导地位,多GPU并行架构是云端训练常用的基础架构方案。在云端识别中,基于功耗与运算速度的考量,单独基于GPU的方式并非最优方案,利用CPU、GPU、FPGA、ASIC各自的优势,采用异构计算(CPU+GPU+FPGA/ASIC)是目前主流方案。
在计算机视觉、语音识别等应用中,终端采集数据(特别是图像数据),然后上传到云端处理的云计算对网络带宽与数据中心存储都带来越来越大的挑战。另外,无人驾驶等应用对实时性与安全性要求极高。网络的时延与稳定性所带来的安全隐患是无人驾驶等应用所无法忍受的。在终端采集数据,并完成数据处理,提供智能终端推断的边缘计算(Edge computing),因其能够满足实时性、安全性的需求,且能节约带宽与存储,得到越来越多的关注。我们判断inference将越来越多的在终端设备上完成,即,智能将会下沉到终端设备,智能边缘计算将会崛起。
实时性是选择在终端完成推断最主要的原因之一。但是,由于深度神经网络参数量巨大,推断过程需要完成大量的计算,其对终端硬件的计算力提出了很高的要求。另外,电池供电的终端设备对功耗也有极高的要求,且大多数的终端产品价格敏感。即,执行DNN推断的终端芯片对算力、功耗、价格都有严格的限制。研究用于DNN推断的AI-EI芯片是目前AI芯片行业最热的方向。现阶段,已有大量的初创公司,针对不同领域及应用,提出多种AI-EI芯片硬件设计架构,下文将详细给出AI-EI芯片的架构思路及发展现状
三、AI-EI芯片及其架构
基于深度神经网络的广泛应用,科技巨头及初创公司都根据DNN的特性进行有针对性的硬件处理器研发。其中包括Google的TPU、寒武纪的DianNao系列、Eyeriss的NPU等AI芯片。本节将总结并给出这些AI-EI芯片如何在不降低准确率的前提下实现运算吞吐量提升,并降低能耗。
由前文可知,深度神经网络的基本运算为MAC操作,且MAC操作很容易被并行化。在DNN硬件设计中,常使用时间架构(temporal architecture)与空间架构(spatial architecture)两种高度并行化的计算架构,来获取高计算性能。
时间架构(Temporalarchitecture)
通用芯片CPU与GPU常采用时间架构,并使用单指令多数据流(SIMD)或者单指令多线程(SIMT)来提高并行化处理性能。时间架构基于中央控制器统一控制所有的ALU。这些ALU只能从层次存储器中取数据,而不能相互通信。
时间架构中,通常使用各种计算变换,特别是对卷积操作的计算变换,来减小计算复杂度,从而提升吞吐量,常用的方法包括:
Toeplitz矩阵方法:把卷积操作转换为矩阵乘操作
FFT方法:经过FFT变换,把卷积运算变成矩阵乘操作
Winograd方法:比较适合较小的滤波器的情况
空间架构(spatial architecture)
基于ASIC或者FPGA的AI-EI芯片常使用空间架构。相对于通用芯片,专用芯片应用在特定场景,其功能有限。简单且规则的硬件架构是降低设计成本的基础,亦是实现低成本专用芯片的先决条件。足够低的芯片成本才能对冲专用芯片功能的局限性。
空间架构采用数据流(Dataflow)处理方式。在空间架构中,ALU形成一条数据处理链,从而能够在ALU间直接地传送数据。该空间架构中,每个ALU都有自己的控制逻辑与本地存储(寄存器堆)。其中,有本地存储的ALU被定义为PE。
对于空间架构,硬件设计基于层次存储器中的低能耗内存,并增加数据重利用率(实质上,卷积是空间重用,这种重用可以获取空间的不变性),来减小能耗。另外,数据流(Dataflow)控制数据读、写及处理。总体上,空间架构基于层次存储器与数据流平衡I/O与运算问题,从而降低能耗并提升运算吞吐量。下文将在分析层次存储器与数据流的基础上,讨论不同的技术路线的AI-EI芯片。
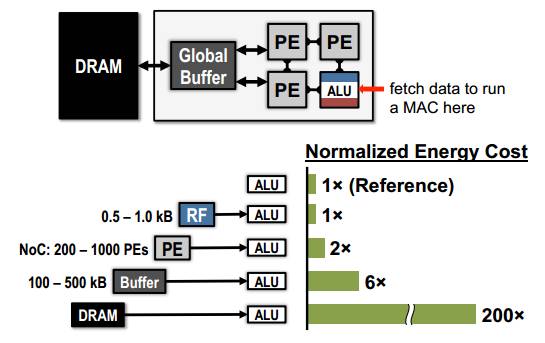
访问内存所需时间要远远大于计算所需时间。由深度神经网络的推断部分运算可知,每个MAC都需要三次内存读与一次内存写操作。其中三次内存读操作分别为读取输入数据、权值数据与部分和数据(partial sum),一次内存写操作为更新部分和数据。层次存储器基于内部寄存器等存储单元来减小对外挂内存访问次数,降低I/O需求。层次存储器如图4所示,该层次存储器包括PE内部的寄存器(RF)、用于ALU间直接传输数据时存储数据的内存单元NoC及连接DRAM的全局缓存器Buffer。由图4可以看到,层次存储器中,不同类别的存储器读写操作所消耗的能量不同,这也是我们能够利用层次存储器及数据复用来降低能耗的原因。
Dataflow是一种没有复杂程序指令控制且由操作数,即,数据或者中间结果,激活子计算单元,来实现并行计算的一种计算方式。图5总结出了Dataflow的架构逻辑。
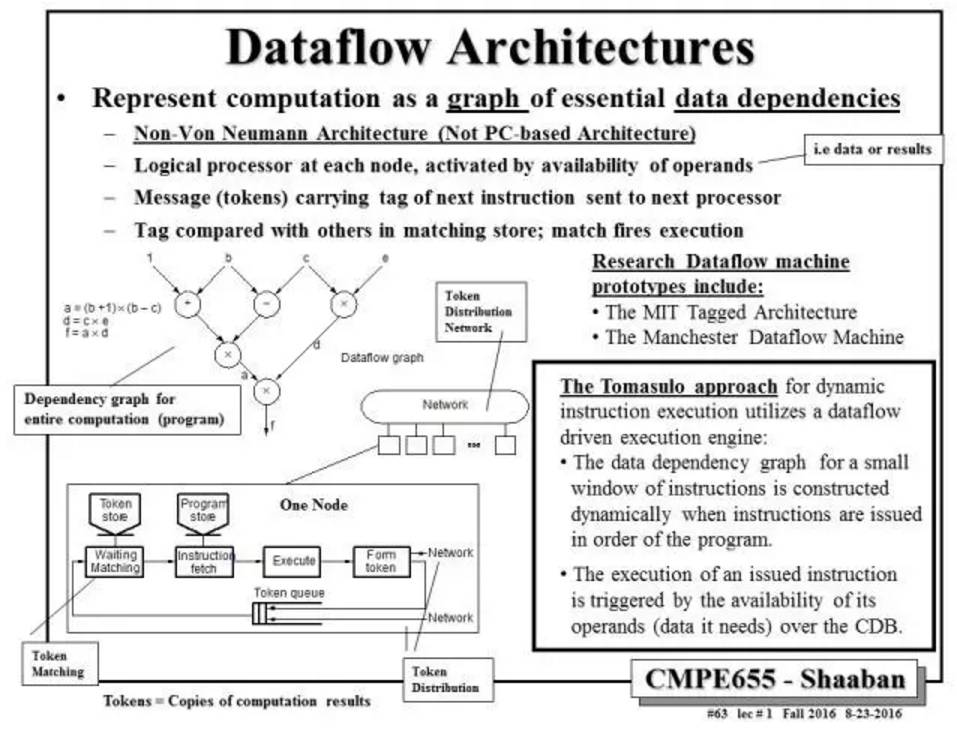
在深度学习的推断中,有大量的计算需求。但是,这些计算是分层顺序执行的。因而,控制流程相对简单、清晰。可以看出,Dataflow处理方式与基于深度神经网络推断部分的计算需求非常吻合。
数据流能够决定哪些数据读入到哪层存储器以及这些数据什么时候被处理。另外,在DNN推断中,没有随机性。因而,可以从最优能耗的角度,设计一个基于Dataflow的固定架构的AI-EI芯片。目前,大多数用于深度学习推断的AI-EI芯片都采用Dataflow。
层次存储器中,存储量大的存储器读写操作所消耗的能量要比小存储的存储器大很多。因而,一旦一块数据从大存储器搬移到小存储器后,要尽可能最大程度复用(reuse)该数据块来最小化能耗。但是低功耗存储器的存储空间有限。如何最大化复用率是设计基于Dataflow加速器时最关注的先前条件。即,通过最大化数据复用率来降低I/O要求,减小数据处理能耗,从而提升吞吐量并降低总体能耗。常见的DNN数据流类型包括:权值固定数据流、输出固定数据流、No local reuse(NLR)及行固定数据流。
权值固定数据流: 从DRAM中读出权值数据,放在PE的RF中并保持不变,之后把输入数据广播(broadcast)到每个PE,最后求取PE阵列的部分和(partialsum)。该处理方式通过最大化从PE的RF中读取权值数据次数,并最小化直接从DRAM中读取权值次数,实现最大化卷积与滤波器对权值的复用率,来减小能耗。NeuFlow即为基于该种数据处理方式的AI-EI芯片。
输出固定(OS)数据流: 通过在PE阵列中stream输入数据,然后把权值数据广播到PE阵列,保持 RF中的部分和的累加不变,从而最小化读写部分和的能耗。寒武纪的ShiDianNao是基于输出固定的AI-EI芯片。另外,根据处理目标的不同,可以把该种数据流分为以卷积层为处理目标的OS_A与以全连接层为处理目标的OS_C,OS_B是介于OS_A与OS_C间的一种OS数据流。
NLR数据流: PE阵列的RF中并不存储任何固定数据,相反,该情况下,所有数据的读写操作都是在全局buffer中完成。寒武纪的DianNao与DaNiaoNao是基于该数据处理方式的AI-EI芯片
行固定数据流: 最大化所有数据复用率并尽可能的使得所有数据的读写操作都在RF中完成,减小对全局buffer的读写操作,来减小功耗。每个PE能够完成1D的卷积运算,多个PE能够完成2D的卷积运算。在二维的PE阵列中,水平轴上的PE单元上,每一行的权值数据被复用,对角线上的PE单元上,每一行的输入数据被复用,垂直轴上的多个PE单元上,每一行的部分和数据被复用,即,行固定的数据流能够最大化所有数据的复用率,从而能够全局最优化功耗。Eyeriss的NPU是基于行固定的AI-EI芯片。
四、AI-EI芯片玩家
本节首先总结三家极具代表性的研发DNN加速器(Google、Wave computing、Graphcore是平台化的计算平台,因而,这里没把他们叫做AI-EI芯片厂家)的公司,后文中结合应用场景总结AI-EI芯片创业公司,其中部分公司的芯片也可以做训练,且不一定应用在终端场景,这里基于行为考虑,把他们称为AI-EI芯片公司。
Google TPU
在2015年就开始部署ASIC张量处理器TPU。TPU采用脉动阵列(systolic array)技术,通过矩阵单元的使用,减小统一缓冲区的读写来降低能耗,即脉动运行。脉动阵列不是严格意义的Dataflow,但也是数据流驱动的设计方式。该技术早在1982年就被提出,但是受限于当时的工艺水平及应用,该技术在当时并没有引起太多关注。脉动阵列在TPU上的应用,让该技术回归大众视野,并得到了极大的关注。
Google在TPU上使用该技术的逻辑在于脉动阵列简单、规则且能够平衡运算与I/O通信。TPU中基本计算单元是功能单一的处理单元PE,每个PE需要先从存储中读取数据,进行处理,然后把处理后的结果再写入到存储中。TPU脉动阵列中的PE与前文中其他DNN加速器的PE基本一样,能够实现MAC操作,有存储能力有限的RF。由前文可知,对数据读写的速度要远远小于数据处理的速度。因而,访问内存的速度决定了处理器的处理能力。TPU的脉动阵列采用数据复用及数据在阵列中的脉动运行的策略来减小访问存储器次数,从而提高TPU的吞吐量。
TPU在实现卷积等运算时,要先调整好数据的形式(即对原始矩阵做好调整),之后才能完成相应的计算。因而,TPU的灵活性一般,只能处理特定的运算,这也是其它基于PE阵列Dataflow DNN加速器共有的问题。但是脉动阵列特别适合卷积运算,TPU有多种实现卷积运算的方式,其中包括:
权值存储在PE中保持不变,广播输入数据到各个PE,部分和的结果在PE阵列中脉动运行
部分和的结果存储在PE中保持不变,广播输入数据到各个PE,权值在PE阵列中脉动运行
部分和的结果存储在PE中保持不变,输入数据与权值在PE阵列中按相反方向脉动运行
部分和的结果存储在PE中保持不变,输入数据与权值在PE阵列中按相同方向但不同速度脉动运行
权值存储在PE中保持不变,输入数据与部分和的结果在PE阵列中按相反方向脉动运行
权值存储在PE中保持不变,输入数据与部分和的结果在PE阵列中按相同方向但不同速度脉动运行
Wave computing
基于Coarse GrainReconfigurable Array (CGRA) 阵列,实现数据流计算。另外,Wave的DNN加速器是clockless,其基于握手信号来实现模块间的同步。因而,不需要时钟树,从而能够减小芯片面积并降低功耗。
Graphcore
打造专门针对graph计算的智能处理器IPU。Graphcore在芯片设计上做出了很大的改变。相比于CPU以scalar为基础表示,GPU以矢量为基础表示,Graphcore的IPU是为了high-dimensional graph workload而设计的。这种表示既适用于神经网络,也适用于贝叶斯网络和马尔科夫场,包括未来可能出现的新的模型和算法。该IPU采用同构多核架构,有k级的独立处理器。另外,该芯片使用大量片上SRAM,不直接连接DRAM。该芯片能够直接做卷积运算,而不需要把转换成矩阵乘法之后使用MAC操作完成。该IPU不仅能够支持推断,也能支持训练。
商业应用是AI的关键因素之一,AI只有解决了实际的问题才具有价值,下文,我们从终端不同的应用,探讨AI-EI芯片。不同的加速器在各个子行业都有应用布局,我们从主要应用领域出发,给出公司产品、最新产品性能及融资情况的终结。
AI-EI芯片+自动驾驶
在汽车行业,安全性是最重要的问题。高速驾驶情况下,实时性是保证安全性的首要前提。由于网络终端机延时的问题,云端计算无法保证实时性。车载终端计算平台是自动驾驶计算发展的未来。另外,随着电动化的发展趋势,对于汽车行业,低功耗变的越来越重要。天然能够满足实时性与低功耗的ASIC芯片将是车载计算平台未来发展趋势。目前地平线机器人与Mobileye是OEM与Tier1的主要合作者。

AI-EI芯片+安防、无人机
对于如何解决“虐童”问题,我们认为能够“看得懂”的AI安防视频监控是可行方案之一。相比于传统视频监控,AI+视频监控,最主要的变化是把被动监控变为主动分析与预警,因而,解决了需要人工处理海量监控数据的问题(也绕开了硬盘关键时刻掉链子问题)。安防、无人机等终端设备对算力及成本有很高的要求。随着图像识别与硬件技术的发展,在终端完成智能安防的条件日益成熟。安防行业龙头海康威视、无人机龙头大疆已经在智能摄像头上使用了Movidious的Myriad系列芯片。
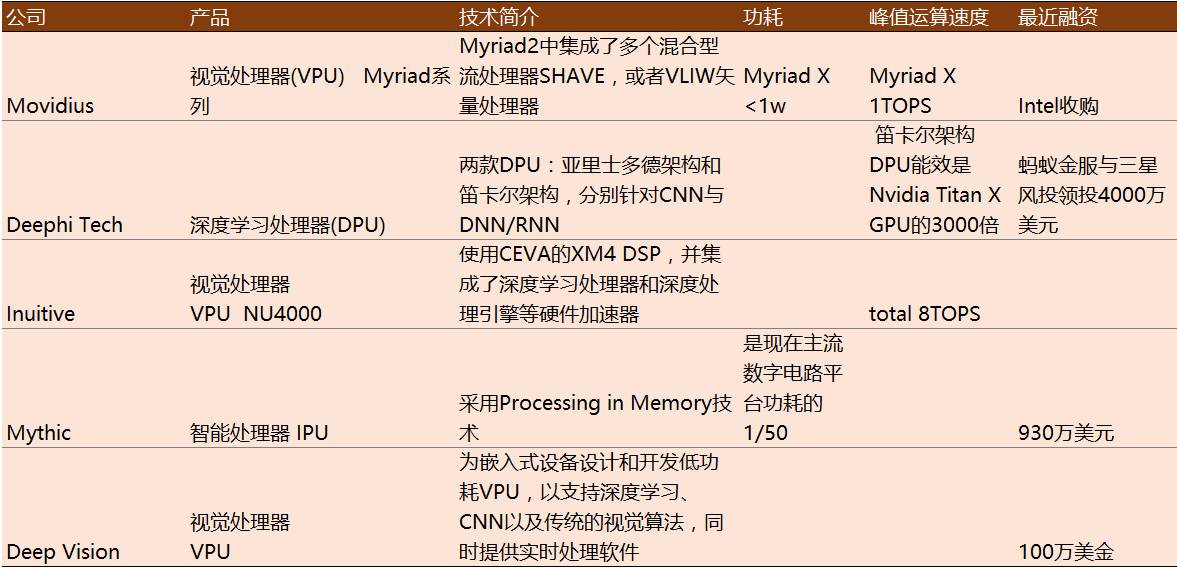
AI-EI芯片+消费电子
搭载麒麟970芯片的华为mate10手机与同样嵌入AI芯片的iPhoneX带领手机进入智能时代。另外,亚马逊的Echo引爆了智能家居市场。对于包括手机、家居电子产品在内的消费电子行业,实现智能的前提要解决功耗、安全隐私等问题。据市场调研表明,搭载ASIC芯片的智能家电、智能手机、AR/VR设备等智能消费电子已经处在爆发的前夜。

其他
随着AI应用的推广,越来越多的公司加入AI-EI芯片行业,其中,既包括Bitmain这样的比特币芯片厂商,也包括从GoogleTPU团队出来的创业公司Groq,还有技术路线极具前瞻性的Vathys。由于这些Startups都还处于非常早期阶段,具体应用方向还未公布,因而放在“其他”中。另外,我们判断终端AI芯片的参与者还会增加,整个终端智能硬件行业还处在快速上升期。
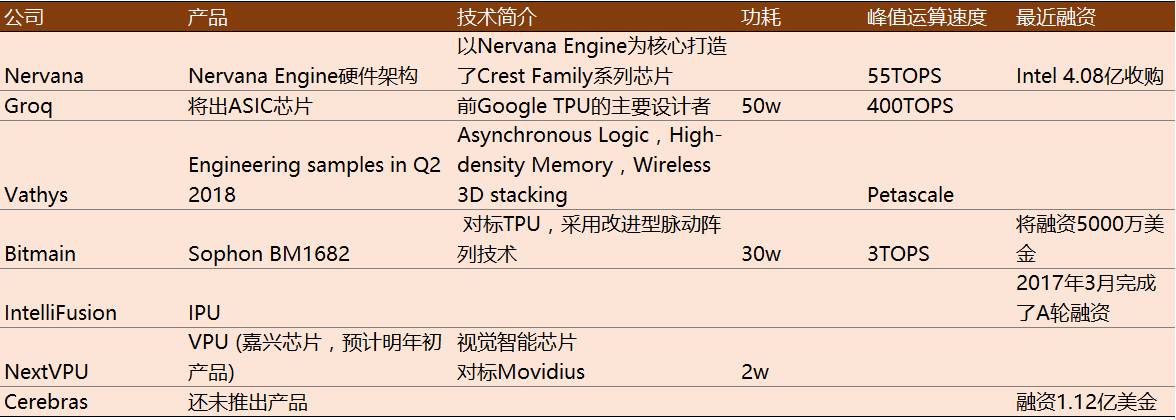
五、AI-EI芯片发展趋势
上文介绍的AI-EI芯片是在优化硬件架构基础上,实现低功耗、高吞吐量。现有研究中有采用Processing in Memory(PIM)的方式,把处理直接放在存储单元的位置,降低整个系统的复杂度,减少不必要的数据搬移,从而优化功耗和硬件成本。同时,这也需要在电路(模拟信号)的层面重新设计存储器。初创公司Mythic即采用PIM技术来设计AI芯片。另外,通过研究具备高带宽和低功耗特性的存储器来解决I/O与运算不平衡的问题也是当前的研究热点。
类脑芯片是处理Spiking neural network (SNN)而设计的一种AI芯片。IBM的TrueNorth、高通的Zeroth及国内的Westwell是类脑芯片的代表公司。类脑芯片能够实现极低的功耗。但是在图像处理方面,SNN并没有表现的比CNN好,且类脑芯片现在处在研究阶段,离商业应用还有较远的距离。
2017年芯片行业的融资额是2015年的3倍。巨头公司与资本都在积极布局AI芯片,特别是在智能边缘计算有技术积累的公司。我们无法预测未来哪家公司能够最终胜出。
但是,一家AI芯片公司要想持续发展并壮大,需要具备包括硬件及软件生态的全AI服务流程能力。从现阶段的投资动向可以看出,创业公司要想获取资本青睐,需要在硬件设计架构上有足够吸引人的变动。另外,性能指标与技术路线可以靠讲,只要合理既有可能,但是在未来1到2年的时间内再拿不出产品是很难继续讲下去的。
————— 新人福利 —————
关注AI 科技评论,回复 1 获取
【数百 G 神经网络 / AI / 大数据资源,教程,论文】
————— AI 科技评论招人了 —————
AI 科技评论期待你的加入,和我们一起见证未来!
现诚招学术编辑、学术兼职、学术外翻
详情请点击招聘启事
————— 给爱学习的你的福利 —————
上海交通大学博士讲师团队
从算法到实战应用,涵盖CV领域主要知识点;
手把手项目演示
全程提供代码
深度剖析CV研究体系
轻松实战深度学习应用领域!
详细了解请点击阅读原文
▼▼▼

————————————————————





