IEEE Fellow梅涛:计算机视觉的前沿进展与挑战
点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
今年12月9日,第六届全球人工智能与机器人大会(GAIR 2021)在深圳正式启幕,140余位产学领袖、30位Fellow聚首,从AI技术、产品、行业、人文、组织等维度切入,以理性分析与感性洞察为轴,共同攀登人工智能与数字化的浪潮之巅。
大会次日,IEEE/IAPR Fellow,京东集团副总裁,京东探索研究院副院长梅涛在GAIR大会上做了《从感知智能到认知智能的视觉计算》的报告,他指出视觉计算的感知研究虽然已经相对成熟,某些人工智能(AI)任务已经能够通过图灵测试,例如在内容合成与图像识别,但在视频分析领域,视频数据内容多样化以及视频语义的不清晰等原因导致该领域还存在大量挑战性问题。
同时,在认知领域,视觉计算已经有一些进展,例如Visual Genome、VCR等数据集已经布局结构知识建模;而在推理层面,国内学者已经尝试通过联合解译和认知推理深入理解场景或事件。
以下是演讲全文,AI科技评论做了不改变原意的整理:
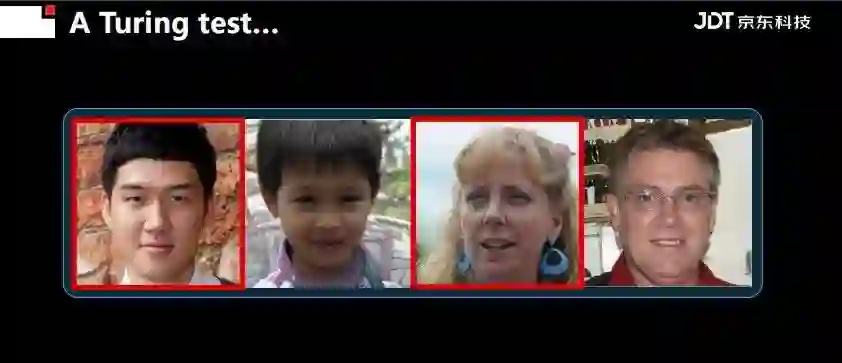
今天的演讲题目是《从感知智能到认知智能的视觉计算》。在开始之前,先用两个图灵测试的例子大致说明AI的进展。
首先计算机视觉不仅在识别领域,在内容合成领域已经达到通过图灵测试的标准。正如上图所示,人类已经很难在一组图片中将两张机器合成的图片挑选出来。

另外一个图灵测试的例子是“看图说话”:给定一张图片,描述图片的内容。下面两句话分别由人(第一句)和机器(第二句)生成。很显然,如果不仔细看图片,可能会潜意识的认为机器比人写的详细。
1.a dog is lifted among the flowers
2. a dog wearing a hat sitting within a bunch of yellow flowers
如果仔细观察图片,就会发现确实有一只手把小狗举了起来。这也说明:不太经常发生的现象,机器很难描述,其原因和机器学习的内容相关,以及机器没有逻辑推理能力。
通过上述两个例子我们可以看出:在感知领域,AI已经超越人类;而在认知领域,它还欠缺一些火候。

上图是计算机视觉在过去五六十年取得的进展,2012年深度学习“大火”之前,计算机完成视觉任务通常有两个步骤:特征工程和模型学习。
特征工程的特点是完全依靠人类智慧,例如设计Canny edge、Snak、Eigenfaces等参数特征,同时这些方法已经获得了大量的引用,Canny已经被引用了38000次,Snak 18000次,SIFT更是已经超过了64000次。
2012年之后,深度学习兴起,颠覆了几乎所有的计算机视觉任务。其特点是将传统的特征工程和模型学习合为一体,即能够在学习的过程中进行特征设计。
深度学习火热的另一个标志是每年有大量的论文投到计算机视觉顶会(CVPR、ICCV、ECCV等),同时如果这些方法表现“杰出”,就能够获得大量的流量,例如GoogleNet VGG在不到8年的时间里获得了10万次引用;2015年的ResNet更是在更短的时间获得了接近10万次的引用。
这说明深度学习领域在飞速发展,而且进入这个领域的人越来越多。一方面不仅深度学习网络在不断“更新换代”,图像、视频等数据集也在不断增长,甚至有些数据集规模已经过亿。
其中,深度学习的一个趋势是“跨界”。在2019年,Transformer在自然语言处理领域的性能被证明“一枝独秀”,现在已经有大量学者开始研究如何将其纳入视觉领域,例如微软亚洲研究院swin transformer相关工作获得了ICCV的最佳论文奖。
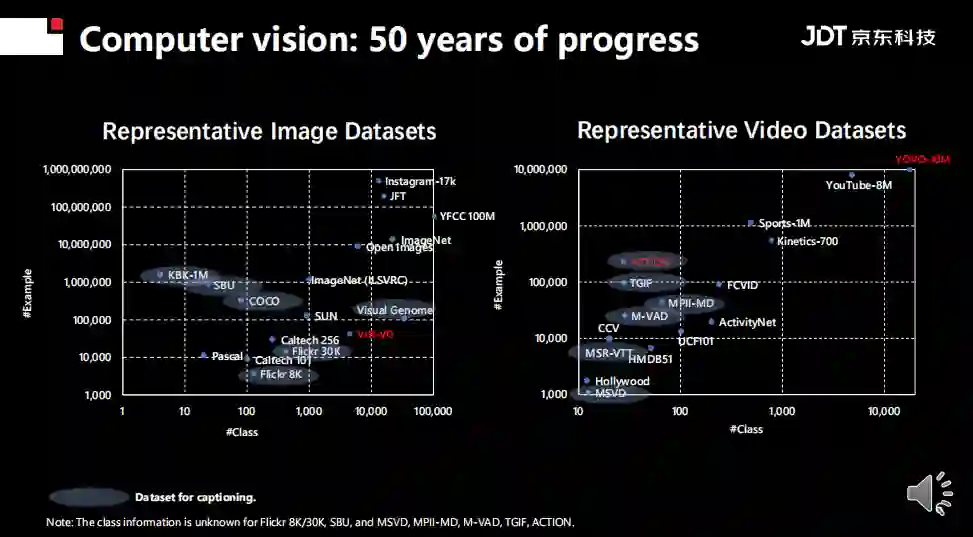
上图展示了随着研究范式的变化,数据集的变化趋势。无论是数据集的类别还是数据集的规模都在不断增大,有些数据集更是超过了10亿级别。目前类别最多的是UCF101数据集,其中包括101个类。同时,大规模也带来了一个弊端:一些高校和小型实验室无法进行模型训练。
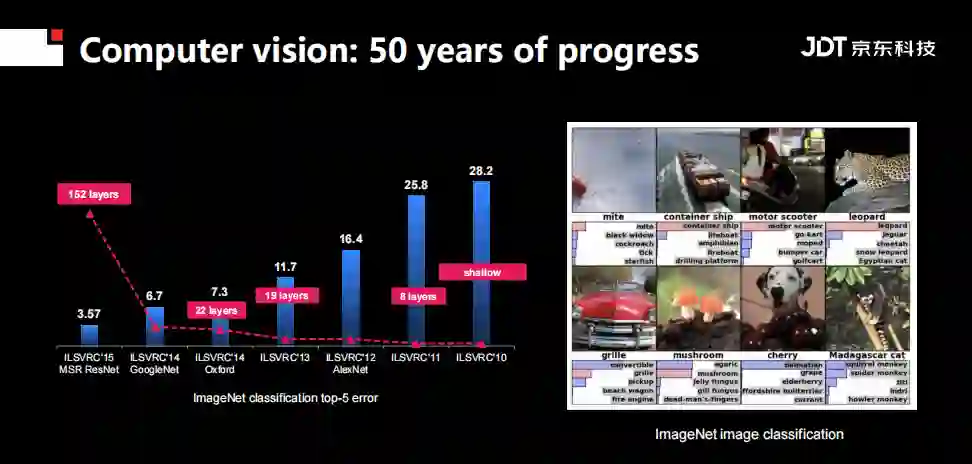
特定领域进展如何?在图像识别领域,最广为人知莫过于ImageNet竞赛。其任务是给定一张图,预测出五个相关的标签。随着深度学习网络的层数越来越深,识别的错误率越来越低,到2015年, ResNet已经它达到了152层,并且已经超过了人类识别图像的能力。

在视频分析领域。Kinetics-400 视频分析任务反应了该领域的进展,从2017年和2019年出现了各种适合视频任务的神经网络,其网络大小、深度并不一致,而且从准确率、识别精度上看,也没有一致的结果。换句话说,该领域存在大量的潜力(open question)。至于原因,个人认为有两种:
1.视频内容非常多样化,而且是时空连续的数据。
2.同样的语义,在视频中会有不同的含义。例如不同语气和不同表情下对同一个词的输出。

过去10~20年,视觉感知领域存在很多主题。如上图所示,从最小力度的像素级别到视频级别,基本上可以归为几大研究领域:语义分隔、物体检测、视频动作行为识别、图像分类、Vision and language。其中,Vision and language最近五年比较火热,其要求不仅从图视频内容里面生成文字描述,并且也可以反过来从文字描述生成视频或者图片的内容。
总结起来,目前视觉研究的主要方向还是进行RGB视频和图像研究,在不远的将来,成像的方式会发生变化,那时研究的数据将不仅是2D,更会过渡3D,甚至更多的多模态的数据。
在视觉理解领域,通用的视觉理解非常简单:例如区分猫和狗,区分车和人。但在自然界里,要真正的做到对世界的理解,其实要做到非常精细的粒度的图像识别。一个直观的例子是鸟类识别,理想中的机器需要识别10万种鸟类,才能达到人类对“理解世界”的要求。如果再精细一些,需要达到商品SKU细粒度识别。
注:一瓶200毫升和300毫升的矿泉水就是不同粒度的SKU。
过去几年,京东在这方面做了一些探索。探索路径包括:detection的方式,detection结合attention的方式,以及自监督的方式。涉及论文包括CVPR2019 的“Destruction and Construction Learning ”以及CVPR 2020的“Self-supervised”相关工作。

CVPR 2019:Destruction and Construction Learning for Fine-grained Image Recognition
论文地址:https://openaccess.thecvf.com/content_CVPR_2019/papers/Chen_Destruction_and_Construction_Learning_for_Fine-Grained_Image_Recognition_CVPR_2019_paper.pdf

CVPR 2020:Look-into-Object: Self-supervised Structure Modeling for Object Recognition
论文地址:https://arxiv.org/abs/2003.14142
视频领域非常有挑战,当年我想借鉴ResNet,毕竟在图像识别领域它是非常有创新的网络,因为其里面包含skip level的调整。因此,当时我想把2D的CNN直接应用到3D领域。
其实,相关工作已经有人尝试,但存在一定的困难。例如Facebook发现,如果沿着xyz三个轴进行卷积,参数会爆炸,所以很难提高模型性能。因此在2015年,Facebook只设计了一个11层的3D卷积网络。
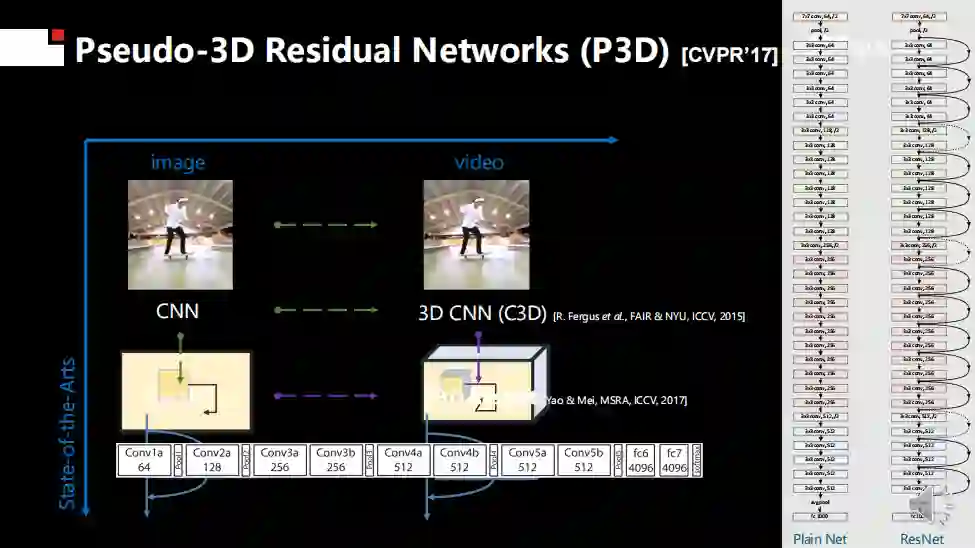
我的尝试是基于ResNet进行3D卷积设计,但也遇到了和Facebook同样的困难,即参数爆炸。因此,在CVPR 2017年的一项工作中,我利用一个1*3*3的二维空间卷积和3*1*1的一维时域卷积来模拟常用的3*3*3三维卷积。
通过简化,相比于同样深度的二维卷积神经网络仅仅增添了一定数量的一维卷积,在参数数量、运行速度等方面并不会产生过度的增长。与此同时,由于其中的二维卷积核可以使用图像数据进行预训练,对于已标注视频数据的需求也会大大减少。目前该论文引用超过1000次,得到了行业的认可。

CVPR 2017:Learning Spatio-Temporal Representation with Pseudo-3D Residual Networks
论文地址:https://arxiv.org/abs/1711.10305

其他研究领域也有很多问题有待开发。例如在3D视觉研究方面,不仅需要语义分割,还需要估计物体的姿态;在Image to Language研究中,不仅需要给定一张图片生成一段描述文字,还需要知道物体之间的空间关系语义关系。

AI一直被认为是改变工业界的范式,2019年PWC(麦肯锡)曾经发布过一个报告:AI对整个全球的经济的贡献,在2030年之前,每一年会是14%的提升。并且在中国,增长空间是26%。
将AI应用到工业界,基本需要满足三个条件中的任何一个:降低成本、提高效率、提升用户体验。市值万亿美金级别的公司,例如微软和苹果,其共同的特点在于企业会全面、大规模、一次性的推广AI技术。
大规模推广AI技术时,诞生了许多很有意思的应用,例如“拍照购物”,核心技术是Photo-to-search,该领域已被深耕多年,但真正能发挥的场景是电商。以京东为例,它的拍照购物准确率以经比四年前提高许多,用户转化率提升了十几倍。
另一个电商零售中的例子是“智能搭配”,其目的不仅是让AI推荐同款商品,还要让AI提供穿搭建议。例如当用户购买上衣时,AI自动搭配一个裙子或者一双鞋,并且生成一段描述,告诉用户“为何如此搭配”。该功能上线之后,其带来的点击率超过了人工搭配。

智能导播应用也是AI比较擅长的。例如足球比赛中会有很多固定的相机,相机中的视频会传递到转播车,然后会有20~30个工作人员不断的制作视频,提供转播流,每个人看到的转播流都是相同的。所谓智能导播是指:用AI学习人类导播的方式,然后根据每个用户的喜好,输出相应的内容。喜欢足球的用户会着重推送精彩的射门、动作;喜欢球星的用户会着重推荐球员的特写,从而达到千人千面的效果。

智能导播涉及的技术比较广泛,例如:动作/事件识别、人脸识别、姿态估计、高光检测、相机视图切换等等。值得一提的是,二十年前,我在微软实习时候,导师就安排过相应的任务,但是由于数据和算力的限制,没有做到很好的效果。两年前,我们才在京东上线该功能。
元宇宙的概念很火热,京东也在数字人方面做了一些尝试。日前也凭借跨模态分析技术、多模态交互数字人技术分别斩获ACM国际多媒体顶级会议的最佳演示奖(Demo)。
传统的数字人只能进行“文字交互”,而今天的数字人希望能够模拟真人进行对话,其特点在于形象、逼真、实时反应等等。目前,数字人技术已经成功在市长热线中部署。
通用AI一直是人类的梦想,迈向通用AI的过程中,在视觉方面必须要从感知过度到认知,如此智能视觉系统才能进行决策。
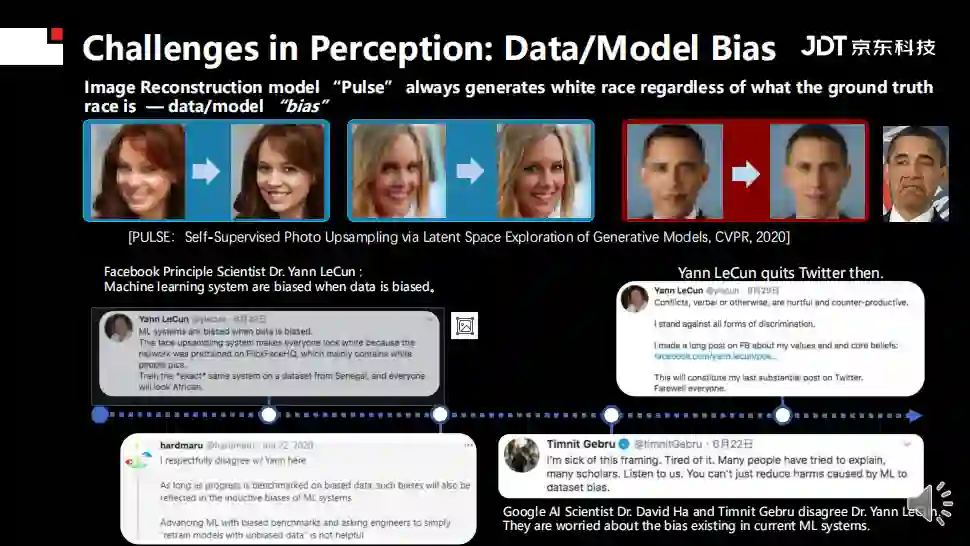
但其中会遇到很多挑战,例如鲁棒性,直接表现在自动驾驶领域,汽车相撞、识别错误等等都表明系统不够鲁棒。模型和数据偏见也是学界经常讨论的焦点,前段时间AI领域的大牛Yann LeCun在推特上因为“偏见来自数据还是来自模型”的发言被diss退网。

认知智能和感知智能的区别主要有两点,在目标层面,传统AI希望增强人类思维并提供准确结果,而认知AI希望模仿人类行为和推理;而在能力层面,传统AI希望找到学习模式或揭示隐藏信息;而认知AI希望能够模型人类思维从而找到解决方案。显然,认知AI将来会有很多用途,例如可信系统、模型解释等等。
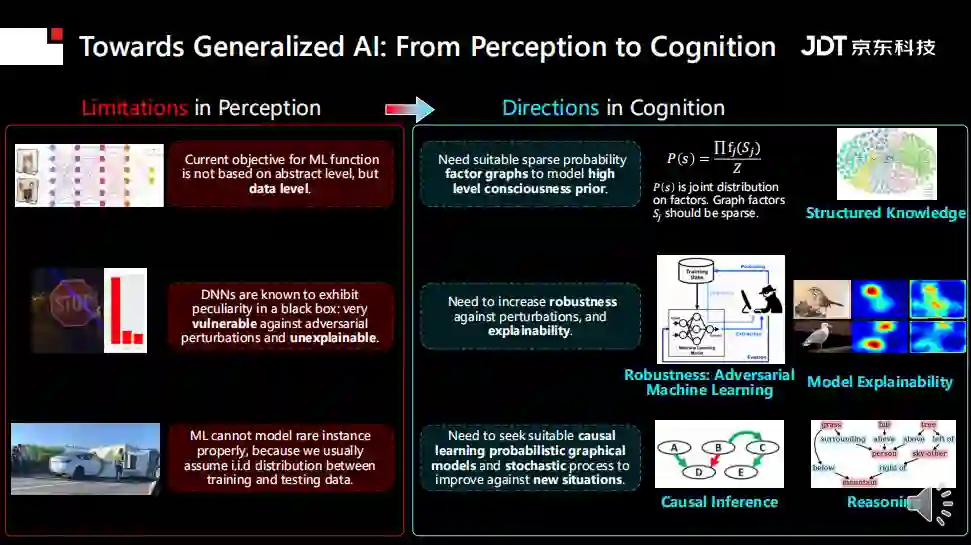
实现认知AI,有三个核心问题要解决:第一,需要考虑如何对结构知识进行建模;第二,如何让模型可解释;第三,如何让系统拥有推理能力。
针对结构知识建模,学界目前已经有一些尝试,例如斯坦福大学李飞飞开发的Visual Genome数据集,华盛顿大学发布的VCR数据集等等。
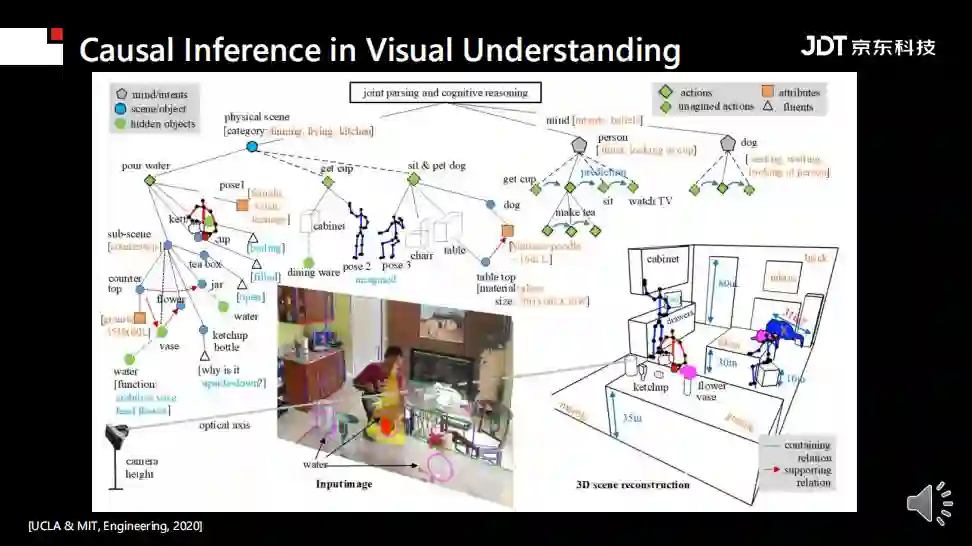
推理方面进展如何?北京通用AI研究院朱松纯教授最近在《中国工程院院刊》中发表论文称:通过 对一张简单图片的分解,计算机视觉系统应该能够同时进行以下工作:1.重建3D场景估算相机参数、材料和照明条件;2.以属性、流态和关系对场景进行层次分析;3.推理智能体(如本例中的人和狗)的意图和信念;4.预测它们在时序上的行为;5.恢复不可见的元素,如水和不可观测的物体状态等。

论文题目:Dark, Beyond Deep: A Paradigm Shift to Cognitive AI with Humanlike Common Sense
论文地址:https://arxiv.org/abs/2004.09044
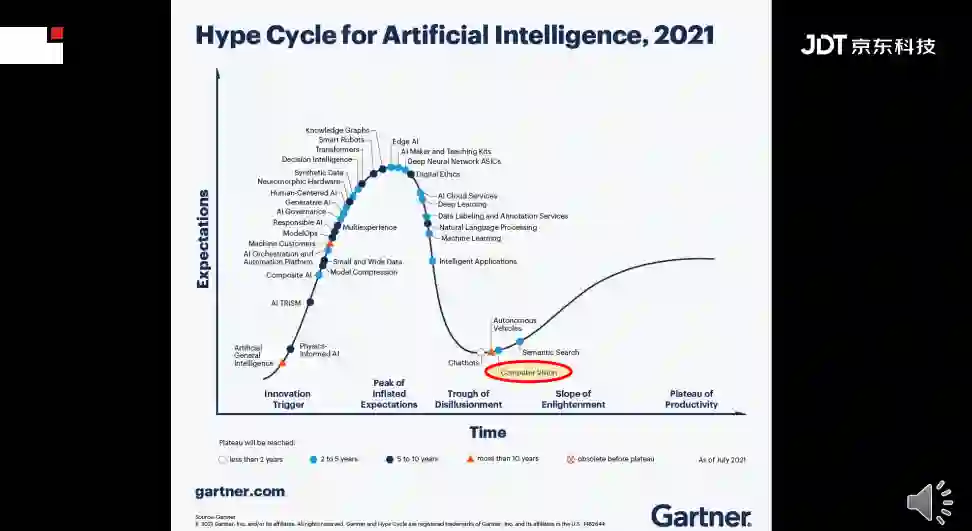
最后,以gartner的一张趋势预见图结束演讲。每一个技术的开始都会经历缺口、泡沫、泡沫破灭以及谷底、理性回归等几个阶段。正如上图所示,通用AI里面的可解释性、可信任都还在爬升阶段,而计算机视觉已经到了第四阶段的尾声,这意味着未来的两三年,计算机视觉会迈向技术成熟阶段,而且会得到大规模的商用,普惠人类生活。
ICCV和CVPR 2021论文和代码下载
后台回复:CVPR2021,即可下载CVPR 2021论文和代码开源的论文合集
后台回复:ICCV2021,即可下载ICCV 2021论文和代码开源的论文合集
后台回复:Transformer综述,即可下载最新的3篇Transformer综述PDF
CVer-Transformer交流群成立
扫码添加CVer助手,可申请加入CVer-Transformer 微信交流群,方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch和TensorFlow等群。
一定要备注:研究方向+地点+学校/公司+昵称(如Transformer+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群
▲长按加小助手微信,进交流群
▲点击上方卡片,关注CVer公众号