学界 | DeepMind提出关系性深度强化学习:在星际争霸2任务中获得最优水平
选自arXiv
作者:Vinicius Zambaldi等
机器之心编译
参与:思源、张倩、王淑婷
自去年 7 月与暴雪共同开放人工智能研究环境 SC2LE 以来,DeepMind 一直没有发表有关星际争霸人工智能的进一步研究。近日,这家公司提出了一种「关系性深度强化学习」方法,并在星际争霸 2 中进行了测试。
在星际争霸 II 学习环境中,DeepMind 的智能体在六个小游戏中达到了当前最优水平,且在四个游戏中的表现超越了大师级人类玩家。这种新型强化学习可以通过结构化感知和关系推理提高常规方法的效率、泛化能力和可解释性。
学习良好的内部表征以告知智能体策略的能力在一定程度上驱动了深度强化学习(RL)[1, 2, 3] 的最新进展。不幸的是,深度学习模型仍然具有重大缺陷,如采样效率低以及往往不能泛化至任务中看似微小的变化 [4, 5, 6, 7]。这些缺陷表明,具有较强能力的深度强化学习模型往往对其所训练的大量数据过度拟合,因此无法理解它们试图解决的问题的抽象性、可解释性和可概括性。
在这里,我们通过利用 20 多年前 RL 文献中的见解在关系 RL(RRL,[ 8,9 ))下来改进深度 RL 体系结构。RRL 主张使用关系状态(和动作)空间和策略表征,将关系学习(或归纳逻辑编程)的泛化能力与强化学习相结合。我们提出了一种将这些优势和深度学习所提供的学习能力相结合的方法。这种方法提倡学习和重复使用的以实体和关系为中心的函数 [10、11、12] 来隐含地推理 [13] 的关系表征。
我们的成果如下:(1)我们创建并分析了一个名为「方块世界」的 RL 任务,该任务以关系推理为明确目标,并证明了具有利用基于注意力的非局部计算来生成关系表征能力的智能体 [14] 与不具备这种能力的智能体相比,表现出有趣的泛化行为;(2)我们将这种智能体应用于一个难题——「星际争霸 II」小游戏 [15]——并在 6 个小游戏上达到了当前最优水平。

图 1:「方块世界」和「星际争霸 II」任务要求对实体及其关系进行推理。
关系性强化学习
RRL 背后的核心思想即通过使用一阶(或关系)语言 [8, 9, 17, 18] 表示状态、动作和策略,将强化学习与关系学习或归纳逻辑编程 [16] 结合起来。从命题转向关系表征有利于目标、状态和动作的泛化,并利用早期学习阶段中获得的知识。此外,关系语言还有利于使用背景知识,而背景知识同时也可以通过与学习问题相关的逻辑事实和规则提供。
例如在「方块世界」的游戏中,当指定背景知识时,参与者可以使用述语 above(S, A, B) 表示状态 S 中方块 A 在方块 B 的上面。这种述语可以用于方块 C 和 D 以及其它目标的学习中。表征性语言、背景和假设形成了归纳性偏置,它能引导并限制智能体搜索良好的策略。语言(或声明性)偏置决定了概念的表现方式。
神经网络传统上就与属性-值、命题性以及强化学习方法 [19] 联系在一起。现在,研究者们将 RRL 的核心思想转化为深度 RL 智能体中结构化指定的归纳偏置,他们使用神经网络模型在结构化的情景表征(实体集合)上执行运算,并通过迭代的方式进行关系推理。其中实体对应着图像的局部区域,且智能体将学习注意关键对象并计算他们成对和更高阶的交互。
架构
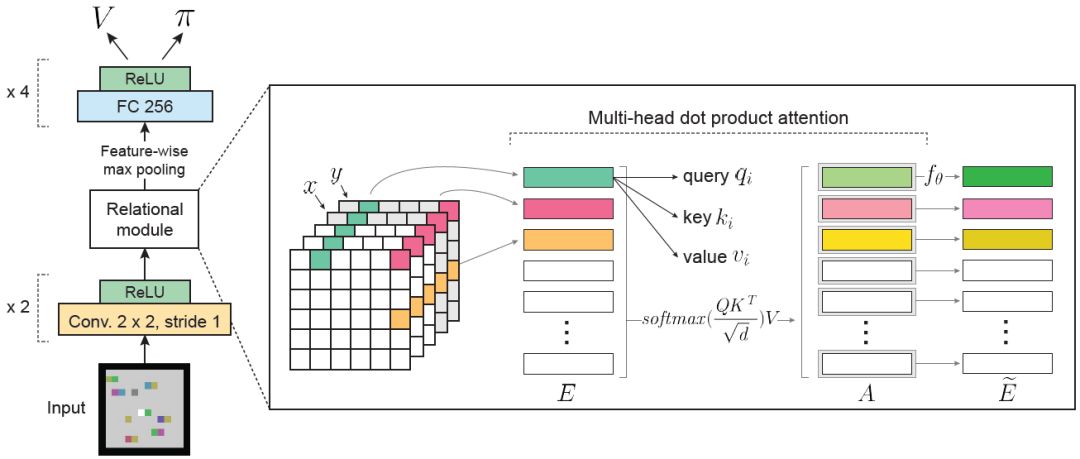
图 2:「方块世界」智能体架构和 Multi-head 点积注意力。E 是一个矩阵,编译视觉前端产生的实体;f_θ是多层感知器,用于平行 MHDPA 步骤 A 的每行输出,并且产生更新的实体 E。
实验和结果
方块世界
「方块世界」是一个感知简单但组合复杂的环境,需要抽象的关系推理和规划。它由一个 12×12 像素的空间组成,钥匙和方块随意散落。这个空间还包含一个智能体,由一个暗灰色像素表示,它可以在四个方向上移动:上、下、左、右(图 1)。
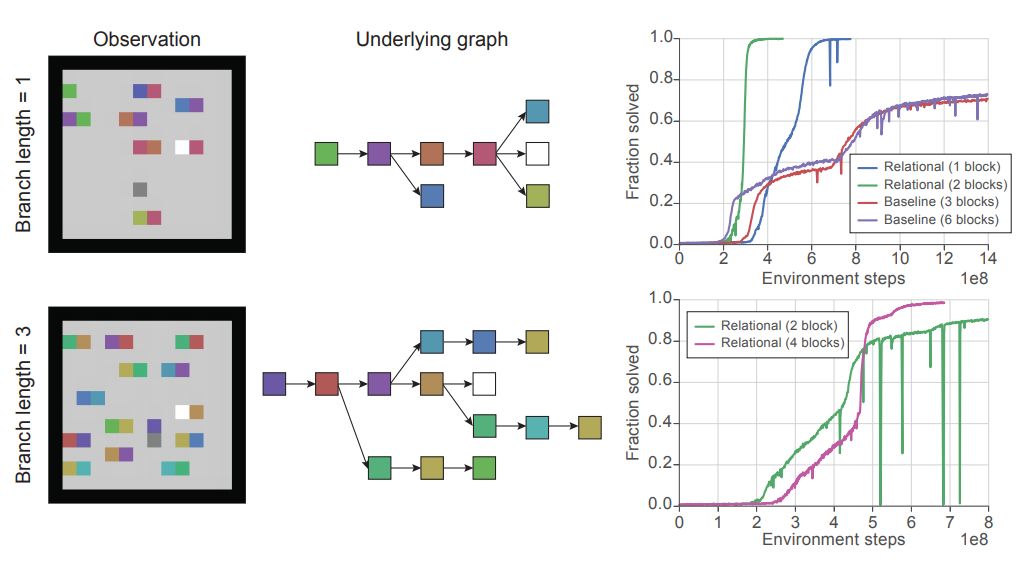
图 3:「方块世界」:观察值示例(左),决定实现目标合适路径的基本图结构及任意干扰分支(中间)和训练曲线(右)。
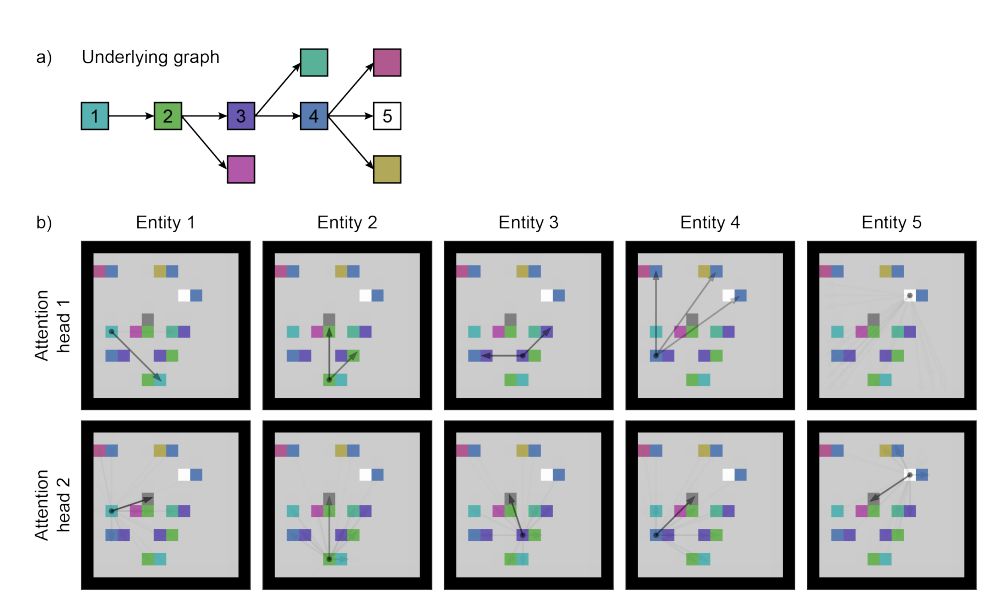
图 4:注意力权重可视化。(a)单样本水平的基本图;(b)该水平上的分析结果,使用解决路径(1-5)中的每个实体作为注意力源。箭头指向源正注意的实体,箭头的透明度由相应的注意力权重决定。
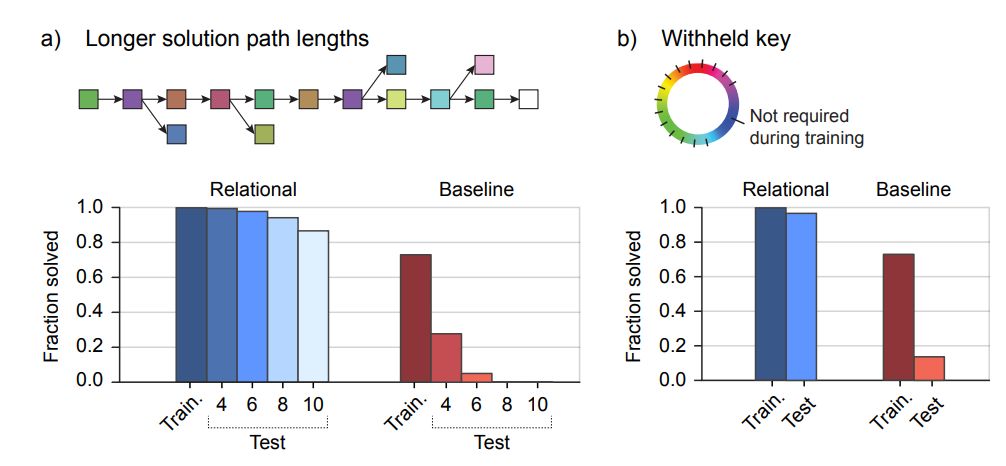
图 5:「方块世界」中的泛化。零样本迁移到需要的水平:(a)打开较长的盒子序列;(b)使用训练期间没用过的锁-钥组合。
星际争霸 II 小游戏
「星际争霸 II」是一种颇受欢迎的电子游戏,为强化学习出了一道棘手的难题。该游戏中有多个智能体,每个玩家控制大量(数百个)需要交互、合作的单位(见图 1)。
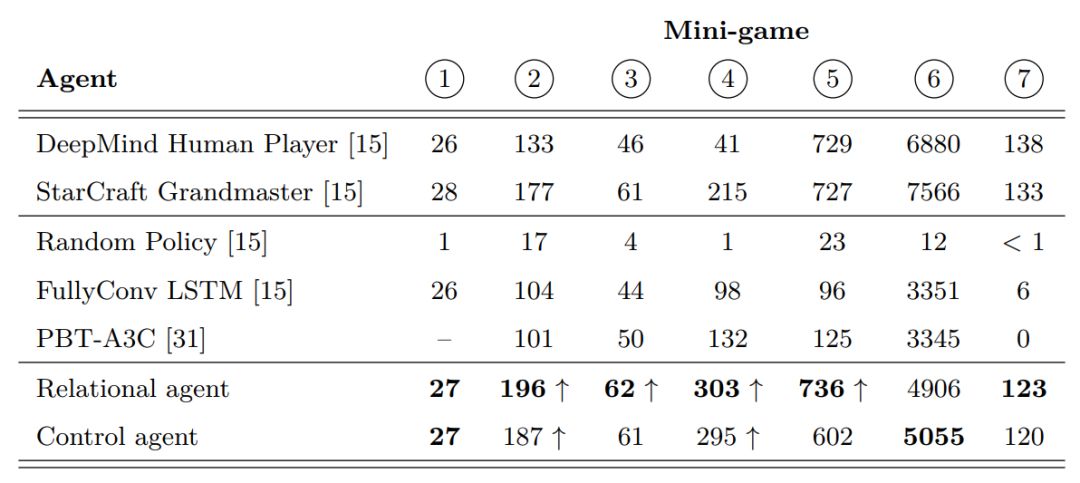
表 1:「星际争霸 II」迷你型游戏中使用全动作组的平均得分。「↑」表示高于大师级人类玩家的分数。小游戏:(1)移动到信标位置;(2)收集晶矿碎片;( 3 ) 发现并打败小狗;(4)打败蟑螂;(5)打败小狗和毒爆虫;(6)收集晶矿和气矿;(7)制造机枪兵。
论文:Relational Deep Reinforcement Learning

论文链接:https://arxiv.org/abs/1806.01830
摘要:在本文中,我们介绍了一种深度强化学习方法,它可以通过结构化感知和关系推理提高常规方法的效率、泛化能力和可解释性。该方法使用自注意力来迭代地推理场景中实体之间的关系并指导 model-free 策略。实验结果表明,在一项名为「方块世界」的导航、规划新任务中,智能体找到了可解释的解决方案,并且在样本复杂性、泛化至比训练期间更复杂场景的能力方面提高了基线水平。在星际争霸 II 学习环境中,智能体在六个小游戏中达到了当前最优水平——在四个游戏中的表现超越了大师级人类玩家。通过考虑架构化归纳偏置,我们的研究为解决深度强化学习中的重要、棘手的问题开辟了新的方向。

本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告 & 商务合作:bd@jiqizhixin.com


