近日,飞桨官方发布了工业级图像分割模型库 PaddleSeg,给开发者带来诚意满满的三重超值惊喜:①一次性开源 15 个官方支持的图像分割领域主流模型,大礼包带来大满足。②多卡训练速度比对标产品快两倍,工业级部署能力,时间节省超痛快。③揭秘包揽了 CVPR2019 LIP 挑战赛人体解析任务大满贯的三冠王 ACE2P 预测模型关键技术,带你一步体验世界领先水平效果。
飞桨的新产品 PaddleSeg 全新上线,重点针对图像分割领域,面向开发者提供了完备且易用的工业级分割模型库。
是的,你没有看错,真正经得起考验的【真. 工业级】的分割模型库。
据介绍,PaddleSeg 已经在百度无人车、AI 开放平台人像分割、小度 P 图和百度地图等多个产品线上应用或实践,在工业质检行业也已经取得了很好的效果。
飞桨官方提供的 PaddleSeg 全景图如下图所示:
![]()
图像语义分割通过给出每一个图像中像素点的标签,实现图像中像素级别的语义分割,它是由图像处理到图像分析的关键步骤。
就像下图中所看到的那样,可以对车辆、马路、人行道等实例进行分割和标记!
![]()
相比于传统的图像分类任务,图像分割显然更难更复杂,
但是,图像分割是图像理解的重要基石,在自动驾驶、无人机、工业质检等应用中都有着举足轻重的地位。
3.1. 一次性开源 15 个图像分割领域主流模型,大礼包带来大满足
PaddleSeg 对所有内置的分割模型都提供了公开数据集下的预训练模型,
全面覆盖了 DeepLabv3+、ICNet、U-Net 等图像分割领域的主流模型实现,并且内置了 ImageNet、COCO、CityScapes 等数据集下的 15 个预训练模型,
15 个预训练模型,请参考 https://github.com/PaddlePaddle/PaddleSeg/blob/master/docs/model_zoo.md
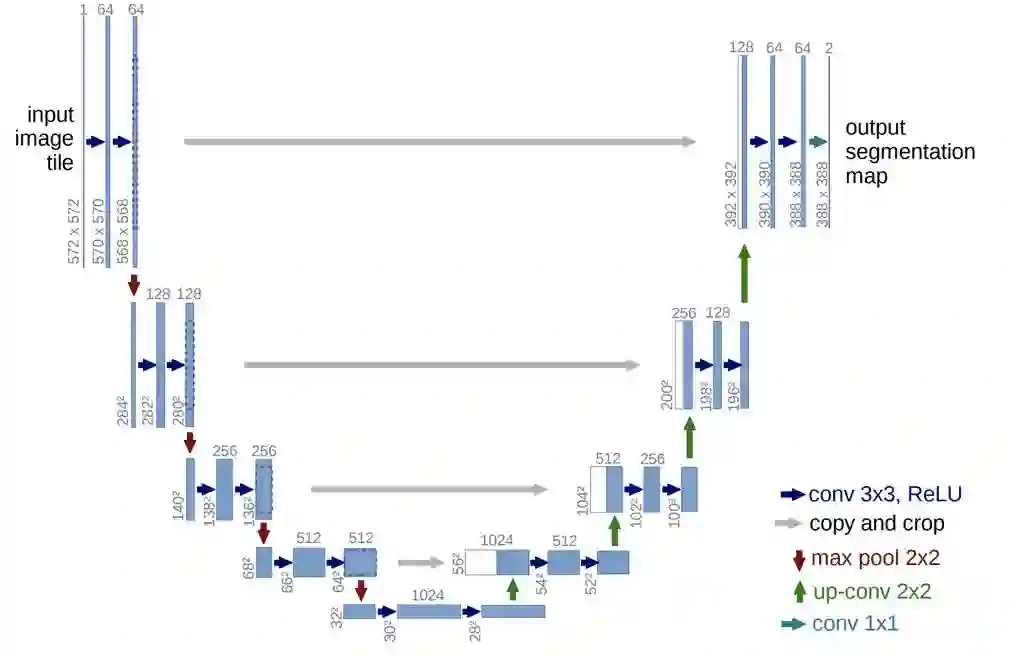
(1)支持 U-Net 模型:轻量级模型,参数少,计算快
U-Net 起源于医疗图像分割,整个网络是标准的 Encoder-Decoder 网络,特点是参数少,计算快,应用性强,对于一般场景的适应度很高。U-Net 的网络结构如下:
![]()
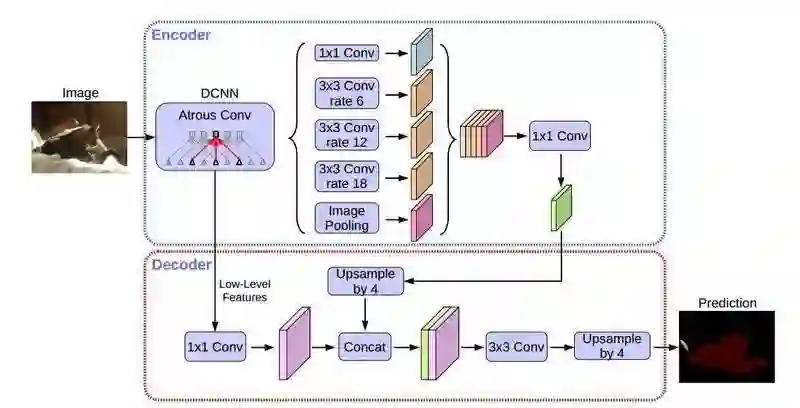
(2)支持 DeepLabv3+模型 :PASCAL VOC SOTA 效果,支持多种 Backbone
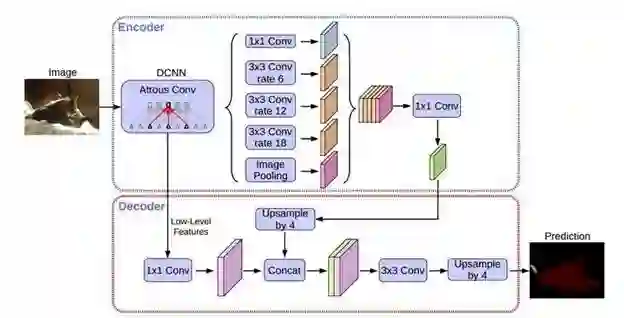
DeepLabv3+是 DeepLab 系列的最后一篇文章,其前作有 DeepLabv1,DeepLabv2, DeepLabv3。在最新作中,DeepLab 的作者通过 Encoder-Decoder 进行多尺度信息的融合,同时保留了原来的空洞卷积和 ASSP 层,其骨干网络使用了 Xception 模型,提高了语义分割的健壮性和运行速率,在 PASCAL VOC 2012 dataset 取得新的 state-of-art performance,即 89.0mIOU。DeepLabv3+的网络结构如下:
![]()
在 PaddleSeg 当前实现中,支持两种分类 Backbone 网络的切换:
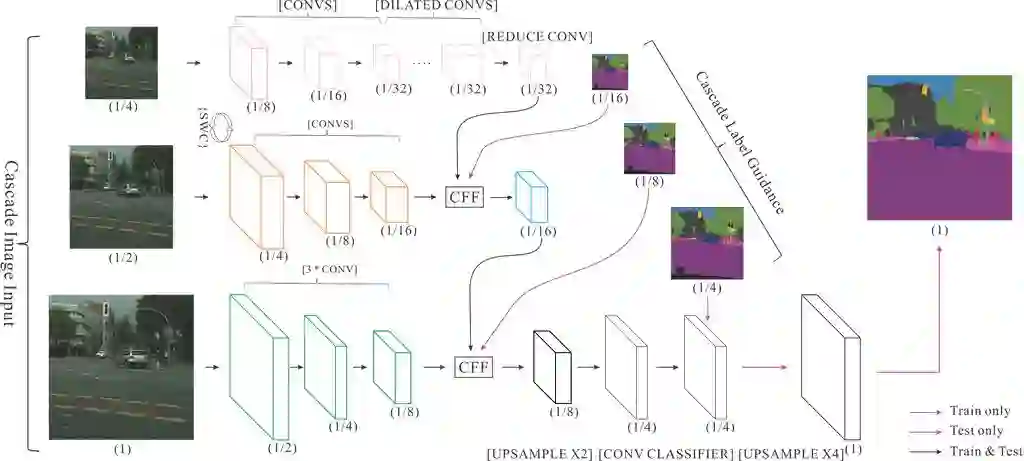
(3)支持 ICNet 模型:实时语义分割,适用于高性能预测场景
ICNet(Image Cascade Network)主要用于图像实时语义分割。相较于其它压缩计算的方法,ICNet 既考虑了速度,也考虑了准确性。ICNet 的主要思想是将输入图像变换为不同的分辨率,然后用不同计算复杂度的子网络计算不同分辨率的输入,然后将结果合并。ICNet 由三个子网络组成,计算复杂度高的网络处理低分辨率输入,计算复杂度低的网络处理分辨率高的网络,通过这种方式在高分辨率图像的准确性和低复杂度网络的效率之间获得平衡。ICNet 的网络结构如下:
![]()
3.2. 多卡训练速度比对标产品快两倍,工业级部署能力,时间节省超痛快
在速度方面,PaddleSeg 也提供了多进程的 I/O、优秀的显存优化策略,性能方面得以大大提升。
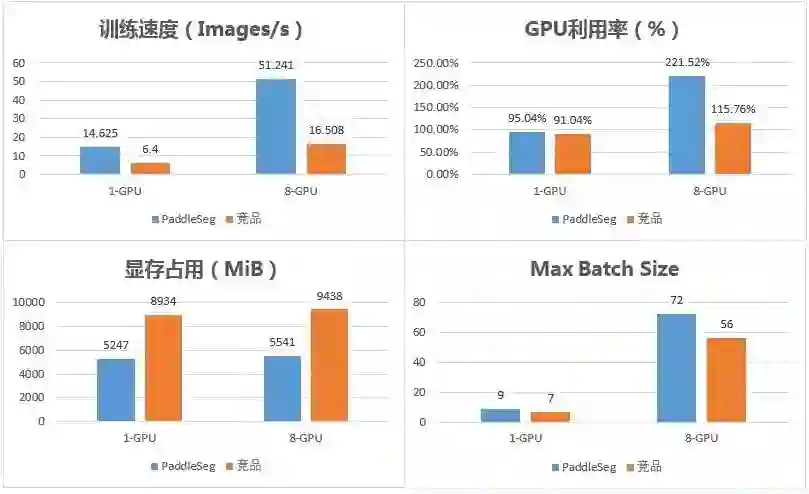
PaddleSeg 的单卡训练速度是对标产品的 2.3 倍,多卡训练速度是对标产品的 3.1 倍。
与对标产品相比,PaddleSeg 在训练速度、GPU 利用率、显存开销和 Max Batch Size 等方面都有着非常显著的优势。详细的对比数据如下图:
![]()
GPU: Nvidia Tesla V100 16G * 8
CPU: Intel(R) Xeon(R) Gold 6148
Model: DeepLabv3+ with Xception65 backbone
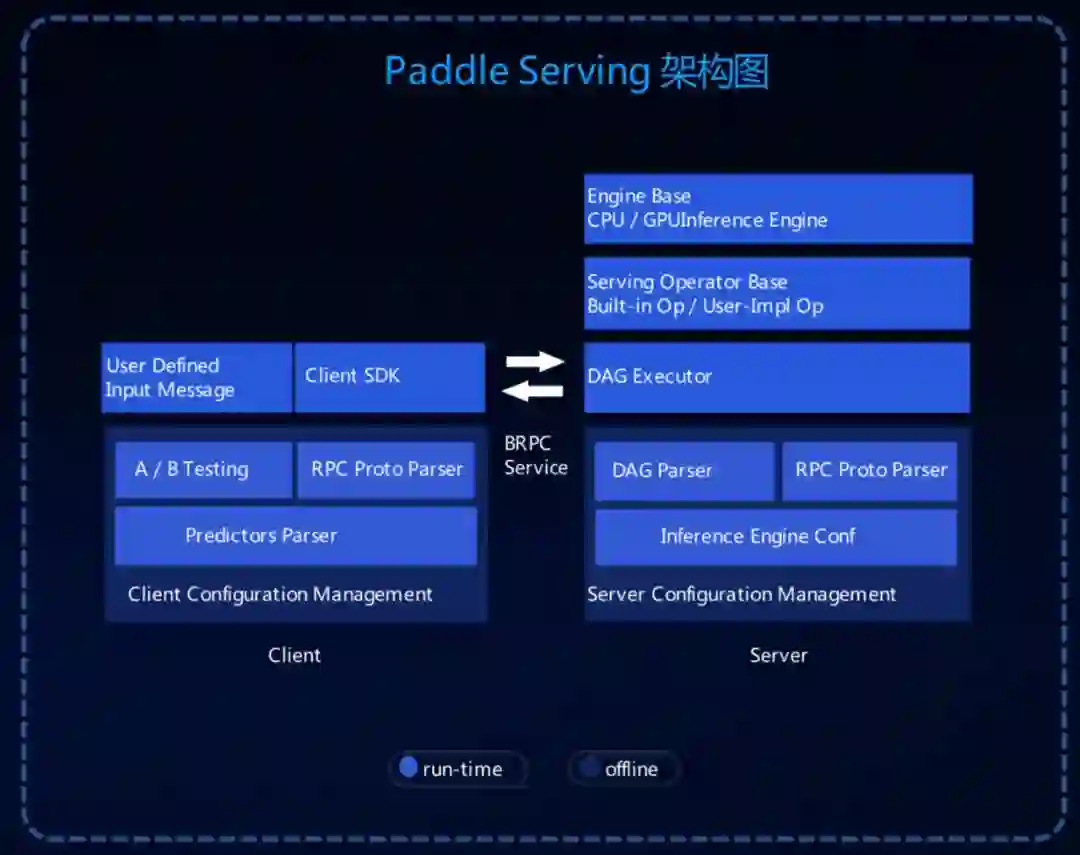
配套的,PaddleSeg 提供了优秀的工业级部署,包括:
![]()
不仅在 Paddle Serving 上可以应用,PaddleSeg 提供的模型还可以通过 Paddle Lite 完成移动端部署,可以很好的适配企业级的业务应用。
特别值得一提的是,考虑到在实际的企业场景中(如互娱场景等),往往存在标注成本高、标注数据少的问题,训练数据相对于整个样本空间的占比是非常小的。此时就很有必要采取数据增强策略,对训练集进行扩充。
PaddleSeg 内置了 10 余种数据增强策略,可以有效地帮助企业进行数据集扩充,显著提升模型的鲁棒性。
使用 PaddleSeg 进行数据增强的流程如下:
![]()
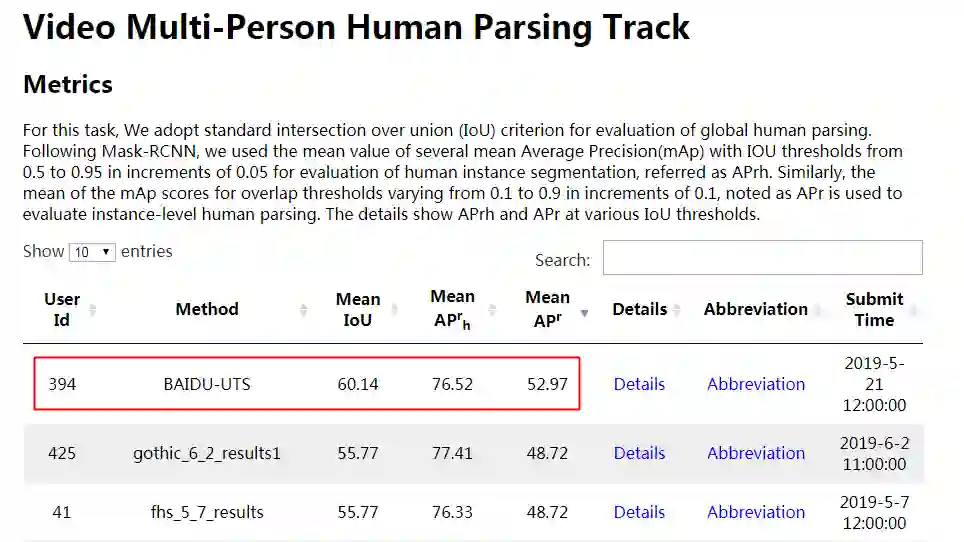
3.3. 提供包揽 CVPR2019 LIP 挑战赛人体解析任务大满贯三冠王 ACE2P 模型,带你一步体验世界领先水平效果。
CVPR2019 LIP 挑战赛中,百度公司实力爆棚,提出的 ACE2P 模型,包揽全部三个人体解析任务的第一名,实至名归的大满贯三冠王。
LIP(Look Into Person) 是人体解析领域重要的 benchmark,其中人体解析 (Human Parsing) 是细粒度的语义分割任务,旨在将图像中的人体分割为多个区域,每个区域对应指定的类别,如面部等身体部位或上衣等服装类别。由于类别的多样性与复杂性,比单纯的人体分割更具有挑战性。
![]()
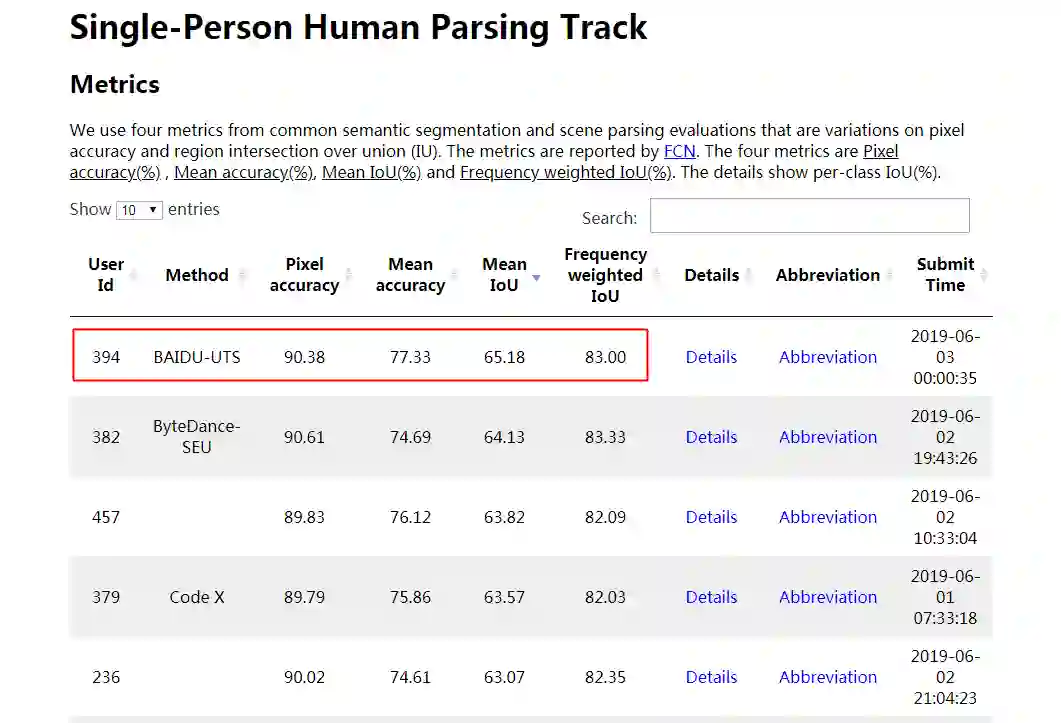
Single-Person Human Parsing Track
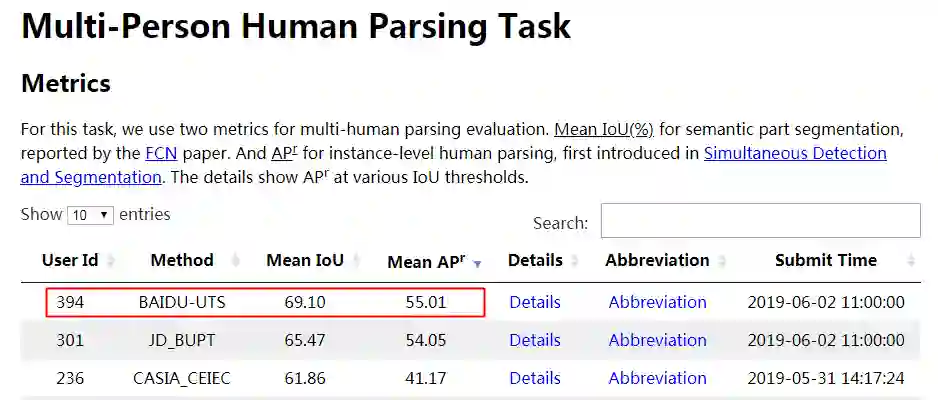
Multi-Person Human Parsing Track
Video Multi-Person Human Parsing Track
全称是 Augmented Context Embedding with Edge Perceiving。
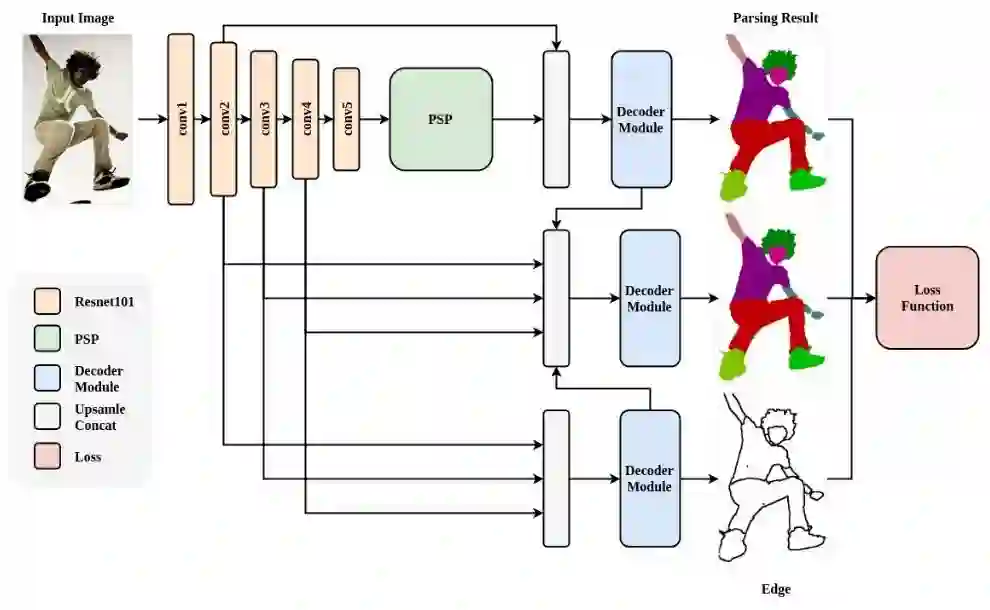
ACE2P 为人体部件分割模型,目的在于分割出图像中的人体部件和服装等部位。该模型通过融合底层特征、全局上下文信息和边缘细节,端到端训练学习人体解析任务。本次发布的模型为 backbone 为 ResNet101 的单一模型,
![]()
CVPR2019 LIP Parsing 的三项榜单全部被百度的 ACE2P 霸榜。
![]()
![]()
![]()
ACE2P 冠军预测模型在 PaddleHub 版本的快速体验命令行直接使用:
![]()
更多内容:https://paddlepaddle.org.cn/hubdetail?name=ace2p&en_category=ImageSegmentation
说了这么多,PaddleSeg 实际效果怎么样,我们用案例说话。
飞桨与国内稀土永磁零件质检领军企业合作,基于 PaddleSeg 模型库,对精密零件的质检工作进行了 AI 赋能升级。
![]()
![]()
传统的工作方式下,质检工人每天需要 8~12 小时在亮光下目视检查直径 45mm 以内零件的质量,工作强度非常大,对视力也有很大的损害。
目前,基于 PaddleSeg 内置 ICNet 模型实现的精密零件智能分拣系统,误收率已低于 0.1%。对于 1K*1K 分辨率的彩色图像,预测速度在 1080Ti 上达到了 25ms,单零件的分拣速度比用其他框架实现的快 20%。PaddleSeg 已帮助工厂达到:生产成本平均降低 15%,工厂效益平均提升 15%。同时,交付质量也大幅提升,投诉率平均降低 30%
分割技术在农业领域也有着广泛的应用,地块分割便是其中一个场景。
传统的地块分割方法,是基于卫星拍摄的遥感影像,依赖于大量拥有遥感专业背景的技术人员使用专业软件来进行分析的。
卫星遥感影像数据存在画幅巨大、肉眼分辨率低的问题,对技术人员的专业要求能力很高,并且人工标注需要大量的重复劳动,非常费时费力和枯燥无味。
如果基于图像分割技术,开发一款地块智能分割系统,快速自动地获知农耕用地边境及面积,就可以更加有效地进行农作物产量预估和农作物分类,辅助农业决策。
![]()
目前,基于 PaddleSeg 内置模型 DeepLabv3 实现的地块智能分割系统,面积提取准确率已达到了 80% 以上,这对作物长势、作物分类、成熟期预测、灾害监测、估产等工作都起到了高效的辅助作用,大大节省了人力成本。
车道线分割,是图像分割在自动驾驶领域的一个重要应用。
准确而快速的车道线分割,能够实时地为车辆提供导航和车道定位指引,提高车辆行驶的安全性,目前正在百度无人车应用实践。
![]()
不仅在工业场景下,在 C 端互娱领域,短视频人像特效、证件照智能抠图、影视后期处理等场景下,都需要对人像进行分割。
![]()
有了这个技术,一寸照片换底色,蓝色、白色、红色轻松切换。
基于 PaddleSeg 实现的人像分割模型,mIoU 指标已经达到了 0.93 以上,并且已经在百度 AI 开放平台上线,合作企业高达 60 余家,是真正的产业利器。
5. 技术干货:LIP 人体部件分割关键技术点揭秘
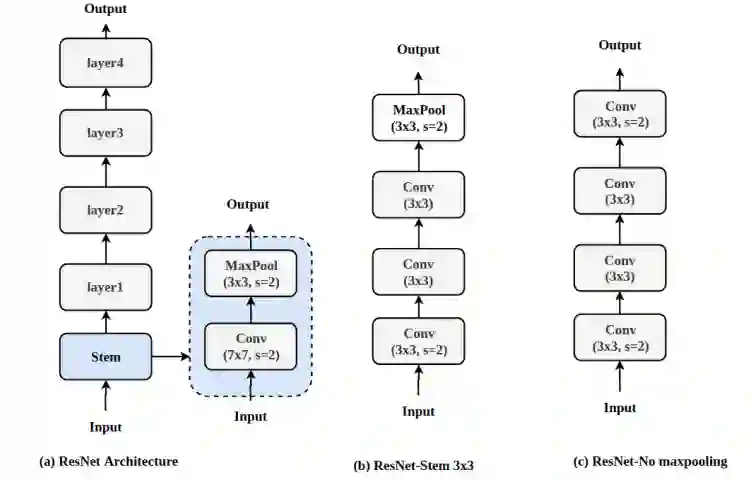
5.1. 修改网络结构,引入扩张卷积(Dilation convolution),提升 1.7 个点
![]()
使用 stride=2 的卷积层替换掉网络中所有的池化层,让下采样过程变得可学习
在 Renset 结构的 stage=5 中加入了 dilation,扩大网络的感受野,增加网络的有效作用区域,使得模型特征更加鲁棒
加入了 pyramid pooling 结构,保证了一个全局的 context 信息的提取。
5.2. 引入了 Lovasz loss,提升 1.3 个点
在实践的过程中我们发现学习方法对最终的效果影响也比较大,所以我们针对任务定制化了学习的方法。
![]()
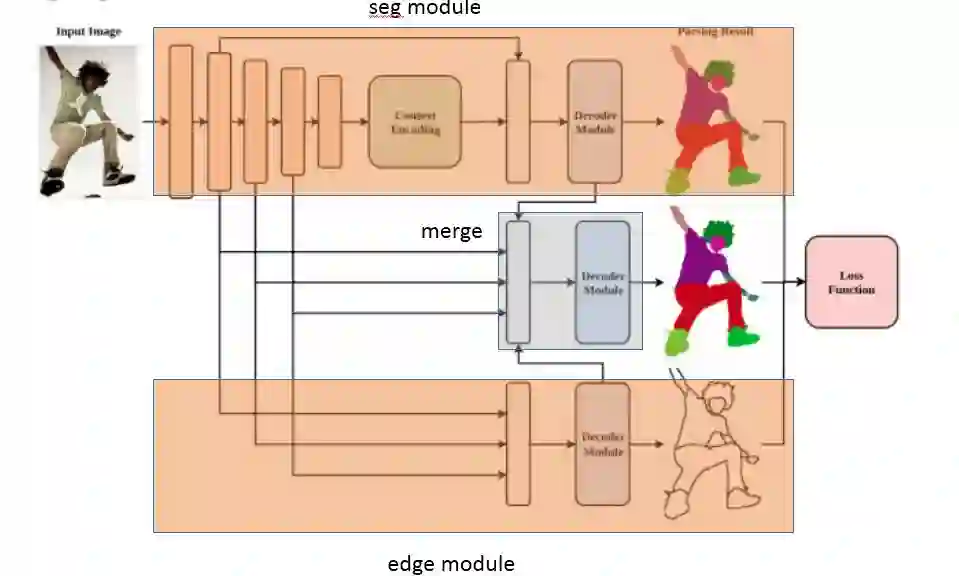
5.4. 加入 edge 模块,提升 1.4 个点
![]()
为了更好的体验分割库的效果,避免因为软硬件环境导致的各种问题,我们采用了 AIStudio 一站式实训开发平台作为体验环境,通过完整的人像分割的实例教程来熟悉 PaddleSeg 的使用
本教程使用 DeepLabv3+ xception 的网络结构进行人像分割。
DeepLabv3+是 DeepLab 语义分割系列网络的最新作,其前作有 DeepLabv1,DeepLabv2, DeepLabv3, 在最新作中,DeepLab 的作者通过 encoder-decoder 进行多尺度信息的融合,同时保留了原来的空洞卷积和 ASSP 层,其骨干网络使用了 Xception 模型,提高了语义分割的健壮性和运行速率,在 PASCAL VOC 2012 dataset 取得新的 state-of-art performance,89.0mIOU。
![]()
Xception 是 DeepLabv3+原始实现的 backbone 网络,兼顾了精度和性能,适用于服务端部署。
项目代码内容都是经过研发人员细心优化并封装好顶层逻辑,可以让开发者最快方式体验 PaddleSeg 的效果,以下代码内容供参考核心流程及思路,实际体验建议开发者完整 Fork 项目并点击全部运行即可。
%cd ~/PaddleSeg/
!mkdir pretrain
!unzip -q -o ~/data/data11874/xception65_pretrained.zip -d pretrain
%cd ~/PaddleSeg/
!mkdir data
!unzip -q -o ~/data/data11874/humanseg_train.zip -d data
第三步:开始训练,其中配置参数「cfg」用于 指定 yaml 配置文件路径, 模型的配置文件位于 configs 文件夹下的.yaml 文件,「use_gpu」用于是否启用 gpu, 由于 cpu 训练过慢,不建议使用 cpu 进行训练
%cd ~/PaddleSeg/
!cp ~/work/humanseg.yml configs/
!python ./pdseg/train.py --cfg ./configs/humanseg.yml --use_gpu
预测可视化 参数「--vis_dir」用于指定预测结果图片存放位置
%cd ~/PaddleSeg/
!python ./pdseg/vis.py --cfg ./configs/humanseg.yml --vis_dir ./visual --
use_gpu
这里,可以任选测试集的数据也可以自己上传数据来测试实际的分割结果。
image_path = "./data/humanseg/test_images/f4963c23694e919b153546c95e3479675a5a13bd.jpg"
mask_path =
"./visual/visual_results/f4963c23694e919b153546c95e3479675a5a13bd.png"
display([image_path, mask_path], 0)
![]()
想了解更多飞桨图像语义分割能力的同学,可以扫描海报二维码或点击阅读原文报名参加9月21日的深度学习实战营↓
![]()