【回顾】用面向对象的神经规划进行文本理解

AI 研习社系列公开课持续进行中,高水平的嘉宾、精彩的分享主题、宽广的学术视角和敏锐的行业理解,肯定会让每个观众 / 读者都有所收获。
【深度好奇】是一家专注于自然语言处理的AI公司,率先提出和发展了基于神经符号系统的机器理解算法,尤其是团队最新提出的面向对象的神经规划(Object-oriented Neural Programming )模型在解析长文本的复杂结构任务中有非常好的效果。
在近期公开课上,深度好奇工程师郑达奇博士做了关于为Object-oriented Neural Programming for Document Understanding 的线上分享。
论文下载地址:http://arxiv.org/abs/1709.08853
▷ 观看完整回顾大概需要 45 分钟
郑达奇,博士期间师从中科院计算所/都柏林城市大学刘群教授,后加入深度好奇。期间作为学术带头人在深度学习用于长文本生成等项目有重要贡献,参与了面向对象的神经规划、非线性文本表示等研究项目。郑博士长期从事机器翻译及人工智能的研究,在自然语言处理和神经符号智能等领域有较深的造诣。
NLP任务需要多少理解?
常见的任务有搜索、文本分类、情感分析、翻译、文本摘要和阅读理解,不同的任务对自然语言理解的深度也有不同的需求。
提到搜索,我们首先想到的是谷歌或者百度,感觉搜出来的结果很准很有用,但实际上原始的搜索只需要用到字符串上的匹配就能做到很好的效果,而字符串匹配所用到的“理解”,即使存在也是非常少的。
文本分类:把一段文本分类到不同的预定义好的类别中去,比如是汽车、体育还是娱乐新闻,这个用朴素贝叶斯方法就能做的不错。文本分类超越了简单类别和文本之间字符串的匹配,可以认为它对自然语言理解的要求要比搜索更近一层,开始入门了。
情感分析:给出一段文本,模型要对给出这段文本的情感进行判断,是正向情绪(比如高兴),还是中立情绪(比如无聊),还是负面情绪(比如悲伤)。得到情感分析的结果后,有些人用它来对股市的走向进行预测。情感分析和文本分类对理解的需求大概处于同一层级。
翻译:翻译任务要比文本分类和情感分析需要更深层次的理解,但是因为翻译问题本身有非常强的语言之间的对齐结构可以利用,所以不用理解也可以达到过得去的效果。即使是不太好的机器翻译结果,哪怕是逐字的翻译,也能为人们阅读外文资料提供一些帮助。当然这个时候,是人在承担实际上的理解工作。
文本摘要:文本摘要需要比翻译更深的自然语言理解。我们通常说掌握的过程就是把书读薄,这个由厚到薄的过程就是文本摘要的工作。这时候并没有翻译中的对齐结构可以利用,而是要判断原文中哪些内容是重要的且必须留下,这种判断需要对文本有更多的理解才能做到。
阅读理解:如果说文本摘要还谈不上深层自然语言理解的话,那比文本摘要需要更深层次理解的就是阅读理解本身了。阅读理解一般不是单纯地以一个任务出现,而是体现在问答之中。类似在语文和英语考试中经常出现的阅读理解大题,我们通常会提出一些问题,考察对材料理解的程度。
在这里特别提一下泛领域问答(即材料和问题都没有限定领域),在问答过程中,会碰到千奇百怪的材料和问题,两者都会带来理解上的困难。现有的NLP技术还不能达到这种程度的理解,知名如苹果的Siri、亚马逊的Echo,哪怕投入大量资源,仍然也只会给出相对机械的回答,很难让人觉得背后有深层次的智能。尤其当它们遇到不理解的问题时,就会顾左右而言他或讲个段子,并不能满足用户对它的真实需求。郑达奇博士认为现有的泛领域问答都有些许走偏,不是正面强推来加深对材料的理解,而是堆砌一些奇技淫巧,使得结果看上去很美。
NLP任务总结图
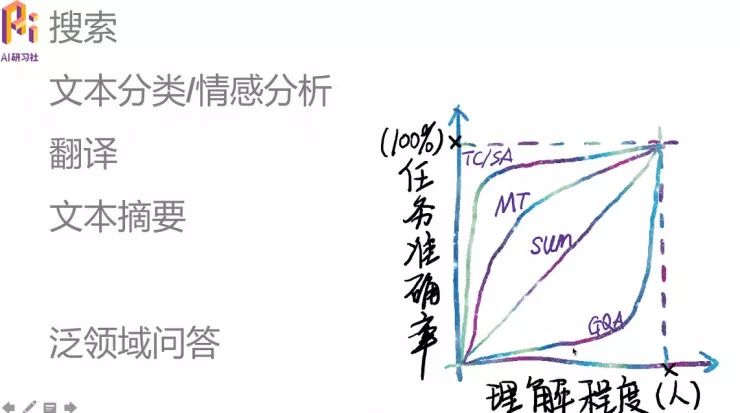
如果把上述NLP任务对理解的需求都总结到一个坐标系中,横轴是理解程度(右侧端点代表人的水平),纵轴是任务准确率(最高100%)。NLP界段子手一般都说有多少人工就有多少智能,郑达奇博士则认为:有多少理解,就有多少智能。
搜索任务更接近纵轴线,几乎不需要理解程度,就可以做到很高的任务准确率。
文本分类\情感分析任务,只需要很少的理解程度就可以有相当高的任务准确率,但后面再增加理解程度,对任务准确度的提高也很有限。(图中TC/SA曲线)
翻译的理解程度,要求可能会比情感分析和文本分类要高一点,就能达到可用的任务准确率水平。(MT曲线)
文本摘要对于文本理解程度的要求差不多是45度的斜线上。(sum曲线)
泛领域问答,情况比较特殊。哪怕做到相当高理解程度,几乎接近于人的理解水平,任务准确率还是达不到满意的效果。何况现在的理解程度还没有达到逼近人的水平。
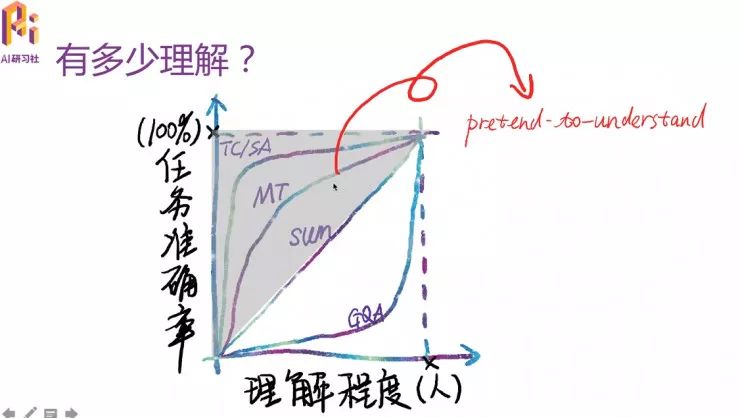
处在上半部分阴影部分的这些任务,严格一点说,可以归纳为pretend-to-understand一类,即:不需要深入理解,就能获得较好性能。下半高亮部分被认为是硬核理解(hard-core understanding ),需要相当深入的理解,才能提高性能表现。如果既不想停留在简单任务假装理解,又不玩奇技淫巧扮演智能的话,敢问路在何方?
--“垂直领域问答(RQA)”是目前唯一的答案。
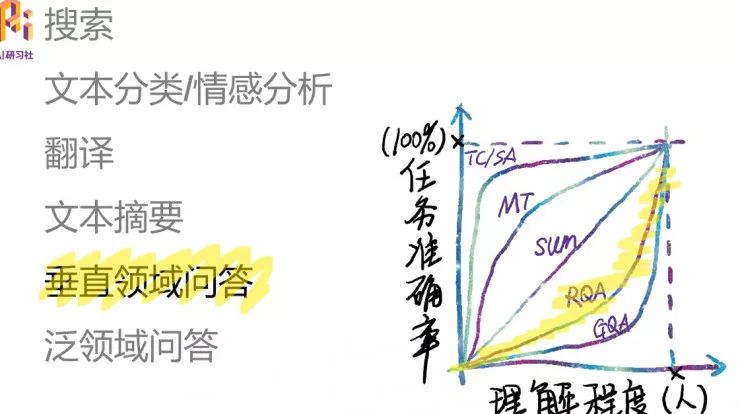
哪个垂直领域问答值得切入?
值得切入的领域有以 下特征,
第一要有钱,有大量的资金投入进来。
第二要有数据,大量的数据是各种模型算法的基本条件。
第三 ,有非常深入的专家知识。领域专家和人工智能专家携手,将领域知识梳理成平衡复杂度和实用性的知识图谱。
哪些领域满足这三点?
例如法律领域、医疗领域、金融领域,其中金融领域已经有一些很热门的应用,比如说kensho。
应该怎么做?
首先是要定义理解这两个字是什么。
理解应该是对应于某一个特定场景下的语用。理解等价于对这个“表示”,能够通过一个“一般性的装置”回答所有相关问题。OONP(Object-oriented Neural Programming )的作用,就是生成这个“表示”。
这个“表示”指的是什么?在深度好奇的任务中就是指案情本体图。
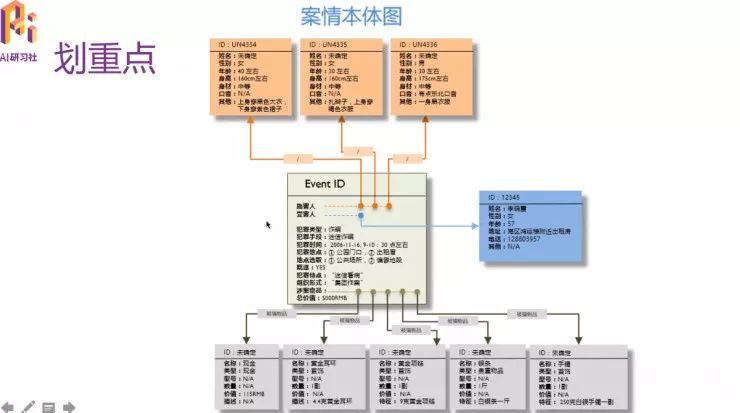
案情本体图分为三大部分,其中位于核心地位的是事件,事件的上方和右方是参与事件的人物,事件的下方是事件中的物品。事件有属性,比如犯罪类型和犯罪手段,这就是区分对象的条件。这样建立出的案情本体图就是以对象为基本单元的。有了这种表示就可以轻松生成各种数据库表,然后就可以用SQL语句在数据库中提取各种数据。
这样的表示是怎样生成的呢?
本体图的生成就是OONP的任务。
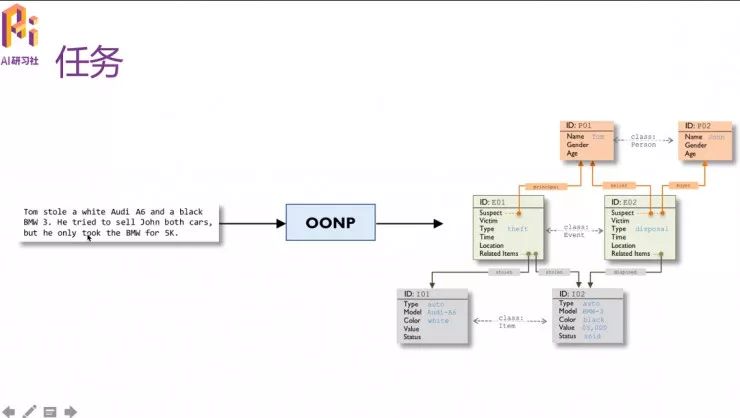
OONP的任务就是在平文本中间进行分析,生成上图的表示。
ONNP模型的全景

ONNP在生成本体图的过程中用到哪些操作呢?
这些操作是离散操作,共有三类:新增/指派操作,选择更新属性操作,更新内容操作。
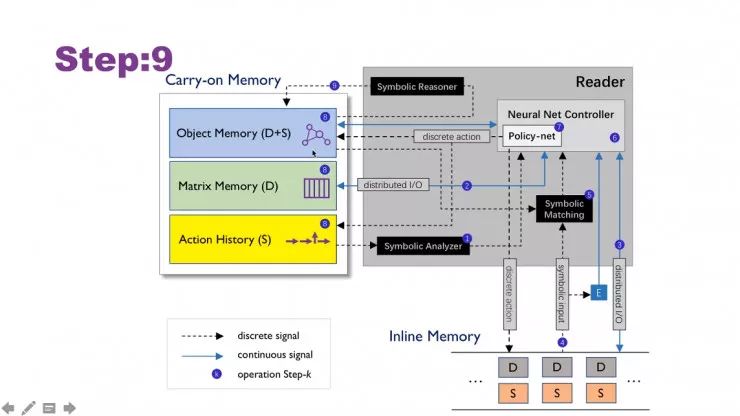
OONP全景的核心是reader,它用来控制携带记忆(carry-on memory)和行间记忆(Inline memory)。在读文本的过程中,一步一步通过不同的操作来生产本体图。
关于memory
主要分为携带记忆和行间记忆。行间记忆就像在读书时在书本上画的波浪线和星号,和文本的顺序高度相关。
携带记忆,则像是写在另一个笔记本上的记忆,和读的文本的顺序没有太多关系,笔记的内容和形式也丰富得多。
行间记忆分为D和S,Distributed Memory是分布式记忆,Symbolic Memory是符号记忆。
它们之间的区别如果用导航来类比,分布式记忆就像在一张没有文字的地图上画出路线,符号记忆则像用短信文字告诉你怎么从出发地走到目的地。
携带记忆又可以进一步细分为三种:对象记忆,矩阵记忆,动作历史。
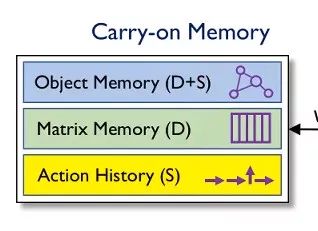
对象记忆:可以认为记录的是许多对象构成的对象图,类似每个对象记在一张小卡片上。对象之间可能有互相的连接关系,表现为对象之间的连线。对象记忆是reader中是最重要的核心部分,包括分布式记忆和符号记忆。
矩阵记忆:是分布式记忆的一个自然拓展,感兴趣的可以了解下神经图灵机,属于纯分布式记忆。
动作历史:记录的是每一步操作的历史,属于纯符号式记忆。
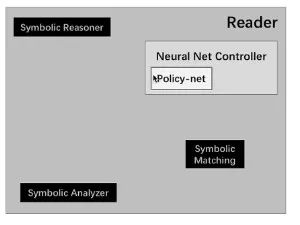
在reader中,处于核心地位的是Neural Net Controller(神经网络控制器)。在Neural Net Controller中,有一款用于增强学习的控制器,叫做Policy-net;除了这个以外,还有另外三款控制器是做符号化操作。(见上图)
各个模块之间具体是怎么操作呢?按照下图的箭头顺序,共分为9步(更详细的解释可以参考课程视频或者原论文)。
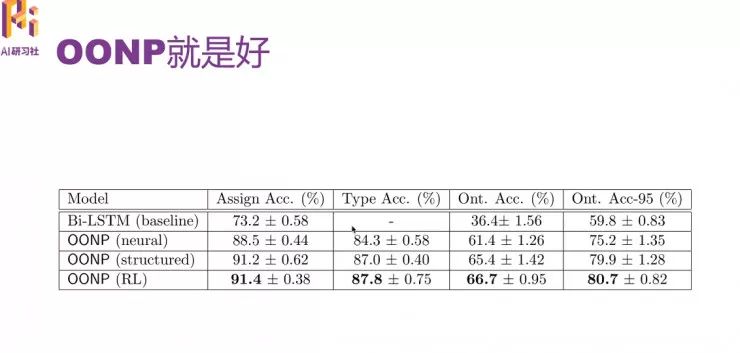
效果好不好,还是要看实验结果说话
OONP的特点以及总结
一句话总结:为了建立“本体结构图”,设计了“语义解析法(OONP)”从而糅合“神经与规则”,训练利用“数据和知识”,最后走上“通向理解之路” 。


新人福利
关注 AI 研习社(okweiwu),回复 1 领取
【超过 1000G 神经网络 / AI / 大数据,教程,论文】
复旦Ph.D沈志强:用于目标检测的DSOD模型(ICCV 2017)
戳阅读原文,查看更多公开课
▼▼▼