从x86到ARM,C和C++实现90%代码自动迁移的方法论

x86 与 ARM 之争,已经贯穿了很长时间,过去一直是 x86 架构比较受到市场和开发者的欢迎。但是自从移动互联网、物联网和边缘计算兴起之后,ARM 似乎已经找到最适合自己生存的土壤。
架构之争的平台技术拐点,已然来临。
现在,每个人手上都有一台智能计算终端,移动应用逐渐云化,5G 催生了云游戏的诞生;Web 应用的加密性越来越重要,HTTPS 流量越来越大;大数据分布式并行计算成为主流等,这些都让 x86 架构的不足逐渐显露出来。
所以才会有现在所遇到的情况,即不得不从 x86 上的应用迁移至 ARM 上。但也正因为这是两个完全不同的平台,所以在迁移过程中会遇到各种各样的问题。这也是 DevRun 开发者沙龙–首期【鹏城实验室 & 华为鲲鹏专场】中所重点讲到的问题之一。
以下内容经由 InfoQ 编辑整理自 DevRun 开发者沙龙【鹏城实验室 & 华为鲲鹏专场】中张永正和杨少洪老师的分享。
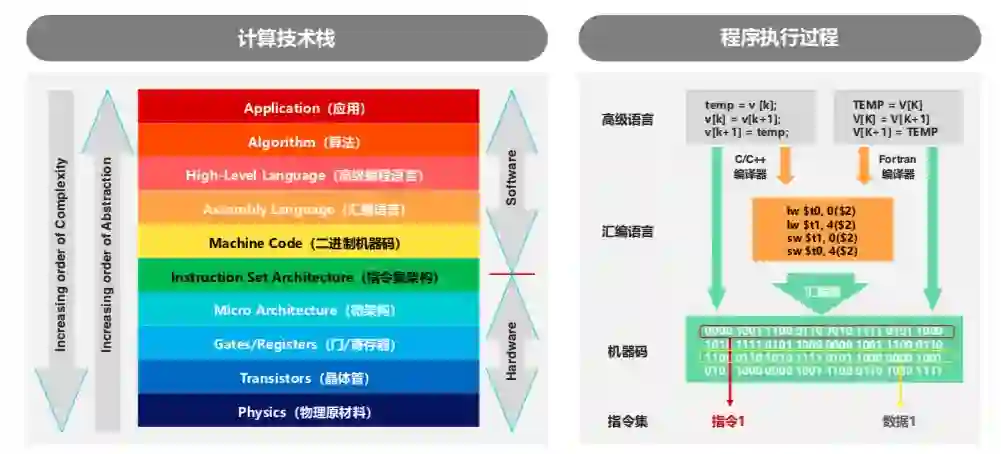
上图所示为程序执行的过程和对应的计算栈。任何一台计算机都是由硬件和软件组成的,类似于最底层的基础物理原材料、晶体管、寄存器、微架构等都属于硬件层面。而软件层面则特指由高级语言、汇编语言开发的应用程序。要执行这些应用程序,需要底层 CPU 支持由汇编器形成二进制的机器码(由指令和数据组成)去运行。
因此就需要底层计算平台能够支持该 CPU 的指令才可以,这也是在 x86 和鲲鹏编译的区别之处。
在 x86 和鯤鹏上编译之后的指令差异是哪些?可以参照下图左侧,显而易见这是一套非常简单的代码,分别在 x86 和鯤鹏上编译之后形成三点指令差异:
首先是汇编不同,x86 上是两条 mov 指令,通过把 A 和 B 的变量从内存当中取到寄存器,并将两值相加,再由一条 mov 指令写回内存;鯤鹏上则是通过两条 ldr 指令、一条 add 指令以及一条 str 指令完成整个过程。
其次是指令长度不同,x86 上 mov 指令是 24 位的,ldr 指令是 16 位的,在鯤鹏上则都是 32 位;第三则是寄存器不同,x86 和鲲鹏处理器使用的向量寄存器不同,其向量指令级也存在差异。
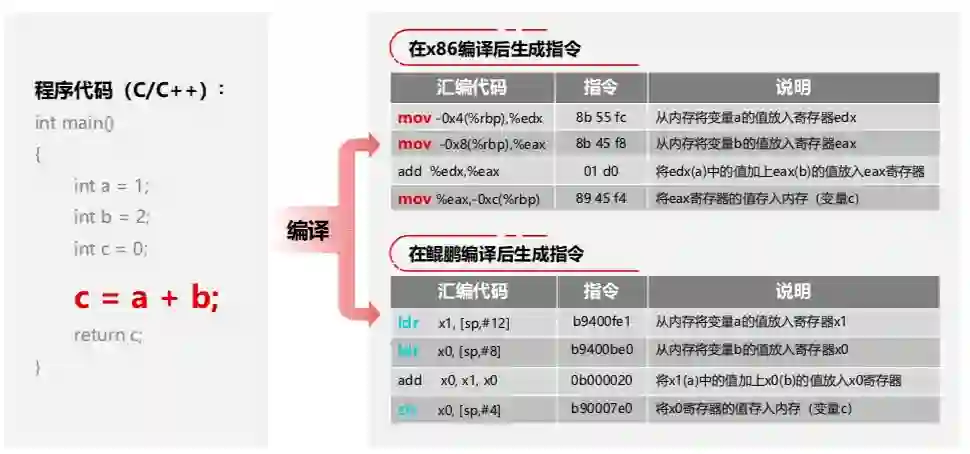
这也正是做迁移的原因,因为在 x86 上所编译出来的应用程序因为有以上三点的不同,因此无法在鲲鹏上直接运行。
从大量的实践中得以总结出一些规律和方法,主要分为以下 5 个步骤:
1、迁移准备,主要以收集硬件信息和软件栈信息为主;
在这期间,主要收集硬件和软件信息。硬件方面的信息主要是收集芯片和服务器的型号,从而方便提供配置性能差不多的鲲鹏服务器;其次是收集软件栈信息,主要分为操作系统、虚拟机、中间件、编译器、上层依赖的开源软件、商业软件、业务软件等信息。
2、迁移分析,对收集到的信息和软件栈做初步分析,判断是否真正需要迁移,评估迁移的工作量;
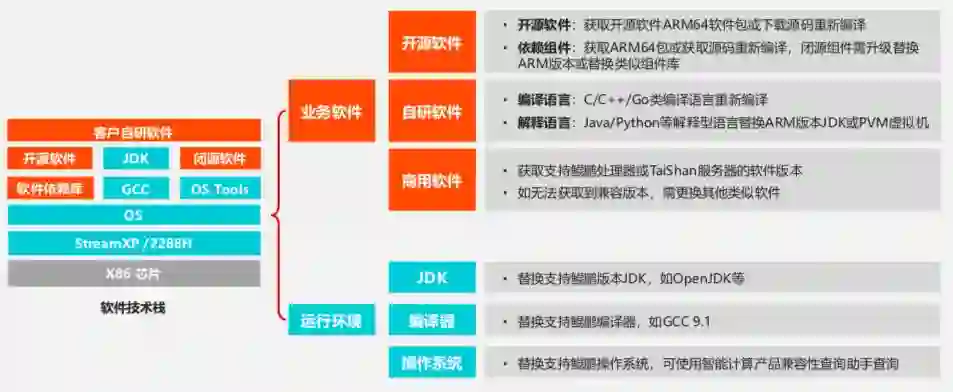
下图左侧就是一个非常完善的技术栈,底层有芯片,中间层为 OS、虚拟机、编译器等相对应的运行环境。上层是业务软件,分为开源、自研和商用软件。
开源软件的迁移相对较为简单,其中一部分开源软件在 ARM 上已经被编译好的包,直接下载即可。即便没有现成的编译成果,自行下载原码进行编译也并不复杂方便;自研软件的迁移需要注意语言类型的差异,编译型语言是需要重新编译之后才能运行在新环境上,但是对于解释型的语言来说就没有重新编译的需要,只要更换所依赖的虚拟机就可以;商用软件则较为麻烦一些,首先可以通过联系厂商获取它对应 ARM 架构下的软件版本,如果没有的话就需要寻找有类似功能的软件做替换。
此外像运行环境、虚拟机、编译器和操作系统这些也是要进行替换,但是这些并非需要重新编译,因为在华为云鯤鹏论坛内有软件仓库,可以直接去软件仓库下载由鲲鹏官方所做的经过验证的版本。
3、编译迁移,分析完成之后就可以着手迁移工作,主要分为代码迁移和软件包迁移;
迁移分析之后可以进行代码的编译和打包,编译主要涉及两个到代码迁移和软件包迁移。
其中代码迁移需要区分语言,像 C/C++ 和指令级的差异是比较大的,因此在 x86 上编译出来的应用程序无法在在鯤鹏上直接使用,因此要在鯤鹏上重新编译才可以。此外编译型语言所涉及的修改点相对更多,因为代码当中有可能蕴含一些对指令级相关的宏定义或者功能性函数;但是对于 Java/Python 这种解释型语言来说就会简单很多。如果是纯 Java/Python 的程序,就无须做编译,因为本身的虚拟机已经对指令级进行了屏蔽,只要更换虚拟机就可以。
对于软件包迁移来说,首先需要扫描该软件包是否存在依赖库或者依赖的可执行程序,这些库和可执行程序如果是用 C 语言写的是需要重新编译的,编译之后重新把软件包打包即可。
4、性能调优,验证完成之后对性能指标进行测试,进行性能调优;
由于大部分软件对性能都有要求,因此在迁移完成之后需要对性能进行调优,这里总结了【建立基准 - 压力测试 - 确定瓶颈 - 实施优化 - 确认效果】这五步法。
首先需要建立调优基准,该基准根据当前的硬件配置、组网、测试模型来做综合评估,以建立合理的条有目标;其次在调优目标建立后,通过压测工具对软件或系统进行加压,在加压过程中暴露性能瓶颈,确定瓶颈之后对瓶颈进行优化;第四,注意在优化过程中要及时记录,因为优化并不一定是正向的,出现负向优化时需要及时回退;最后在优化措施实施完成后,需要重新启动压力测试工具以确认优化效果。
这个过程并非一蹴而就,有可能其中某个步骤需要经过多次循环之后才能达到既定目标。
5、测试与认证,保障商用上线。
和日常软件开发一样,需要对其进行功能、性能、长稳等层层测试,以确保能达到商用标准。此外也可以拿软件和系统到鲲鹏上做鯤鹏展翅认证,其可以扩展应用的软件使用空间并能够加入鲲鹏生态。
C、C++、GO 都是非常典型的编译型语言,编译型语言所开发的程序从 x86 平台移植到鯤鹏平台时一般都需要重新编译才能运行,这点上文也已经提到了。那么为什么需要重新编译才能运行呢?接下来举个简单的例子。

上图为 test.c 的源码文件,首先经过预处理,把代码里面以 # 号开头的代码片断编译为预处理文件,预处理文件再经由编译生成汇编代码。汇编代码经过汇编器生成目标文件,这也就是常说的机器码。然而机器码是无法直接运行的,所以需要联接动态库或者静态库来最终生成可执行文件。
从代码工程的角度看,其可以分为两类:一类是编译构建的脚本,二是源码。在编译构建的脚本中一般会存在 Makefile、cmakelist 等一系列脚本文件,C 和 C++ 的源码一般是有 src、tests 等文件。
那么编译构建脚本类文件在迁移过程中会涉及哪些因素?一般会涉及到编译选项的移植,源码类文件会涉及到编译宏,另外可能还会有编译器自带的 Builtin 函数的移植、SSE intrinsic 函数移植等。需要强调的是这里提到的是迁移过程中可能会涉及到的移植项,但在实际迁移过程中可能只需要编译选项或修改编译宏就可以。
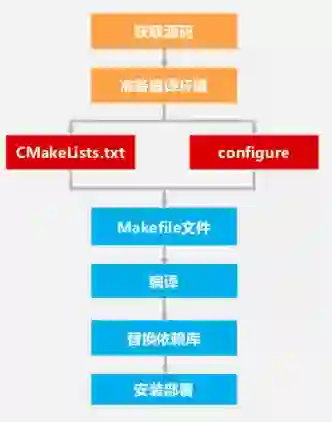
C/C++ 代码编译构建过程
首先要从获取源码开始,可以通过 GitHub 等开源社区来获取;其次需要选择所需的编译环境,就是安装编译器 gcc 等;之后根据源码的编译脚本生成 Makefile 文件,再用 Makefile 编译生成可持续文件。如果这部分代码之中有依赖 x86 平台的 SO 库,那么这部分的依赖库是需要重新编译替换的。在编译完成之后进行安装部署,之后进入到实际的系统之中进行测试。
在对编译构建的流程有基本理解后,就需要深入了解实际迁移过程中所涉及到的各种移植项。
编译脚本和编译选项的移植

以上图为例,其中 x86 下 -m64 代码的主要功能是将应用程序编译为 64 位,对应到鯤鹏上是用 -mabi=lp64 的编译选项。上文有提到这编译选项需要在脚本中修改,对应的 Cmakelists 里有可能存在 add_defin 等多种定义方式。
再看常用的数据类型移植,众所周知 x86 平台上默认的 char 类型是一种有符号的类型,对应到鯤鹏上则是无符号类型。因此在移植过程中需要显示定义并将 char 类型定义为有符号。一种方法是在源代码里加上 signed char,但是缺点是可能改不全从而引发一些不可预知的问题。另一种方法是直接用 fsigned-char 来修改,在不同架构下差异化的编译选项也可以通过 gcc 文档进行查询。
编译宏的移植
如果有相同的代码片断在不同平台下可能会存在不同分支,需要将不同架构下的性能优势发挥到较高水平。但是对于编译器来说,如何才能得知要编译哪些分支代码呢?这就是编译宏的作用。

如果大家对大型开源软件有接触过,相信对上图这些编译选项都不会陌生。gcc 编译器所自带的 x86 编译选项就是 x86_64,对应到鯤鹏平台上是 ark-64。当然除了 gcc 编译器自带的自定义宏,在实际场景中也需要对自研代码进行自定义,在鲲鹏上也是需要进行自定义替换。
不过针对编译宏的替换只是其中一个方面,其最重要的是对编译宏下面的代码实现移植。x86 代码上有些编译器自带自定义宏,比如 smd 属性相关的宏在 x86 上是 SSE 开头的宏,对应到鯤鹏平台上就需要自定义它的编译宏和所相对应的分支。
3.Builtin 函数移植
Builtin 函数是编译器自带的函数,其在实际迁移项目中相当常见,主要是 crc32 校验值的计算。需要移植的普通 builtin 函数实际并不多,大部分需移植的 builtin 函数集中在 SSE intrinsic 函数内。

通过上图可以看到在 x86 平台上其和在鯤鹏平台上是类似的,从命名来看有差异的地方就只存在于架构。
内联汇编函数的移植
内联汇编对于部分开发者来说平时接触的会比较少,所以又可能会感觉到陌生。

上图列举了将字节序进行反序的例子,比如 0X56781314 反序输出的是 0X14137856,x86 上对应的是 bswap 指令,鯤鹏对应的是 rev 指令,其它有些操作和寄存器都是基于内联汇编的语法规则进行替换的。上图的另一个例子是 Builtin 函数,列举了内联汇编转换用鯤鹏上面的 Builtin 函数做替换的例子。比如 popcount 是对二进制数里面的 1 进行计数,对应到鯤鹏平台上所替换的是 popcountll。
5.SSE intrinsic 函数移植(SIMD 技术)
关于 SSE intrinsic 函数的移植,在这之前需要先了解 SIMD 的技术。SIMD(Single Instruction Multi Data) 是一种单指令处理多数据流的并行处理技术,能够在批量数据操作时进行向量 化运算加速,具有较高的执行效率,在多媒体处理、矩阵运算等场景都有广泛的应用。
Intel 的 SIMD 扩展指令统称 SSE,主要分为三类,MMX 是 64 位寄存器,SSE 到 SSE4 是 28 位的,三是 AVX256 和 AVX512。鯤鹏基于 SIMD 的技术发展比较成熟,现在有些基于开源量的 NEON 库主要是在图象处理和视频处理层面。
6.SSE intrinsic 函数移植(MMX/SSE)
经过调用编译器就能够基于 C 函数调用完成对 SIMD 技术的应用,极大方便了开发者。
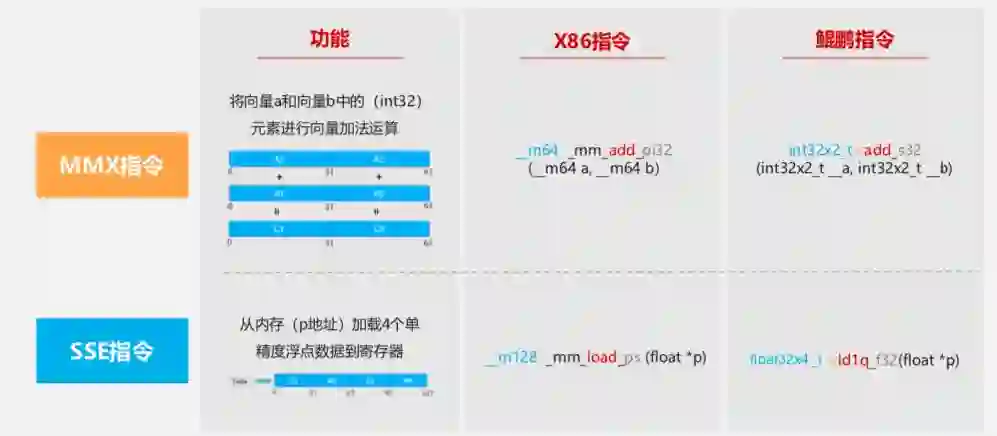
以上图为例,在 x86 上用的是 -m64 的向量,add 是关键字,而且这是加法运算,后面 32 是数据类型。对应到鯤鹏上是 int32×2 然后再做加法运算,这常用的 C 函数规则是类似的。针对 SSE 指令,从内存中加载 4 个单精度浮点数据到寄存器,x86 是 load,对应到鯤鹏用的是 vld1q。
7.SSE intrinsic 函数移植(AVX)
AVX 指令和 MMX 类似,只不过其位数不同。以 AVX 指令使用了 256 位寄存器运算为例,向量 A 和向量 B 中分别存储了 8 个单 精度浮点型 (32 位)。该指令将向量 A 和向量 B 中的 8 个数值分别相加,并将结果以返回值的形式返回 (结果中依然是 8 个单精度浮点型数据) ,最后再从向量寄存器中分别取出 8 个单精度浮点数累加得到结果。
对应到鲲鹏方面,鲲鹏处理器采用精简指令集,使用 128 位寄存器实现 SIMD(Single Instruction Multi Data) 计算。在实现本例 16 个浮点数的相加时,通过两条 vaddq_f32 指令来分别完成,每条指令完成两组共 8 个浮点数算,最后再从向量寄存器中分别取出 8 个浮点数累加。
对于开发者而言,代码和软件迁移是一套必须要掌握的技能。尤其是各种智能终端数量暴涨,物联网飞速发展的当下,x86 平台已经难以适应全生态的发展,从 x86 迁移至 ARM 平台,正是现在的大势所趋。而鲲鹏生态,则为每一位有迁移需求的开发者提供了最便利的工具和环境。没有哪一款平台是最好的,只有最适合业务的那款平台,从 x86 到 ARM,答案正在逐渐清晰。



