什么样的硬件设备在支撑 Stack Overflow?
(点击上方公众号,可快速关注)
英文:Nick Craver,翻译:伯乐在线 - 蒋生武
我更愿意把Stack Overflow看作是能够运行于大规模数据下,但本身并不算大规模的(running with scale but not at scale)。意思是我们的网站非常有效率,但至少目前为止,我们的规模还不够“大”。让我们通过一些数字来介绍Stack Overflow当前是一个怎样的规模吧。以下是一些核心的数字,来自于不久前在一整天(24小时)内的统计,准确说是2013年11月12日。这是一个典型的工作日,并且只统计了我们活动的数据中心,也就是我们自己的服务器。那些对CDN节点的请求和流量被排除在外,因为它们并不直接访问我们的网络。
负载均衡器接受了148,084,833次HTTP请求
其中36,095,312次是加载页面
833,992,982,627 bytes (776 GB) 的HTTP流量用于发送
总共接收了286,574,644,032 bytes (267 GB) 数据
总共发送了1,125,992,557,312 bytes (1,048 GB) 数据
334,572,103次SQL查询(仅包含来自于HTTP请求的)
412,865,051次Redis请求
3,603,418次标签引擎请求
耗时558,224,585 ms (155 hours) 在SQL查询上
耗时99,346,916 ms (27 hours) 在Redis请求上
耗时132,384,059 ms (36 hours) 在标签引擎请求上
耗时2,728,177,045 ms (757 hours) 在ASP.Net程序处理上
(我觉得应该发表一篇文章介绍我们如何快速采集这些数据,以及为什么值得耗费精力去获取它们)
注意以上数字包括了整个Stack Exchange网络,但那并不是我们全部的。除此之外,这些数字也仅仅来自于我们为了检测性能而记录的HTTP请求。“哇,一天有这么多个小时,你们怎么做到的?”我们把这叫做魔法,当然有些人喜欢说成“许多个有多核处理器的服务器”,但我们依然坚持这是魔法。以下是那个数据中心里运行Stack Exchange网络的设备:
4个MS SQL 服务器
11个IIS服务器
2个Redis服务器
3个标签引擎服务(任何针对标签的请求都会访问它们,比如/questions/tagged/c++)
3个ElasticSearch服务器
2个负载均衡器(HAProxy)
2个交换机(Nexus 5596和Fabric Extenders)
2个Cisco 5525-X ASA (可看作是防火墙)
2个Cisco 3945 Router
有图有真相:

我们不仅仅运行网站,旁边架子上还有一些运行着虚拟机的服务器和其他设备,它们并不直接服务于网站,而是进行部署、域名控制、监控、操作数据库等其他工作。上面列表中的两个数据库服务器之前一直都是用作备份,直到最近才作为只读的负载(主要用于Stack Exchange API),于是我们可以不需要太多考虑便继续扩大规模了。Web服务器有两个分别用于开发和存储元数据,运行负载非常低。
核心设备
如果除去那些多余的设备,以下是Stack Exchange运行需要的(保持目前的性能水平):
2个MS SQL服务器(Stack Overflow在一台,其他的在另一台,实际上只需一台机器运行还能有富余)
2个Web服务器(或许3个吧,不过我有信心2个足矣)
1个Redis服务器
1个标签引擎服务器
1个ElasticSearch服务器
1个负载均衡器
1个交换机
1个ASA
1个路由器
(我们真该找个机会尝试这个配置,关闭部分设备,看看极限在哪)
现在还有一些虚拟机运行在后台,执行一些辅助功能,比如域名控制等等。但那都是些相当低负载的任务,我们就不做讨论了,这里把重心放在Stack Overflow本身,看看它是怎样全速加载出页面的。如果你希望更精确全面,可以增加一个VMware虚拟机进来,用于执行所有的辅助工作。这样看来并不需要很多机器,但是这些机器的规格通常在云上难以实现,除非你有足够多的钱。以下是这些“增强型”服务器简要的配置介绍:
数据库服务器有384GB内存和1.8TB的SSD硬盘
Redis服务器有96GB内存
ElasticSearch服务器有196GB内存
标签引擎服务器有着我们能买得起的最快的处理器
交换机每个端口有10Gb的带宽
Web服务器不是很特别,有32GB内存、2个4核处理器和300GB的SSD硬盘
有些服务器有2个10Gb带宽的接口(比如数据库),其他有4个1Gb带宽的
20Gb的带宽太多余了?你还真特么说对了,活动的数据库服务器平均只利用了20Gb通道中的100-200Mb。然而,像备份、重建等等操作,根据当前内存和SSD硬盘的情况,可以使带宽完全饱和,所以说这样设计还是有意义的。
存储设备
我们目前有大约2TB的数据库存储(第一个集群有18块SSD硬盘—— 总共1.63TB,使用1.06TB;第二个集群由4块SSD硬盘组成—— 总共1.45TB,使用889GB),这是我们在云服务器上需要的(嗯哼,又要吐槽价格了吧),请记住这全部都是SSD硬盘。归功于存储器良好的表现,我们数据库的平均写入时间是0毫秒,甚至超出我们能度量的精度了。算上内存中的数据以及两级缓存,Stack Overflow中实际的数据库读写比例是40:60。你没看错,60%是写操作(点此了解读写比)。此外,每个Web服务器都有两块320GB SSD硬盘组成的RAID1。ElasticSearch在每个区块大约需要300GB的容量,由于我们会非常频繁的写入或重建索引,SSD硬盘在这里是更好的选择。
值得注意的是我们拥有一个SAN(存储区域网络)连接到核心网络,那就是 Equal Logic PS6110X,它有24个可热交换的10K SAS磁盘和2个10Gb的控制器。这个设备仅仅被VM服务器用作共享储存空间以保证虚拟机高度的可用性,但并不实际支撑网站的运行。换句话说,如果SAN挂掉了,在一段时间内网站甚至无法察觉(只有虚拟机中的域名控制器能感知到)。
整合到一起
这所有的设备在一起是为了什么?性能。我们需要很高的性能,这是一个对我们来说很重要的特性。所有站点的首页都是问题页面,我们内部把它亲切地称作Question/Show(路由的名字)。在11月12日,这个页面平均渲染时间是28毫秒,而我们的要求是至多50ms。为了使用户获得更好的体验,我们尽一切可能缩短页面加载的时间,哪怕只有一毫秒。在和性能有关的问题上,我们所有的开发人员都是“锱铢必较”的,这也有助于我们的网站保持快速响应。以下是一些Stack Overflow上热门页面的平均渲染时间,数据还是来自于前面统计的那24小时:
Question/Show: 28 ms (2970万次点击)
User Profiles: 39 ms (170万次点击)
Question List: 78 ms (110万次点击)
Home page: 65 ms (100万次点击) (这对我们来说已经很慢了,Kevin Montrose正在着手修复这个问题)
凭借对每一次请求的时间线的记录,我们能够准确观察到页面加载的过程。我们需要这样的数据,否则难道靠脑补来做决定吗?有数据在手,我们就可以这样监控性能:
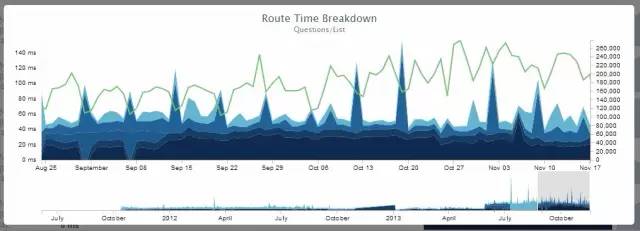
如果你对某个特定页面的数据感兴趣,我也很乐意发布出来。但这里我重点关注渲染时间,因为它表示我们的服务器需要多久来生成一个网页。网络传输速度是一个完全不同的话题了(尽管不得不承认它也有很大的关系),不过将来我会讲到的。
增长空间
非常值得一提的是我们这些服务器运行时的使用率都非常低。比如Web服务器的CPU平均使用率为5-15%,内存只使用了15.5GB,网络流量只有20-40Mb/s;而数据库服务器CPU平均使用率为5-10%,使用了365GB内存,以及100-200Mb/s的网络。这使我们能做到几件重要的事情:在网站规模增大时不至于需要马上升级设备;当出现问题时(错误的查询、代码以及攻击等等,无论是什么样的问题),我们能保持网站始终不挂;在必要的时候降低功耗。这里有个我们Web层的监控项目:
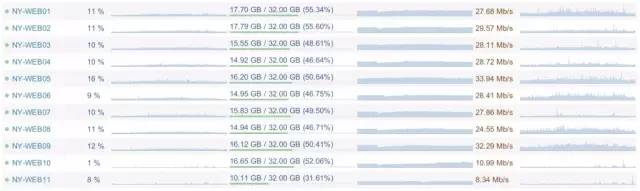
利用率如此之低的主要原因是高效的代码。尽管本文的主题并不是这个,但是高效的代码对挖掘服务器的性能也有着决定性的作用。做一件非必要的事情所损失的,居然比无所作为还要多——把这引申到代码中就是说,你需要把它们改进得更高效了。这些损失或者消耗可以是能源、硬件(你需要更多更快的服务器)、开发人员理解代码更困难(平心而论,这个有两面性,高效的代码并不一定那么简单),以及缓慢的页面渲染——可能导致用户更少地浏览网站其他页面甚至再也不访问你的网站了。低效率代码带来的损失可能比你想象的大很多。
现在我们了解了Stack Overflow运行在怎样的硬件上,下次可以讨论一下为何我们不使用云。
看完本文有收获?请转发分享给更多人
关注「数据库开发」,提升 DB 技能






