中科大陈小平教授:《图灵假说70年:两类AI与封闭性挑战》

关于人工智能技术进展,过去几年很多人往往只关注一类技术,其实值得关注的不止一类。考虑到人工智能技术种类太多,我只总结了其中的两种AI经典思维,而这两种经典思维都符合封闭性准则。今天我重点讲封闭性给我们带来的挑战,定义这种挑战到底是什么。中科大机器人团队为了超越封闭性,提出了一条称为“开放知识”(openknowledge)的技术路线,我会简要介绍过去10年中我们在这个方向上的主要工作和进展情况。
图灵假说和两类人工智能
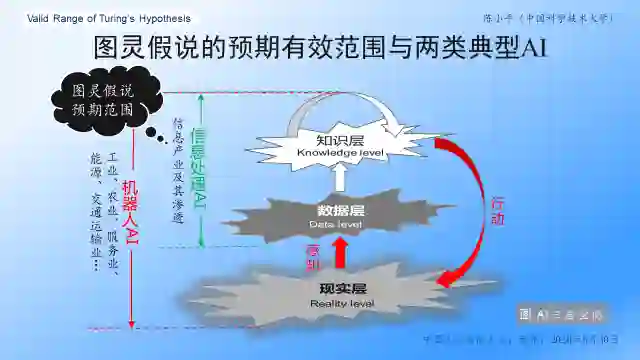
图1 图灵假说与两类典型AI
两种AI经典思维

图2 模型、推理与降射
封闭性的基础研究挑战
超越封闭性:开放知识技术路线
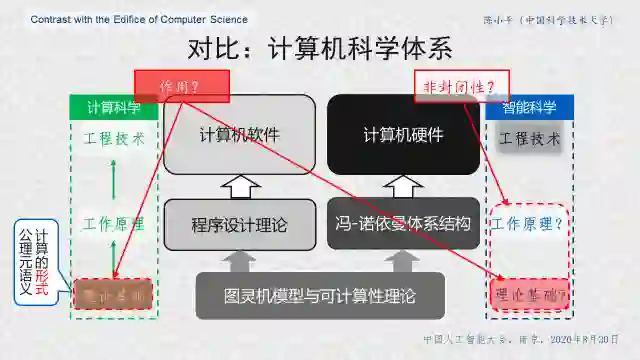
图3 对比计算机科学体系
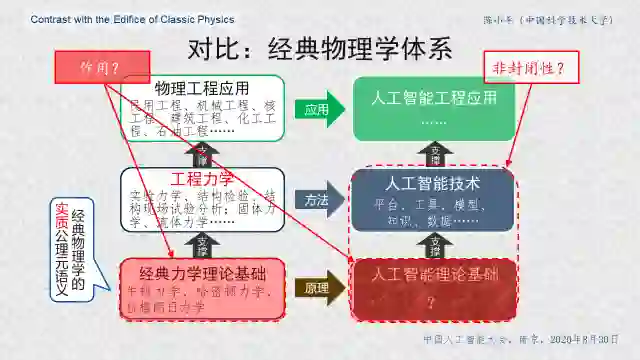
图4 对比经典物理学体系
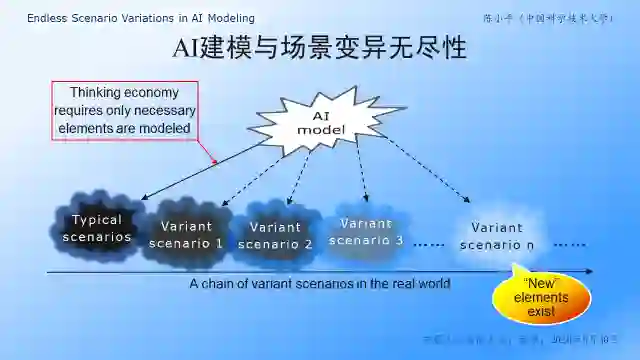
图5 场景变异无尽性
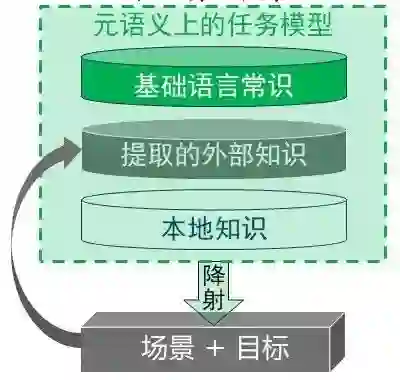
图6 OK体系结构
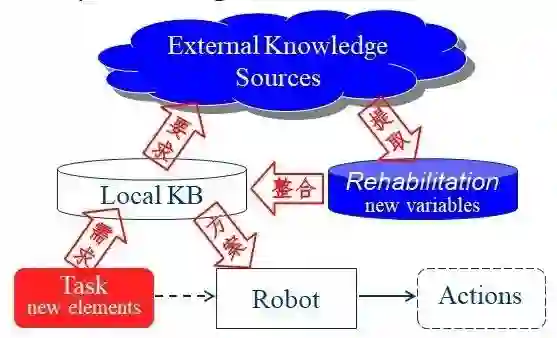
图7 知识修复问题
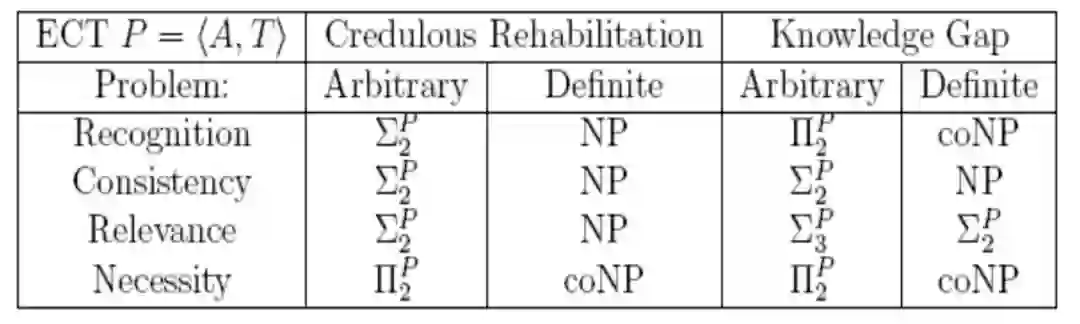
表1 知识修复问题的计算复杂性结果

图8 “可佳”机器人自主操作微波炉加热食品

图9 不同刚度物体无力反馈的融差操作
参考文献

登录查看更多
相关内容

Arxiv
0+阅读 · 2020年11月28日
Arxiv
0+阅读 · 2020年11月27日




相关VIP内容
相关资讯