

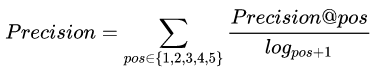


\下面是广告时间,不看我也不怪你/
\反正发财了也没有我的份/

新人福利
关注 AI 研习社(okweiwu),回复 1 领取
【超过 1000G 神经网络 / AI / 大数据,教程,论文】

后台回复 “我要进群” 加入 AI 技术讨论群
可能是最好玩的深度学习模型:CycleGAN 的原理与实验详解
▼▼▼
七月,酷暑难耐,认识的几位同学参加知乎看山杯,均取得不错的排名。当时天池 AI 医疗大赛初赛结束,官方正在为复赛进行平台调试,复赛时间一拖再拖。看着几位同学在比赛中排名都还很不错,于是决定抽空试一试。结果一发不可收拾,又找了两个同学一起组队(队伍 init)以至于整个暑假都投入到这个比赛之中,并最终以一定的优势夺得第一名(参见最终排名 )
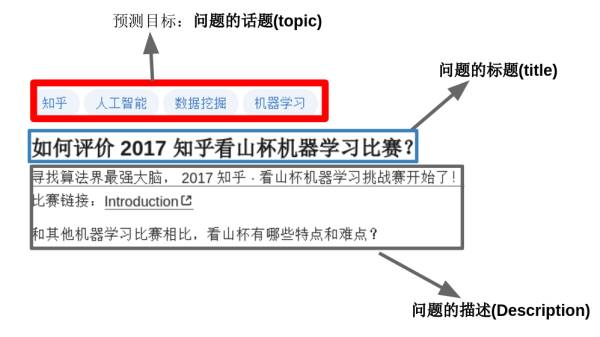
这是一个文本多分类的问题:目标是 “参赛者根据知乎给出的问题及话题标签的绑定关系的训练数据,训练出对未标注数据自动标注的模型”。通俗点讲就是:当用户在知乎上提问题时,程序要能够根据问题的内容自动为其添加话题标签。一个问题可能对应着多个话题标签,如下图所示。
这是一个文本多分类,多 label 的分类问题(一个样本可能属于多个类别)。总共有 300 万条问题 - 话题对,超过 2 亿词,4 亿字,共 1999 个类别。
比赛源码(PyTorch 实现)GitHub 地址 https://github.com/chenyuntc/PyTorchText
比赛官网: https://biendata.com/competition/zhihu/
比赛结果官方通告: https://zhuanlan.zhihu.com/p/28912353
参考 https://biendata.com/competition/zhihu/data/
总的来说就是:
数据经过脱敏处理,看到的不是 “如何评价 2017 知乎看山杯机器学习比赛”,而是 “w2w34w234w54w909w2343w1"这种经过映射的词的形式,或者是”c13c44c4c5642c782c934c02c2309c42c13c234c97c8425c98c4c340" 这种经过映射的字的形式。
因为词和字经过脱敏处理,所以无法使用第三方的词向量,官方特地提供了预训练好的词向量,即 char_embedding.txt 和 word_embedding.txt ,都是 256 维。
主办方提供了 1999 个类别的描述和类别之间的父子关系(比如机器学习的父话题是人工智能,统计学和计算机科学),但这个知识没有用上。
训练集包含 300 万条问题的标题(title),问题的描述(description)和问题的话题(topic)
测试集包含 21 万条问题的标题(title), 问题的描述 (description),需要给出最有可能的 5 个话题(topic)
数据处理主要包括两部分:
char_embedding.txt 和 word_embedding.txt 转为 numpy 格式,这个很简单,直接使用 word2vec 的 python 工具即可
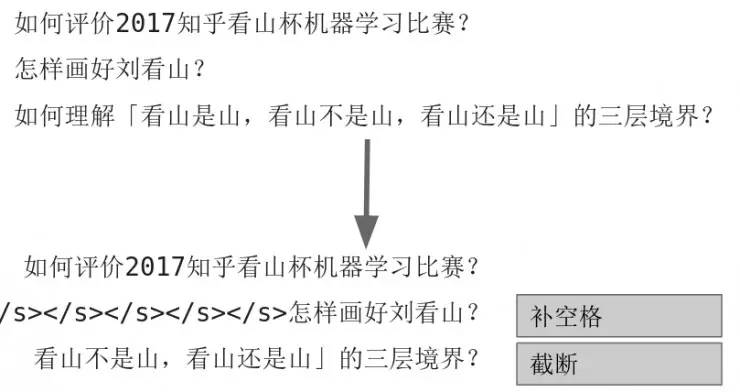
对于不同长度的问题文本,pad 和截断成一样长度的(利用 pad_sequence 函数,也可以自己写代码 pad)。太短的就补空格,太长的就截断。操作图示如下:
文本中数据增强不太常见,这里我们使用了 shuffle 和 drop 两种数据增强,前者打乱词顺序,后者随机的删除掉某些词。效果举例如图:
每个预测样本,提供最有可能的五个话题标签,计算加权后的准确率和召回率,再计算 F1 值。注意准确率是加权累加的,意味着越靠前的正确预测对分数贡献越大,同时也意味着准确率可能高于 1,但是 F1 值计算的时候分子没有乘以 2,所以 0.5 是很难达到的。
具体评价指标说明请参照
https://biendata.com/competition/zhihu/evaluation/
建议大家先阅读这篇文章,了解文本多分类问题几个常用模型:用深度学习(CNN RNN Attention)解决大规模文本分类问题 ( https://zhuanlan.zhihu.com/p/25928551 )
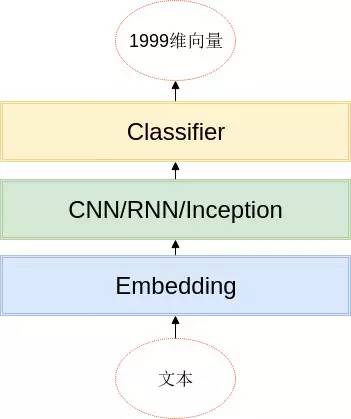
文本分类的模型很多,这次比赛中用到的模型基本上都遵循以下的架构:
基本思路就是,词(或者字)经过 embedding 层之后,利用 CNN/RNN 等结构,提取局部信息、全局信息或上下文信息,利用分类器进行分类,分类器的是由两层全连接层组成的。
在开始介绍每个模型之前,这里先下个结论:
当模型复杂到一定程度的时候,不同模型的分数差距很小!
这是最经典的文本分类模型,这里就不细说了,模型架构如下图:
和原始的论文的区别就在于:
使用两层卷积
使用更多的卷积核,更多尺度的卷积核
使用了 BatchNorm
分类的时候使用了两层的全连接
总之就是更深,更复杂。不过卷积核的尺寸设计的不够合理,导致感受野差距过大。
没找到论文,我就凭感觉实现了一下:
相比于其他人的做法,这里的不同点在于:
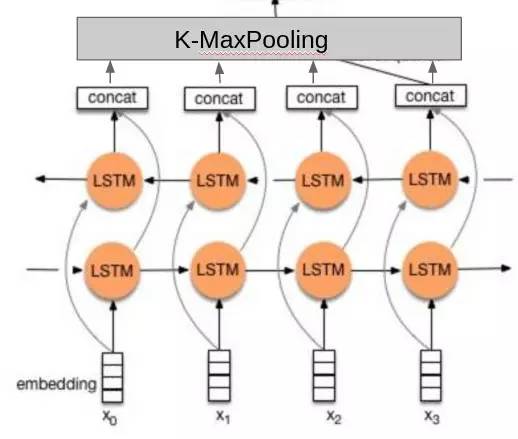
使用了两层的双向 LSTM。
分类的时候不是只使用最后一个隐藏元的输出,而是把所有隐藏元的输出做 K-MaxPooling 再分类。
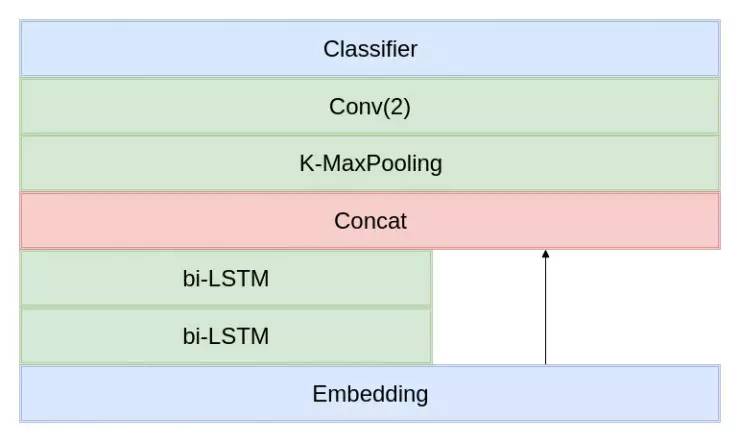
参考原论文的实现,和 RNN 类似,也是两层双向 LSTM,但是需要和 Embedding 层的输出 Concat(类似于 resnet 的 shortcut 直连)。
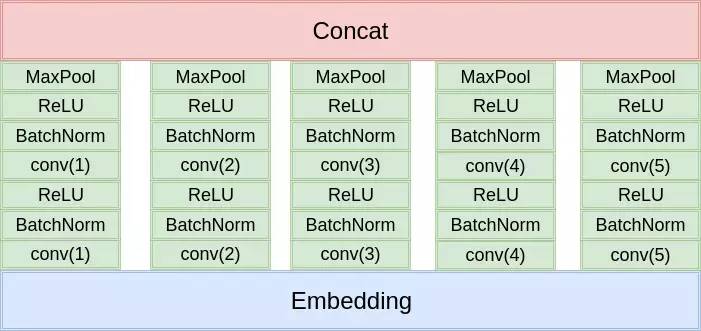
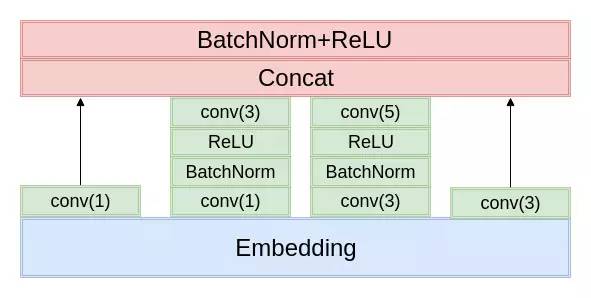
这个是我自己提出来的,参照 TextCNN 的思想(多尺度卷积核),模仿 Inception 的结构设计出来的,一层的 Inception 结构如下图所示,比赛中用了两层的 Inception 结构,最深有 4 层卷积,比 TextCNN 更深。
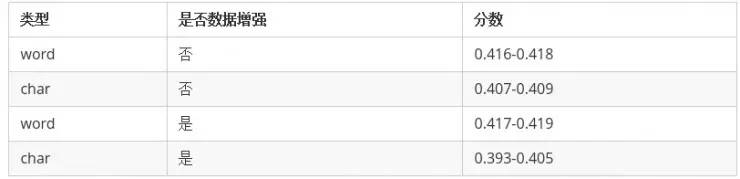
训练的时候,每个模型要么只训练基于词(word)的模型,要么只训练基于字(char)的模型。各个模型的分数都差不多,这里不再单独列出来了,只区分训练的模型的类型和数据增强与否。
可以看出来
基于词的模型效果远远好于基于字的(说明中文分词很有必要)。
数据增强对基于词(word)的模型有一定的提升,但是对于基于字(char)的模型主要是起到副作用。
各个模型之间的分数差距不大。
像这种模型比较简单,数据量相对比较小的比赛,模型融合是比赛获胜的关键。
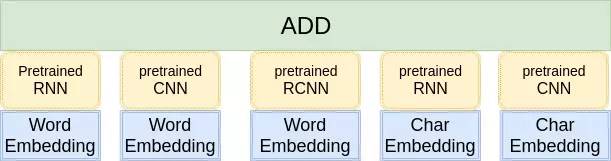
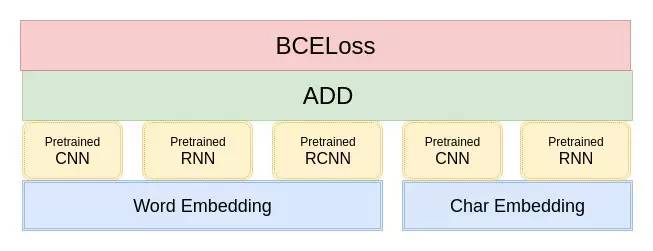
在这里,我只使用到了最简单的模型融合方法 ----- 概率等权重融合。对于每个样本,单模型会给出一个 1999 维的向量,代表着这个模型属于 1999 个话题的概率。融合的方式就是把每一个模型输出的向量直接相加,然后选择概率最大的 5 个话题提交。结构如图所示:
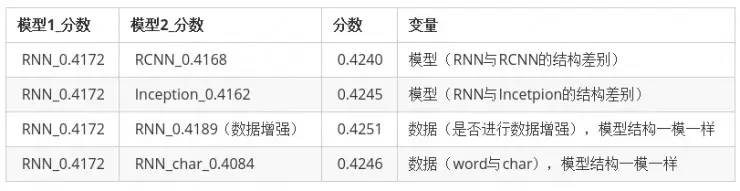
下面我们再来看看两个模型融合的分数:
第一列的对比模型采用的是 RNN(不采用数据增强,使用 word 作为训练数据),第二列是四个不同的模型(不同的结构,或者是不同的数据)。
我们可以得出以下几个结论:
从第一行和第二行的对比之中我们可以看出,模型差异越大提升越多(RNN 和 RCNN 比较相似,因为他们底层都采用了双向 LSTM 提取特征),虽然 RCNN 的分数比 Inception 要高,Inception 对模型融合的提升更大。
从第一行和第四行的对比之中我们可以看出,数据的差异越大,融合的提升越多,虽然基于字(char)训练的模型分数比较低,但是和基于词训练的模型进行融合,还是能有极大的提升。
采用数据增强,有助于提升数据的差异性,对模型融合的提升帮助也很大。
总结: 差异性越大,模型融合效果越好。没有差异性,创造条件也要制造差异性。
其实模型融合的方式,我们换一种角度考虑,其实就是一个很大的模型,每一个分支就像多通道的 TextCNN 一样。那么我们能不能训练一个超级大的模型?答案是可以的,但是效果往往很差。因为模型过于复杂,太难以训练。这里我尝试了两种改进的方法。
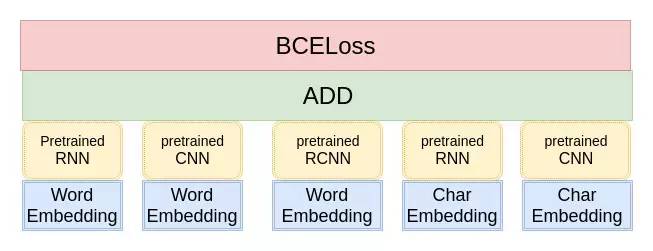
第一种方法,利用预训练好的单模型初始化复杂模型的某一部分参数,模型架构如图所示:
但是这种做法会带来一个问题: 模型过拟合很严重,难以学习到新的东西。因为单模型在训练集上的分数都接近 0.5,已经逼近理论上的极限分数,这时候很难接着学习到新的内容。这里采取的应对策略是采用较高的初始学习率,强行把模型从过拟合点拉出来,使得模型在训练集上的分数迅速降低到 0.4 左右,然后再降低学习率,缓慢学习,提升模型的分数。
第二种做法是修改预训练模型的 embedding 矩阵为官方给的 embedding 权重。这样共享 embedding 的做法,能够一定程度上抑制模型过拟合,减少参数量。虽然 CNN/RNN 等模型的参数过拟合,但是由于相对应的 embedding 没有过拟合,所以模型一开始分数就会下降许多,然后再缓慢提升。这种做法更优。在最后提交模型复现成绩的时候,我只提交了七个这种模型,里面包含着不同子模型的组合,一般包含 3-4 个子模型。这种方式生成的权重文件也比较小(600M-700M 左右),上传到网盘相对来说更方便。
MultiMode 只是我诸多尝试的方法中比较成功的一个,其它方法大多以失败告终(或者效果不明显)
数据多折训练:因为过拟合严重,想着先拿一半数据训,允许它充分过拟合,然后再拿另外一半数据训。效果不如之前的模型。
Attention Stack,参考了这篇文章,其实本质上相当于调权重,但是效果有限,还麻烦,所以最后直接用等权重融合(权重全设为 1)。
Stack,太费时费力,浪费了不少时间,也有可能是实现有误,提升有限,没有继续研究下去。
Boost,和第二名 Koala 的方法很像,先训一个模型,然后再训第二个模型和第一个模型的输出相加,但是固定第一个模型的参数。相当于不停的修正上一个模型误判的 (可以尝试计算一下梯度,你会发现第一个模型已经判对的样本,即使第二个模型判别错了,第二个模型的梯度也不会很大,即第二个模型不会花费太多时间学习这个样本)。但是效果不好,原因:过拟合很严重,第一个模型在训练集上的分数直接就逼近 0.5,导致第二个模型什么都没学到。Koala 队伍最终就是凭借着这个 Boost 模型拿到了第二名,我过早放弃,没能在这个方法上有所突破十分遗憾。
TTA(测试时数据增强),相当于在测试的时候人为的制造差异性,对单模型的效果一般,对融合几乎没有帮助。
Hyperopt 进行超参数查询,主要用来查询模型融合的权重,效果一般,最后就也没有使用了,就手动稍微调了一下。
label 设权重,对于正样本给予更高的权重,训练模型,然后和正常权重的模型进行融合,在单模型上能够提升 2-3 个千分点(十分巨大),但是在最后的模型融合是效果很有限(0.0002),而且需要调整权重比较麻烦,遂舍弃。
我之前虽然学过 CS224D 的课程,也做了前两次的作业,但是除此之外几乎从来没写过自然语言处理相关的代码,能拿第一离不开队友的支持,和同学们不断的激励。
这次比赛入门对我帮助最大的两篇文章是用深度学习(CNN RNN Attention)解决大规模文本分类问题 ( https://zhuanlan.zhihu.com/p/25928551) 和 deep-learning-nlp-best-practices ( http://t.cn/RpvjG9K)
第一篇是北邮某学长(但我并不认识~)写的,介绍了许多文本分类的模型(CNN/RNN/RCNN),对我入门帮助很大。
第二篇是国外某博士写的,当时我已经把分数刷到前三,在家看到了这篇文章,叹为观止,解释了我很多的疑惑,提到的很多经验总结和我的情况也确实相符。
P.S. 为什么队伍名叫 init? 因为 git init,linux init,python __init__ 。我最喜欢的三个工具。而且 pidof init is 1.
P.S. 欢迎报考北邮模式识别实验室( http://t.cn/RpvjaKo)
最后的最后:人生苦短,快用 PyTorch!
\下面是广告时间,不看我也不怪你/
\反正发财了也没有我的份/
新人福利
关注 AI 研习社(okweiwu),回复 1 领取
【超过 1000G 神经网络 / AI / 大数据,教程,论文】
后台回复 “我要进群” 加入 AI 技术讨论群
可能是最好玩的深度学习模型:CycleGAN 的原理与实验详解
▼▼▼



