如何优雅的使用和理解线程池
(给ImportNew加星标,提高Java技能)
转自:crossoverJie
前言
平时接触过多线程开发的童鞋应该都或多或少了解过线程池,之前发布的《阿里巴巴 Java 手册》里也有一条:

可见线程池的重要性。
简单来说使用线程池有以下几个目的:
线程是稀缺资源,不能频繁的创建。
解耦作用;线程的创建于执行完全分开,方便维护。
应当将其放入一个池子中,可以给其他任务进行复用。
线程池原理
谈到线程池就会想到池化技术,其中最核心的思想就是把宝贵的资源放到一个池子中;每次使用都从里面获取,用完之后又放回池子供其他人使用,有点吃大锅饭的意思。
那在 Java 中又是如何实现的呢?
在 JDK 1.5 之后推出了相关的 api,常见的创建线程池方式有以下几种:
Executors.newCachedThreadPool():无限线程池。
Executors.newFixedThreadPool(nThreads):创建固定大小的线程池。
Executors.newSingleThreadExecutor():创建单个线程的线程池。
其实看这三种方式创建的源码就会发现:
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>());
}实际上还是利用 ThreadPoolExecutor 类实现的。
所以我们重点来看下 ThreadPoolExecutor 是怎么玩的。
首先是创建线程的 api:
ThreadPoolExecutor(int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit, BlockingQueue<Runnable> workQueue, RejectedExecutionHandler handler)这几个核心参数的作用:
corePoolSize 为线程池的基本大小。
maximumPoolSize 为线程池最大线程大小。
keepAliveTime 和 unit 则是线程空闲后的存活时间。
workQueue 用于存放任务的阻塞队列。
handler 当队列和最大线程池都满了之后的饱和策略。
了解了这几个参数再来看看实际的运用。
通常我们都是使用:
threadPool.execute(new Job());这样的方式来提交一个任务到线程池中,所以核心的逻辑就是 execute() 函数了。
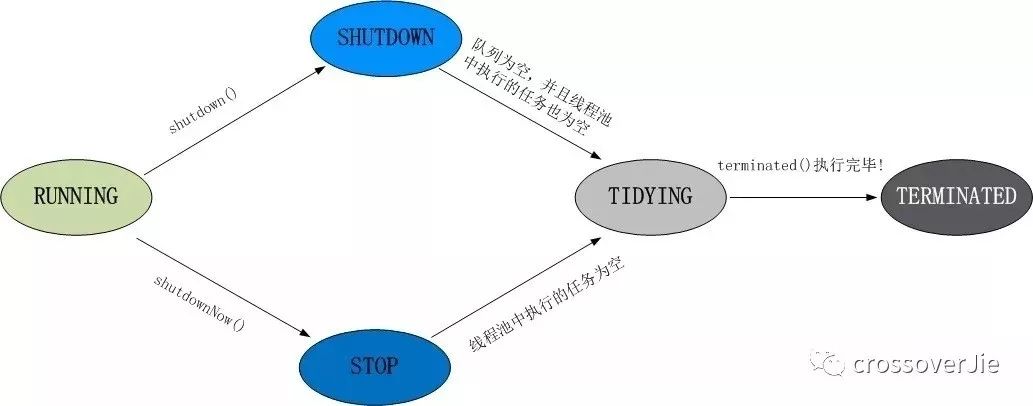
在具体分析之前先了解下线程池中所定义的状态,这些状态都和线程的执行密切相关:

RUNNING 自然是运行状态,指可以接受任务执行队列里的任务
SHUTDOWN 指调用了 shutdown() 方法,不再接受新任务了,但是队列里的任务得执行完毕。
STOP 指调用了 shutdownNow() 方法,不再接受新任务,同时抛弃阻塞队列里的所有任务并中断所有正在执行任务。
TIDYING 所有任务都执行完毕,在调用 shutdown()/shutdownNow() 中都会尝试更新为这个状态。
TERMINATED 终止状态,当执行 terminated() 后会更新为这个状态。
用图表示为:
然后看看 execute() 方法是如何处理的:
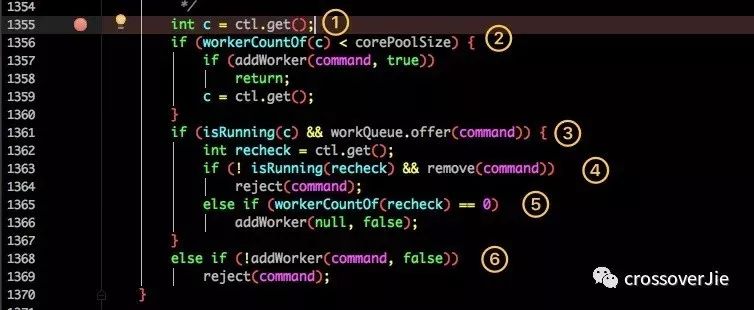
获取当前线程池的状态。
当前线程数量小于 coreSize 时创建一个新的线程运行。
如果当前线程处于运行状态,并且写入阻塞队列成功。
双重检查,再次获取线程状态;如果线程状态变了(非运行状态)就需要从阻塞队列移除任务,并尝试判断线程是否全部执行完毕。同时执行拒绝策略。
如果当前线程池为空就新创建一个线程并执行。
如果在第三步的判断为非运行状态,尝试新建线程,如果失败则执行拒绝策略。
这里借助《聊聊并发》的一张图来描述这个流程:
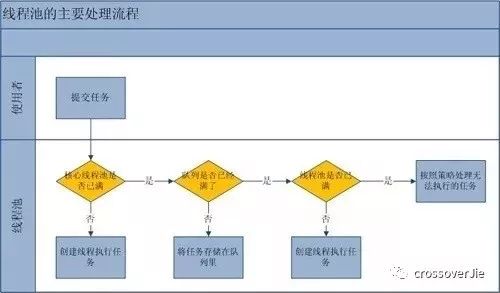
如何配置线程
流程聊完了再来看看上文提到了几个核心参数应该如何配置呢?
有一点是肯定的,线程池肯定是不是越大越好。
通常我们是需要根据这批任务执行的性质来确定的。
IO 密集型任务:由于线程并不是一直在运行,所以可以尽可能的多配置线程,比如 CPU 个数 * 2
CPU 密集型任务(大量复杂的运算)应当分配较少的线程,比如 CPU 个数相当的大小。
当然这些都是经验值,最好的方式还是根据实际情况测试得出最佳配置。
优雅的关闭线程池
有运行任务自然也有关闭任务,从上文提到的 5 个状态就能看出如何来关闭线程池。
其实无非就是两个方法 shutdown()/shutdownNow()。
但他们有着重要的区别:
shutdown() 执行后停止接受新任务,会把队列的任务执行完毕。
shutdownNow() 也是停止接受新任务,但会中断所有的任务,将线程池状态变为 stop。
两个方法都会中断线程,用户可自行判断是否需要响应中断。
shutdownNow() 要更简单粗暴,可以根据实际场景选择不同的方法。
我通常是按照以下方式关闭线程池的:
long start = System.currentTimeMillis();
for (int i = 0; i <= 5; i++) {
pool.execute(new Job());
}
pool.shutdown();
while (!pool.awaitTermination(1, TimeUnit.SECONDS)) {
LOGGER.info("线程还在执行。。。");
}
long end = System.currentTimeMillis();
LOGGER.info("一共处理了【{}】", (end - start));pool.awaitTermination(1, TimeUnit.SECONDS) 会每隔一秒钟检查一次是否执行完毕(状态为 TERMINATED),当从 while 循环退出时就表明线程池已经完全终止了。
SpringBoot 使用线程池
2018 年了,SpringBoot 盛行;来看看在 SpringBoot 中应当怎么配置和使用线程池。
既然用了 SpringBoot ,那自然得发挥 Spring 的特性,所以需要 Spring 来帮我们管理线程池:
@Configuration
public class TreadPoolConfig {
/**
* 消费队列线程
* @return
*/
@Bean(value = "consumerQueueThreadPool")
public ExecutorService buildConsumerQueueThreadPool(){
ThreadFactory namedThreadFactory = new ThreadFactoryBuilder()
.setNameFormat("consumer-queue-thread-%d").build();
ExecutorService pool = new ThreadPoolExecutor(5, 5, 0L, TimeUnit.MILLISECONDS,
new ArrayBlockingQueue<Runnable>(5),namedThreadFactory,new ThreadPoolExecutor.AbortPolicy());
return pool ;
}
}使用时:
@Resource(name = "consumerQueueThreadPool")
private ExecutorService consumerQueueThreadPool;
@Override
public void execute() {
//消费队列
for (int i = 0; i < 5; i++) {
consumerQueueThreadPool.execute(new ConsumerQueueThread());
}
}其实也挺简单,就是创建了一个线程池的 bean,在使用时直接从 Spring 中取出即可。
监控线程池
谈到了 SpringBoot,也可利用它 actuator 组件来做线程池的监控。
线程怎么说都是稀缺资源,对线程池的监控可以知道自己任务执行的状况、效率等。
关于 actuator 就不再细说了,感兴趣的可以看看这篇,有详细整理过如何暴露监控端点。
其实 ThreadPool 本身已经提供了不少 api 可以获取线程状态:
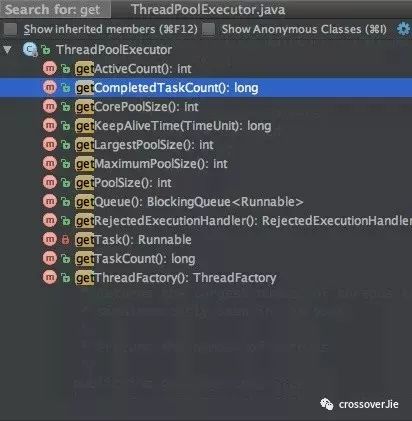
很多方法看名字就知道其含义,只需要将这些信息暴露到 SpringBoot 的监控端点中,我们就可以在可视化页面查看当前的线程池状态了。
甚至我们可以继承线程池扩展其中的几个函数来自定义监控逻辑:
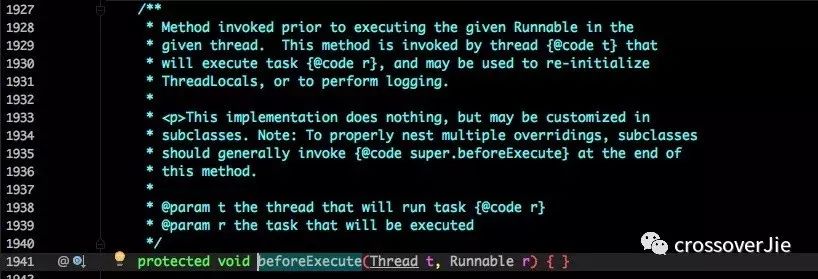
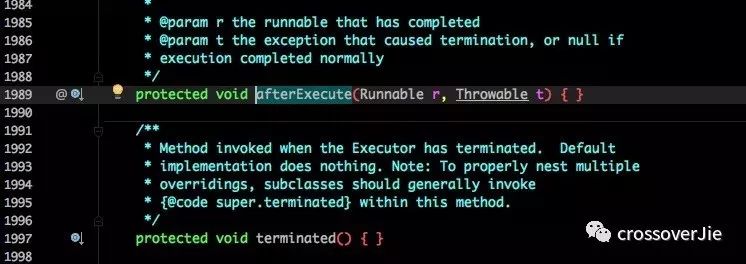
看这些名称和定义都知道,这是让子类来实现的。
可以在线程执行前、后、终止状态执行自定义逻辑。
线程池隔离
线程池看似很美好,但也会带来一些问题。
如果我们很多业务都依赖于同一个线程池,当其中一个业务因为各种不可控的原因消耗了所有的线程,导致线程池全部占满。
这样其他的业务也就不能正常运转了,这对系统的打击是巨大的。
比如我们 Tomcat 接受请求的线程池,假设其中一些响应特别慢,线程资源得不到回收释放;线程池慢慢被占满,最坏的情况就是整个应用都不能提供服务。
所以我们需要将线程池进行隔离。
通常的做法是按照业务进行划分:
比如下单的任务用一个线程池,获取数据的任务用另一个线程池。这样即使其中一个出现问题把线程池耗尽,那也不会影响其他的任务运行。
hystrix 隔离
这样的需求 Hystrix 已经帮我们实现了。
Hystrix 是一款开源的容错插件,具有依赖隔离、系统容错降级等功能。
下面来看看 Hystrix 简单的应用:
首先需要定义两个线程池,分别用于执行订单、处理用户。
/**
* Function:订单服务
*
* @author crossoverJie
* Date: 2018/7/28 16:43
* @since JDK 1.8
*/
public class CommandOrder extends HystrixCommand<String> {
private final static Logger LOGGER = LoggerFactory.getLogger(CommandOrder.class);
private String orderName;
public CommandOrder(String orderName) {
super(Setter.withGroupKey(
//服务分组
HystrixCommandGroupKey.Factory.asKey("OrderGroup"))
//线程分组
.andThreadPoolKey(HystrixThreadPoolKey.Factory.asKey("OrderPool"))
//线程池配置
.andThreadPoolPropertiesDefaults(HystrixThreadPoolProperties.Setter()
.withCoreSize(10)
.withKeepAliveTimeMinutes(5)
.withMaxQueueSize(10)
.withQueueSizeRejectionThreshold(10000))
.andCommandPropertiesDefaults(
HystrixCommandProperties.Setter()
.withExecutionIsolationStrategy(HystrixCommandProperties.ExecutionIsolationStrategy.THREAD))
)
;
this.orderName = orderName;
}
@Override
public String run() throws Exception {
LOGGER.info("orderName=[{}]", orderName);
TimeUnit.MILLISECONDS.sleep(100);
return "OrderName=" + orderName;
}
}
/**
* Function:用户服务
*
* @author crossoverJie
* Date: 2018/7/28 16:43
* @since JDK 1.8
*/
public class CommandUser extends HystrixCommand<String> {
private final static Logger LOGGER = LoggerFactory.getLogger(CommandUser.class);
private String userName;
public CommandUser(String userName) {
super(Setter.withGroupKey(
//服务分组
HystrixCommandGroupKey.Factory.asKey("UserGroup"))
//线程分组
.andThreadPoolKey(HystrixThreadPoolKey.Factory.asKey("UserPool"))
//线程池配置
.andThreadPoolPropertiesDefaults(HystrixThreadPoolProperties.Setter()
.withCoreSize(10)
.withKeepAliveTimeMinutes(5)
.withMaxQueueSize(10)
.withQueueSizeRejectionThreshold(10000))
//线程池隔离
.andCommandPropertiesDefaults(
HystrixCommandProperties.Setter()
.withExecutionIsolationStrategy(HystrixCommandProperties.ExecutionIsolationStrategy.THREAD))
)
;
this.userName = userName;
}
@Override
public String run() throws Exception {
LOGGER.info("userName=[{}]", userName);
TimeUnit.MILLISECONDS.sleep(100);
return "userName=" + userName;
}
}api 特别简洁易懂,具体详情请查看官方文档。
然后模拟运行:
public static void main(String[] args) throws Exception {
CommandOrder commandPhone = new CommandOrder("手机");
CommandOrder command = new CommandOrder("电视");
//阻塞方式执行
String execute = commandPhone.execute();
LOGGER.info("execute=[{}]", execute);
//异步非阻塞方式
Future<String> queue = command.queue();
String value = queue.get(200, TimeUnit.MILLISECONDS);
LOGGER.info("value=[{}]", value);
CommandUser commandUser = new CommandUser("张三");
String name = commandUser.execute();
LOGGER.info("name=[{}]", name);
}运行结果:

可以看到两个任务分成了两个线程池运行,他们之间互不干扰。
获取任务任务结果支持同步阻塞和异步非阻塞方式,可自行选择。
它的实现原理其实容易猜到:
利用一个 Map 来存放不同业务对应的线程池。
通过刚才的构造函数也能证明:
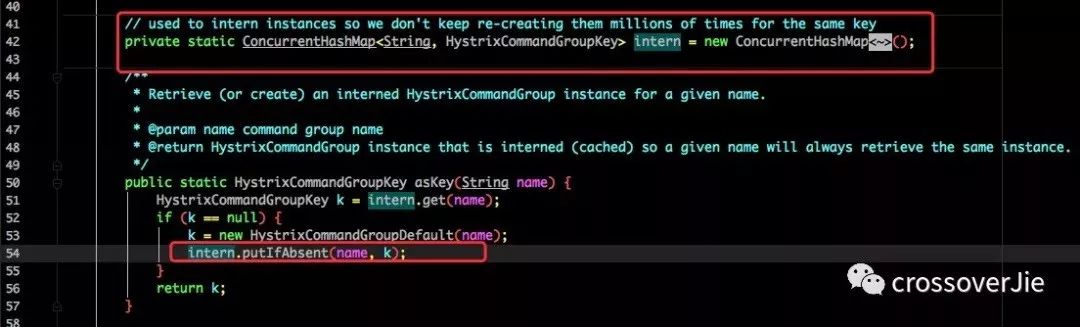
还要注意的一点是:
自定义的 Command 并不是一个单例,每次执行需要 new 一个实例,不然会报 This instance can only be executed once. Please instantiate a new instance. 异常。
总结
池化技术确实在平时应用广泛,熟练掌握能提高不少效率。
文末的 hystrix 源码:
https://github.com/crossoverJie/Java-Interview/tree/master/src/main/java/com/crossoverjie/hystrix
推荐阅读
(点击标题可跳转阅读)
看完本文有收获?请转发分享给更多人
关注「ImportNew」,提升Java技能

好文章,我在看❤️