【VALSE 前沿技术选介17-08期】捡了芝麻,也要西瓜——深度学习中如何避免灾难性遗忘?
今天给大家介绍主题叫做Catastrophic Forgetting。虽然这个名字很吓人,但其实早在神经网络的远古时代,就已经有研究[1]关注这样的一个问题了。在自然认知的系统中,遗忘是一个逐步的过程,除极少数情况,人不会突然失忆。但是在对应的计算模型,尤其是Gradient Based Connectionism(联结主义)模型中,模型往往表现的是Catastrophic Forgetting(毁灭性遗忘),即学习了新的知识之后,几乎彻底遗忘掉之前训练的内容。这样一个问题简言之,关注的是在Sequential Learning过程中,在每个stage的学习中,算法都会使用不同的数据或任务,学习了新的任务或数据会使旧的任务性能大幅下降的问题。更具体来说,例如在分类任务中,我们首先使用一些预定的类别的样本训练一个模型,之后再使用一些新类别的样本来finetune这样一个网络,这会使网络识别初始类别的性能大幅度下降;再比如,在增强学习任务中,单独训练后续的任务,会使agent在前序任务的性能下降严重。
在Deep Learning时代,这样一个问题又重新回到了人们的眼中。在这个context下一个早期的empirical analysis来自[2],[2]指出使用dropout可以有效降低Catastrophic Forgetting的现象。作者从model capacity的角度给出了一个解释。个人觉得从distributed representation角度解释可能更合理一些,因为使用dropout之后信息会更平均分配在不同的neuron之中,不会出现在finetune时某一个特定的neuron被更改,而使整个model性能急剧下降的问题出现。
在这之后一个比较重要的工作来自于”Learning without Forgetting” (LwF) [3],这篇文章仍然从最简单的分类任务入手,巧妙运用了Knowledge Distill技术来缓解这样的问题。具体地,[3]使用旧模型作为teacher model,对于新任务中的每一个样本。和传统的Finetune比起来,LwF使用了teacher model输出的soften softmax对新任务中的样本进行约束。这里即使新任务与旧任务的类别定义不尽相同,但是这样的信息仍然可以利用新样本帮助维持旧任务中对样本的embedding结构,从而改善旧任务的性能;和固定网络权值抽取特征,再训练新任务的分类器比起来,显然使feature extractor适应新任务,会使新任务性能大幅提高;最后和Joint Training,即将新任务和旧任务一起训练比起来,LwF不需要存储旧任务的样本。Joint Training的性能可以任务是此类方法性能的上限。下图直观比较了几种将CNN adapt到新任务上的方法:
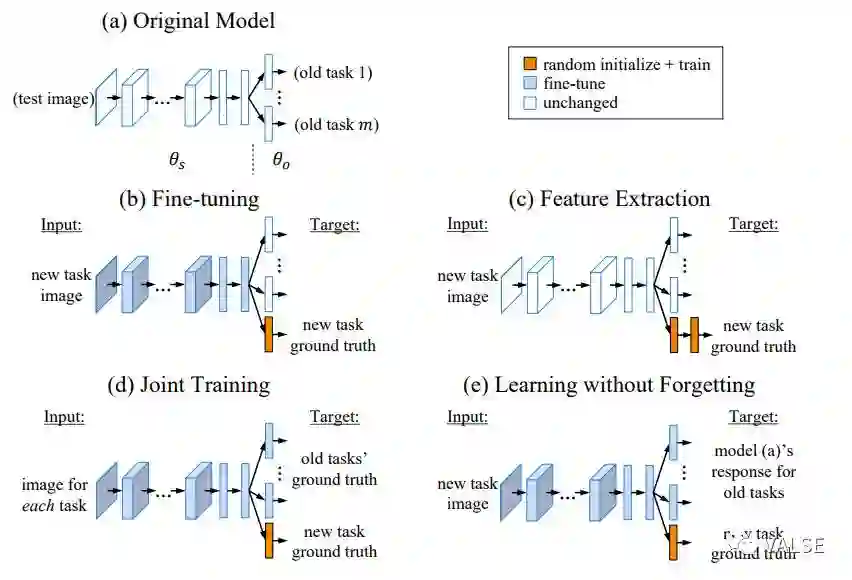
至于性能,在试验中,作者使用了不同的网络结构和不同的迁移任务来验证方法的可行性。这样一个思路最近也被拓展到了更复杂的任务,例如Object Detection中[4]。
另外的尝试包括[6],[6]中放宽了完全不保留旧任务样本的限制,而是采取给定一个保留样本数目的budget,选择最有代表性的样本方式。为了简化整个样本选择,作者做出了一个很强的假设:即每一类样本在latent feature space中是近似高斯分布的,这样就可以很简单地使用nearest class mean来进行分类,即对于新的测试样本,使用与其距离最近的class mean作为分类的结果。这样设定保留样本的目标也相对容易:我们只需要用少量样本去近似真实的class mean即可。具体做法上,依次贪心选出最能近似现有真实class mean的样本保留即可。至于更新CNN部分,依旧使用的是和[3]一样的方法。保留少量代表性的样本来解决Catastrophic Forgetting应该是一个很有意义的方向,但是这个方法仍然做出了太多过强的假设,应当后续有不少发展和改进的空间。
另外一条发展线路是沿着约束CNN的weight变化。一个直观的理解便是如果weight变化不大,那么旧任务的性能应该也不会下降太多。然而,如果简单任务weight的每个维度都是同等重要的,那么就完全忽略掉了loss function的形态,从而会得到一个不好的结果。一个直观的理解如下图:
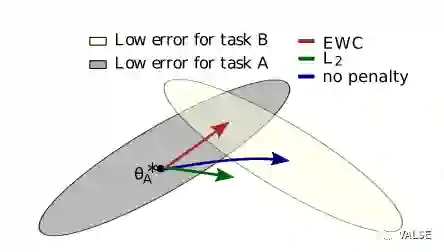
灰色和黄色分别是对应旧任务和新任务的error surface。这里为了示意,在最终收敛参数周围,使用了二次近似,在平面上,即为一个椭圆。如果我们在Finetune的时候不加入任何约束,那么最终收敛的参数自然会到新任务loss最低的地方,即蓝色箭头所指方向。但是显然,这样的结果对于旧任务是一个很差的参数。如果我们能够充分使用局部error surface的信息,使参数收敛到上图中两个椭圆重叠的部分,那必然是一个最好的结果。这也就是[4]这个工作想要达到的目的。具体做法上,作者使用了Fisher Information Matrix来近似Hessian Matrix,并为了效率考虑,只选取了对角线元素做近似,即

类似的想法在被扩展到了近期的一个工作[5]中,依然基于上面的这样一个局部高斯假设,作者希望使用一个高斯分布更好地近似旧任务和新任务组成的两个高斯混合分布。这样一个问题可以使用传统统计中常用的Moment Matching的方法Incrementally地解决。最后如果新旧任务收敛点差距太远,这样的一个高斯假设并不成立,所以作者还提出了3种方式,可以逐步地迁移weight。具体细节就不展开,有兴趣的读者可以参考原始paper。
[1] McCloskey, M., & Cohen, N. J. (1989). Catastrophic interference in connectionist networks: The sequential learning problem. Psychology of learning and motivation, 24, 109-165.
[2] Goodfellow, I. J., Mirza, M., Xiao, D., Courville, A., & Bengio, Y. (2013). An empirical investigation of catastrophic forgetting in gradient-based neural networks. arXiv preprint arXiv:1312.6211.
[3] Li, Z., & Hoiem, D. (2016). Learning without forgetting. In ECCV2016
[4] Kirkpatrick, J., Pascanu, R., Rabinowitz, N., Veness, J., Desjardins, G., Rusu, A. A., ... & Hassabis, D. (2017). Overcoming catastrophic forgetting in neural networks. Proceedings of the National Academy of Sciences, 201611835.
[5] Lee, S. W., Kim, J. H., Ha, J. W., & Zhang, B. T. (2017). Overcoming Catastrophic Forgetting by Incremental Moment Matching. In NIPS2017
[6] Rebuffi, S. A., Kolesnikov, A., & Lampert, C. H. (2016). iCaRL: Incremental classifier and representation learning. In CVPR2017.



