重温五条 AI 基础规律
▲点击上方 雷锋网 关注

文 | 刘肉酱 编辑 | 杨晓凡
来自雷锋网(leiphone-sz)的报道
雷锋网 AI 科技评论按:如果每个人都有足够的时间和热诚,并乐意去大学拿个 AI 学位,那你大概就不会读到这篇博客了。 虽说 AI 的工作方式挺神秘的,但在处理技术问题的时候,以下这五个 AI 原则应该可以帮你规避一些错误。它们对于当代的基于统计学习的机器学习(Machine Learning)系统,尤其是深度学习(Deep Learning)系统尤其适用。
这篇来自 eloquent.ai 博客的文章所说的,总结起来就是这 5 条 AI 原则:
利用未曾见过的数据评估AI系统
更多数据可以带来更好的模型
有效数据的价值远远超过无效数据
从一个简单的基线开始
人工智能并不是魔法
给大家一个小小的忠告——通过对机器学习的基本理解,这篇文章将更有意义。 之前的另一篇文章(https://blog.eloquent.ai/2018/08/30/machine-learning-for-executives/)对这些基础知识有所解释。当然了,不是说这篇文章你非读不可,但是读了的话肯定会对你后面的理解更有帮助!
1. 利用未曾见过的数据评估AI系统
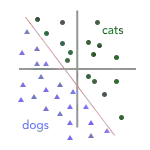
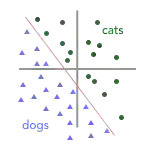
在上一篇文章中,我们介绍了如何构建分类器以将图像标记为猫(绿色圆圈)或狗(蓝色三角形)。在将我们的训练数据转换为向量之后,我们得到了下面的图表,其中红线表示我们的“决策边界”(即将训练数据转换为向量后,这条“边界线”就将图像划分为猫和狗)。
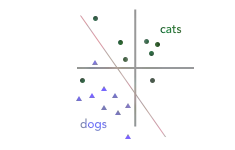
显然,图中的决策边界错误地将一只猫(绿色圆形)标记标记成了狗(蓝色三角形),即遗漏了一个训练个样本。那么,是什么让训练算法没有选择下图中的红线作为决策边界呢?
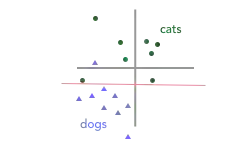
在这两种情况下,我们对训练集进行分类都得到了同样的准确率——两中决策边界都标错了一个例子。但是如图示,当我们在数据中加上一只未出现过的猫时,只有左图的决策边界会正确地预测这个点为猫:
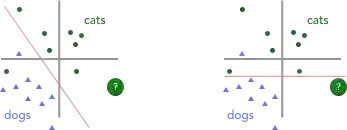
分类器可以在用来训练它的数据集上工作得很顺利,但它未必适用于训练的时候没有见过的数据。此外,即使分类器在特定类型的输入(例如,室内场景中的猫)上工作良好,它对于相同任务的不同数据(例如,室外场景中的猫)也可能无法很好地工作。
盲目地购买 AI 系统而不对相关的未知信息进行测试,可能会付出很大的代价。一种测试未知数据的实用方法是——先保留一部分数据不提供给开发人工智能系统的企业或个人,然后自己通过生成的系统运行这些保留数据。最不济,也得保证你能自己试用才行。
2. 更多数据可以带来更好的模型
如果给你下面的训练数据集,你会把决策边界画在哪里?

你想的可能没错——许多决策边界可以准确地分割这些数据。 虽然下面的每个假设决策边界都正确地分割了数据,但它们彼此之间的差别很大,正如我们上面所看到的,其中一些可能会在目前尚未见到的数据(也就是你真正关心的数据)上更糟糕:
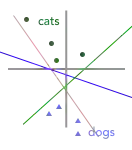
从这个小数据集中,我们不知道这些彼此不同的决策边界中,究竟哪一个最准确地代表了现实世界。缺乏数据会导致不确定性,因此我们得收集更多数据点,并将其添加到初始图表中,则可得到下图:

额外的数据能帮助我们大幅缩小选择范围,立即画出绿色和蓝色间的决策边界,因此决策边界会是如下所示:
当机器学习模型表现异常时,潜在的问题通常是模型没有经过足够或正确的数据训练。尽管更多的数据几乎总是有帮助,但需要注意,数据越多可能得到的回报却在减少。当我们将第一个图的数据加倍时,准确度明显增加。但是基于该图表,如果将数据再加倍,则精度的提高不会有之前那么大。准确度随着训练数据的数量大致呈对数增长,因此从 1k 到 10k 个样本可能比从 10k 到 20k 个对准确性产生更大的影响。
对于我个人来说,这一条特别忌讳,尤其是对于预算紧张的创业公司:你们经常给ML工程师支付数高额薪水,但也请确保提供足够的预算和时间来让他们仔细收集数据。
3. 有效数据的价值远远超过无效数据
在上面的例子中,虽说有更多的数据会对训练有所帮助,但前提是它们足够准确才行。还是前面的例子,在收集了附加数据之后,可以得到一个这样的图形和一个决策边界,如下所示:
但是,如果这些新数据点中的一些其实是被错误标记了,而真是情况是下面这样的呢?

我们要注意,虽然这些标记错误的点与第一个图中的点坐标相同,但它们代表的意义已经改变。这导致了一个完全不同的决策边界:

即使只有四分之一的数据集被错误标记,但很明显,错误的数据会对我们的模型构建有重大影响。我们可以在训练期间使用一些技术来减少标记数据时的错误,但这些技术作用有限。在大多数情况下,清理基础数据更加容易和可靠。
这里的要点是“有效数据”至关重要,有效数据意味着数据准确标记,意味着数据合理涵盖了我们想关注的范围,也意味着训练集中同时存在简单案例和困难案例等等。因而决策边界没有那么多的摆动空间,只有一个“正确”的答案。
4. 从一个简单的基线开始
这并不是说你应该尝试了一点简单的东西就觉得满意然后停下来。即便你最终的方法既现代又复杂,通过这条原则,你也会开发得更快,并且最终的结果也会更好。
我可以举一个关于我自己的真实例子,当我读研一时,我们实验室的同学兼 Eloquent 的研究员 Angel 和我参与了一个项目,我们各自将语言里描述时间的词转化成可供机器阅读的格式。本质上来说,就是试图让计算机理解诸如“上周五”或“明天中午”之类的短语。
由于这些项目是申基金所必需的,Angel 致力于一个实用性强,有确定性的规则系统。她为了让这个系统能实用起来而绞尽脑汁。而我当时只是一个在实验室轮岗的学生,团队让我自主选择任何花哨的方法,就像糖果店里的孩子一样。我探索了最时髦、最动人的语义解析方法。在我的项目中,我运用了 EM、共轭先验、一个完整的自定义语义解析器等等新奇的方法。
差不多十年之后,我很高兴还留下了一篇受到好评并且引用数还行的论文。然而,Angel 的项目 SUTime 呢,现在是斯坦福流行的 CoreNLP 工具包中最常用的组件之一——简单的方法击败了时髦的方法。
你可能以为我已经吸取了教训,然而几年之后,当我成为一名高年级研究生时,我要让另一个系统启动并用于另一个基金项目。我再一次试图训练一个花哨的机器学习模型,但几乎没有做出什么成果。有一天我觉得无比失败和沮丧,以至于我甚至开始写“模式”。“模式”就是一些简单的确定性规则。比如,当一个句子包含“出生于”这个词时,则假设这是一个出生地。模式不会学习,作用有限,但它们易于编写且用起来合理。
最后,基于模式的系统不仅胜过我们原来的系统,它后来还被加到了 NIST 排名前 5 的系统中,并深深影响了那些基于机器学习的模型高性能系统。
结论就是:先做简单的事。当然了,我们还有其他更好的理由:
1.它会给你的最终模型的性能提供一个安全的最低值。当你做出一个简单的基准模型之后,你会希望任何聪明的东西都会击败它。几乎不会有什么模型会比一个基于规则的模型表现还要差。这给你的更高级的方法提供了一个比较,如果你的高级方法的表现更差,那意味着你有什么东西彻底做错了,并不是任务太过艰巨。
2.通常,简单的方法需要较少的(或不用!)训练数据,这就使你可以在没有大量数据投资的情况下进行原型设计。
3.它经常会揭示出手头任务的难度,这通常会向你指明如何选择更好的机器学习方法来处理这些困难的部分。此外,它还能向你指明如何给需要更多数据的方法收集数据。
4.简单的方法一般只需要很少的额外努力就可以泛化到未见过的数据上。(记住:总是用模型没有见过的数据来评估模型!)更简单的模型往往更容易解释,这使得它们更具可预测性,因此让它们向没有见过的数据上泛化的过程也更明了。
5.人工智能并不是魔法
这句话是我经常挂在嘴边的。大家虽然表面上都表示赞同,但心里未必真的服气,因为人工智能看起来就像魔术一样。在谈到 Eloquent 人工智能的宏伟未来计划时,我对曾经反复强调这个错误观念感到内疚。我从训练机器学习模型的细节中得到的越多,模型看起来就越看起来不像是曲线的拟合,它们看起来更像一个黑匣子,我可以付出一些代价来进行操控。
人们很容易忘记,现代机器学习领域还很年轻——只有二三十岁。与现代机器学习工具包的成熟度和复杂性相比,整个领域仍然相当不成熟。它的快速进步使人们很容易忘记这一点。
机器学习的一部分邪恶之处在于它具有内在的概率性。它在技术上无所不能,但不一定达到你想要的准确度。我怀疑在许多机构中,在组织结构图上添加新东西时,“准确度”的细微差别被漏下,只留下“人工智能可以做任何事情”的叙述部分。
你如何将不可能与可能分开?我尝试遵循一些最佳做法:
与实际训练模型的人交谈。不是团队领导,不是部门主管,而是让模型训练代码运行起来的人。他们通常可以更好地了解模型的工作原理及其限制。确保他们愿意随时告诉你,你的模型有限制并且在某些方面表现不佳。我敢保证,无论他们是否告诉你,你的模型总会有一些不行的方面。
至少对于 NLP 项目,你通常可以使用一个快速又繁杂的基于规则的系统来检查任务的可行性。机器学习是一种很好的方式,可以用来生成一个非常大且模糊的、很难用人工的方法写下来的规则集。但如果一开始你就很难写下一套合理的规则来完成你的任务,那这通常是一个不好的迹象。然后,收集一个小数据集并尝试使用你学习到的系统。接下来是一个稍微大一点的数据集,并且在你获得表现提升时继续这样做。一个重要的经验法则就是:准确度随着数据集大小的对数而增长。
永远不要相信高得出奇的准确性:任何超过 95 或 97% 的数值。同样地,不要相信任何高于人类输出平的准确性,或者高于一致性评价。很大概率上,要么是数据集有缺失,有么是评估不完善。两者都经常发生,即使是对于经验丰富的研究人员
你在网上看到的所有和机器学习有关的内容(新闻,博客,论文),如果没有其它作证那它们都是有歧义或错误的——包括现在这篇。
和往常一样,如果你有任何问题、意见或反馈,请发送电子邮件至 hello@eloquent.ai。填写注册表格订阅,我们将直接发送这些帖子到你的邮箱,并访问我们的主页 eloquent.ai。如果能这么做的话我就很满足了。回聊!
via blog.eloquent.ai
◆ ◆ ◆
推荐阅读
谷歌大罢工席卷全球!47个办事处规模超历史,员工公开刊登诉求
破天荒!苹果终于对 MacBook Air 大更新,还有全新 iPad Pro 和 Mac mini
6,499元买iPhone XR?10分钟告诉你值不值!
全球AI+智适应教育峰会
大会官网(免费门票开放申请):https://gair.leiphone.com/gair/aiedu2018
雷锋网联合乂学教育松鼠AI以及IEEE教育工程和自适应教育标准工作组,在嘉里中心举办全球AI+智适应教育峰会。
确认出席的嘉宾
美国三院院士、机器学习泰斗Michael Jordan、机器学习之父Tom Mitchell、SRI斯坦福国际研究院副总裁Robert Pearlstein等顶尖学者;
VIPKID、作业帮、沪江网等国内著名教育创业公司创始人;
Knewton、Byju's、DreamBox、Duolingo、ALEKS、AltSchool等国外最具影响力的AI智适应教育公司。

免费门票开放中,点击“阅读原文”立即申请!



