谁在“谋杀” Hadoop?

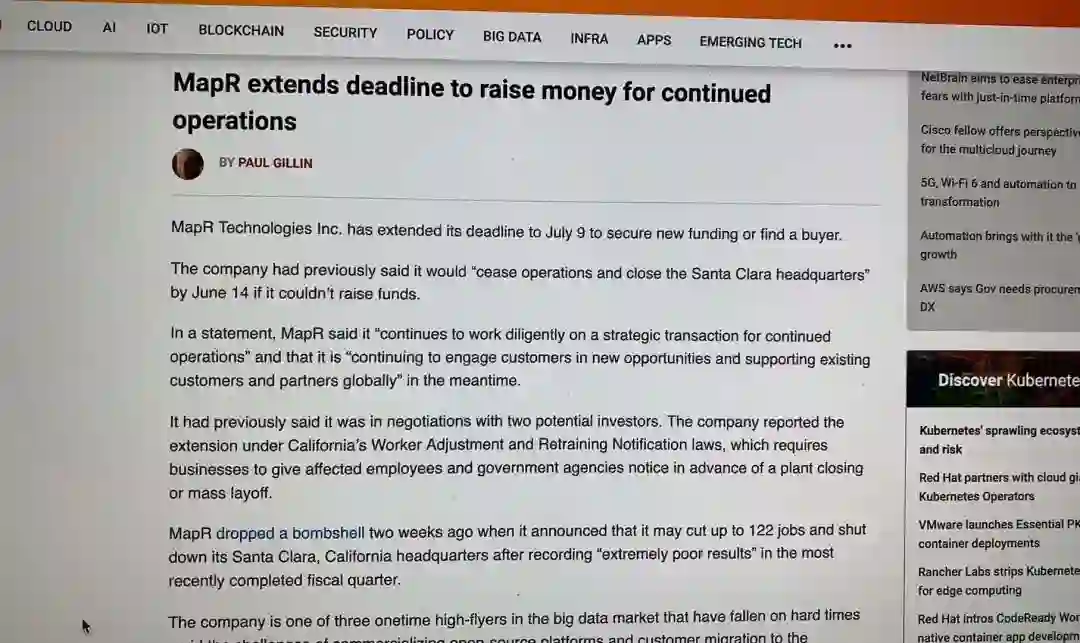
但是最近剧情反转的有点让人猝不及防,上上周,美股开盘之后,Cloudera 股价暴跌 43%,曾经 41 亿美元的估值缩水为 14 亿美元;上上上周,外媒爆料曾经估值 10 亿美元的 MapR 向加州就业发展局提交文件,称如果找不到新的投资人,公司将裁员 122 人。
更多优质内容请关注微信公众号“AI 前线”(ID:ai-front)
在 Hadoop 的发展史上,有三家公司不得不提,分别是 Cloudera、Hortonworks 和 MapR。
Cloudera 是第一家 Hadoop 商业化公司,成立于 2008 年 8 月,创始人来自 Google、FaceBook 和 Yahoo!,其首席架构师 Doug Cutting 也是 Hadoop 的第一位作者;Hortonworks 成立于 2011 年,是由 Yahoo! 的 Hadoop 团队拆分而成;MapR 成立于 2009 年,创始人 M.C.Srivas 来自于 Google。
这三家公司同属于 Hadoop 发行版提供商。所谓的“发行版”,其实是开源文化特有的,虽然在很多外行眼中,发行版只是将开源代码打包,然后在添加一些自己独创的边角料。但其实发行版真正比拼的是对海量生态系统组件的价值筛选、兼容和集成保证以及支撑服务。
同样是提供发行版,这三家公司的商业模式可以说是完全不同。Cloudera 主要是发布 Hadoop 商业版和商用工具,其核心组件 CDH 开源免费,与 Apache 社区同步;而数据治理和系统管理组件闭源,用户需要获得商业许可,除了之外,商业组件也会提供企业生产环境中必需的运维功能。
Hortonworks 的商业模式是 100% 完全开源的策略,所有产品开源,用户可免费使用。真正用来盈利的是技术服务支持。
MapR 的商业模式遵循了传统软件厂商的模式,采用私有化实现,用户通过购买软件许可来使用。
虽然三家公司的商业模式不尽相同,但是都曾从 Hadoop 中获得了红利,Cloudera 的估值在顶峰时高达 41 亿美元,而 Hortonworks 和 MapR 的估值也曾超过 10 亿美元。
不过,最近剧情急转直下,2018 年 10 月,Cloudera 和 Hortonworks 宣布合并,Cloudera 的股东将拥有新公司 60% 的股权,Hortonworks 的股东持有 40% 的股权。合并时,双方对于未来的盈利能力信心十足,“到 2020 年预计每年收入有望超过 10 亿美元。”但是,事情发展并不如预期,合并半年多后,2019 年 6 月 6 日美股开盘,Cloudera 股价暴跌 43%,曾经 41 亿美元的估值缩水为 14 亿美元。
相比于抱团取暖的 Cloudera 和 Hortonworks,MapR 的处境更为艰难了,甚至走到了“闭店裁员”的窘境,“如果再获得新的资金注入,MapR 可能会裁员 122 人,并关闭位于 Santa Clara 的总部。”据外媒报道,MapR 裁员将于 6 月 14 日生效,但是就在前几日,有消息称 MapR 将寻找新资金的最后期限延长到了 7 月 9 日。
眼看 Hadoop 三大商业公司起高楼,为何忽然之间楼斜了呢?众说纷纭,有人说是因为数据库的发展,有人说是因为云计算的崛起,还有人说是自身模式有问题?...... 为了弄清楚原因,我们采访了多位各领域的技术专家。
在一篇外媒的 分析文章 中,提出了这样一个观点:在受欢迎指数、收益等方面,大数据其他开源供应商(如 Elastic 和 MongoDB 公司)和 Hadoop 三大商业公司呈现出了此消彼长的态势,之前没有人认为 MongoDB 和 Elasticsearch 这样的技术以及它们背后的公司能够挑战 Hadoop 及相关产品,但是现在它们做到了。
事实真如这篇文章分析的那样吗?MongoDB、Elasticsearch 和 Hadoop 真的已经成为了竞争关系吗?
针对此,我们采访多位 MongoDB 和 Elasticsearch 的技术专家,大家的观点出奇的一致,那就是从目前来看,MongoDB 和 Elasticsearch 与 Hadoop 并不构成竞争关系,甚至连重合点都很少。
“MongoDB 和 Elasticsearch 与 Hadoop 在本质上是离线处理和在线处理两个完全不同的方向,”MongoDB 中文社区主席唐建法这样认为:“Hadoop 的底层存储是基于无索引的 HDFS ,核心应用场景是对海量结构化、非结构化数据的永久存储和离线分析,例如客户肖像、流失度分析、日志分析、商业智能等。而 MongoDB 和 Elasticsearch 的核心场景是实时交互,通常用于人机交互场景,例如电商移动应用,其特征是响应时间一般是毫秒级到秒级。”
当然,它们之间也不是完全没有竞争的地方,但 MongoDB 、Elasticsearch 真正竞争的是 Hadoop 内的生态组件,例如 HBase、Hive、Impala 等。以 Elasticsearch 为例,它满足了比较基础的即席查询需求、在线业务检索需求,甚至是轻量的 BI 需求,这些在功能上与 Hadoop 会有所重合。
除了竞争关系,这篇外媒评论文中还提到了一个重要观点,那就是 Hadoop 使用繁琐,用户体验糟糕,MongoDB 和 Elasticsearch 使用方便,而这也导致了 Hadoop 的“衰败”。
“Hadoop 使用繁琐”的观点得到了众多技术专家的赞同。Hadoop 的本质其实就是 HDFS 存储 +MapReduce 计算框架,但是 Hadoop 发行商为了提高自己的商业竞争力,在 Hadoop 技术上增加了各种组件。Elastic 社区首席架构师吴斌称,“假设你发现了一个符合需求的组件,那么在部署使用它之前,可能还需要部署它的存储和配置管理组件,这时就不得不把精力放在诸如 HDFS、Zookeeper 等组件之上。在真正使用服务之前,用户就在 HDFS 和 Zookeeper 上付出了不少代价,这个过程往往会让入门级选手心灰意冷,进而追求门槛更低的服务,例如 Elasticsearch 或者 MongoDB。”
即使成功迈过了入门的门槛,很多企业也会因为复杂性难以充分利用 Hadoop。MongoDB 中文社区主席唐建法曾在两间银行看到过这样的情况,他们一家使用 MapR,一家使用 Cloudera,在系统上线 2 年后的今天,只完成了一个最简单的业务场景,行内一部分业务数据的归档功能。他们提到了一个共同的问题就是,如果说写进数据湖(Hadoop) 还算可以做得到, 把数据从里面读出来使用是更加困难的!
在很多分析文章中,都把 Hadoop 近日来的“颓势”归因为公有云的发展,Hadoop 的出现代表了当时革命性的技术,而云计算代表了数据处理的新方法,解决了与 Hadoop 相同的问题。Hadoop 主要是应用了比之前廉价的存储,但是云计算的出现,让存储变得更加廉价,且用户体验也获得了成倍提升。
云计算厂商打造了完全集成的一站式云原生服务,并且在云上提供了很多组件来替代原有的 Hadoop 组件,例如 AWS 的 S3 替代了 HDFS,K8S 替代了 Yarn。而 Hadoop 因其庞然的架构,本身并不适合以弹性灵活快速扩展的公用云环境。
公有云的出现给了 Hadoop 一定的压力,但会成为 Hadoop 的致命一击吗?
综合多位技术专家的意见,答案是否定的。
本地化部署的 Hadoop 颓势确实和公有云产品有关。 吴斌认为:“云计算厂商提供的托管服务在部署和运维上给予了用户太多便利,且从计算资源角度来看,云厂商大大降低了用户的成本,尤其是竞价实例,在给终端用户节省成本的同时,也做到了资源的合理利用和自身利益的最大化。”
在采访中,唐建法还提到了另外一种情况:“支撑大部分实体经济的企业,例如制造业、金融业、政府等强监管行业,还远远没有达到把企业全量数据存放到公有云的阶段,甚至会出于数据安全的考虑,永远不放在公有云上。”也就是说,公有云也不是银弹,即使发展得更好,也不可能完全侵占 Hadoop 的应用场景。
在很多分析文章都把云公司和 Hadoop 发行版公司放在了对立的两端,事实上它们并不是天然的对手,Hadoop 发行版公司也在积极的向云端转型,甚至 Cloudera 原本的初衷就是提供云服务。Cloudera 创始人在某次访谈中提到:“Cloudera 在创建时原本打算做的服务是类似于现在 AWS 的 Elastic MapReduce 那样的云上服务。但很快发现这个模式太超前,所以转向了做 Hadoop 发行商的角色。”
云会威胁 Cloudera 吗?Cloudera 创始人 Mike Olson 在 2018 年接受采访时,是这样回答的:“如果五年后我们只是一个本地部署供应商,我们将成为一个注脚。我们的大好机会是帮助客户迁移到云,并提供云和本地部署之间的可移植性。由于我们在早期所做的赌注,我们可以让用户在不编码到专有 API 的情况下进行迁移。我们与所有的超大规模云提供商都有良好的合作关系。当然,他们在某种程度上与我们竞争,但我的机会不是击败 Redshift 。Redshift 的目的是帮助那些希望训练机器学习模型的客户在所有云提供商中提供这种能力。而我们的目标是将客户想要的所有可移植性与他们需要的法规和遵从性功能集成并提供给他们。”
“Hadoop 三大发行商的衰落是否代表了 Hadoop 的衰败?”这是很多人关心的问题,也是技术人在热情讨论的问题。首先,需要明确的是 Hadoop 三大发行商无法全权代表 Hadoop,其次,与前几年相比,Hadoop 的热度确实在下降。
与其说 Hadoop 衰败,倒不如说是 Hadoop 走下了神坛。 早些年前,Hadoop 是与大数据划等号的存在,但是现在,大家对于大数据产品的需求更丰富了,眼光也更挑剔了。最早大家只要求能够处理海量数据,后来追求高效实时,而现在大家还要求经济便宜,功能丰富。
唐建法认为 Hadoop 生态的衰败并非是指技术,而是市场炒作的一种理性回归。 因为低成本、海量扩展能力,以及对半结构化、非结构化数据的支持,Hadoop 在大数据分析、历史数据归档方面是有独特地位的。如果 Hadoop 能够专注于擅长的离线场景,并提升用户使用体验,那么基于 Hadoop 的技术方案在未来还是很有前景的。
既然 Hadoop 真正的竞争对手不是 MongoDB、Elasticsearch 等其它开源产品,也不是公有云,那么真正的对手是谁?
首先,我们不能简单的把 Hadoop 理解成一款产品,它是一种生态。所以,Hadoop 真正面临的其实是生态之争,而不是某款产品之争。
Elasticsearch 技术专家表示:“与 Elasticsearch 生态相比, Hadoop 的产品功能相对比较分散。Elastic Stack 的整合程度则非常高, 且 Elasticsearch 的分析速度更快更实时,从数据接入到前端分析展现都有完整的产品,打通了整条数据分析的链路,开箱即用,用户体验要好的多。”
而云计算厂商通常会选择更多的生态伙伴来一起合作,例如 Google 宣布将 MongoDB 纳入 Market Place 产品目录,AWS 与 MongoDB 签署全球金牌合作伙伴,腾讯云和 Elastic 达成合作。
与单个产品或环节的竞争不同,生态之间的竞争更加复杂多样,既包括了产业链上的生态,也包括了跨行业的生态,所以竞争结果不只是简单的争长竞短、你死我活,也有可能是互相融合、共同繁荣。Hadoop 生态与其它大数据生态各自有自己的使用场景和成熟的生态链,它们之间不只有竞争,更有互补的地方,从这个角度来看,Hadoop 未来的机会不是打败对手,而是做好自己。
今日荐文
点击下方图片即可阅读

如何基于Flink+TensorFlow打造实时智能异常检测平台?只看这一篇就够了
如果把骨骼比喻为架构,那血肉就是算法,在这个算法为王的时代,美团外卖、阿里广告推荐、腾讯反作弊、百度搜索等,都离不开机器学习算法的加持。一起来 7 月 12 日深圳 ArchSummit 架构师峰会上看他们的核心算法技术。扫描二维码或点击【阅读原文】,查看会议日程。


你也「在看」吗?👇