伯克利大学《深度强化学习》更新 | 第二讲:监督学习和模仿学习

AI 研习社获得官方授权,汉化翻译伯克利大学 CS 294-112 《深度强化学习》,今天更新至第二讲~
我们先来一睹为快——
第二讲
监督学习和模仿学习
上手视频约 8 分钟
翻译 | 陈硕 吕鹏 袁美璐 朱海浩 字幕 | 凡江
看完是不是不够过瘾!
请扫描下方二维码,加入官方学习小组
即可观看完整视频
↓↓↓
回复字幕君(微信:leiphonefansub)
你加入该课程小组的截图
我们将你拉入微信群聊

加我时备注“CS294加群”~
小组介绍
截止到今日,AI研习社学习2018秋季CS294-112深度强化学习小组成员人数突破1200+人啦!
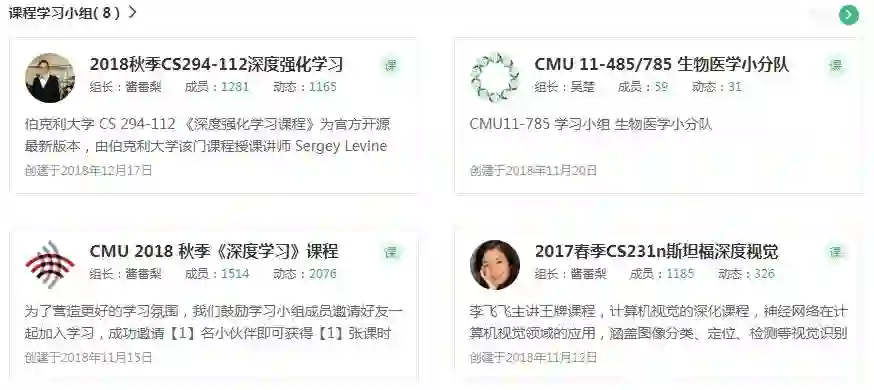
他们在这里打卡
在这里交流笔记心得

「小组」产品上线后,AI 研习社推出了一系列的激励计划,鼓励各位组员学习视频课程,表现积极的学员还将获得由 AI 研习社提供的福利,这些福利包括但不限于机械键盘、双肩背包、AI慕课学院优惠券以及 AI 研习社定制的「浪中求稳」保温杯。
心动了吗,赶快加入学习小组吧!
课程介绍
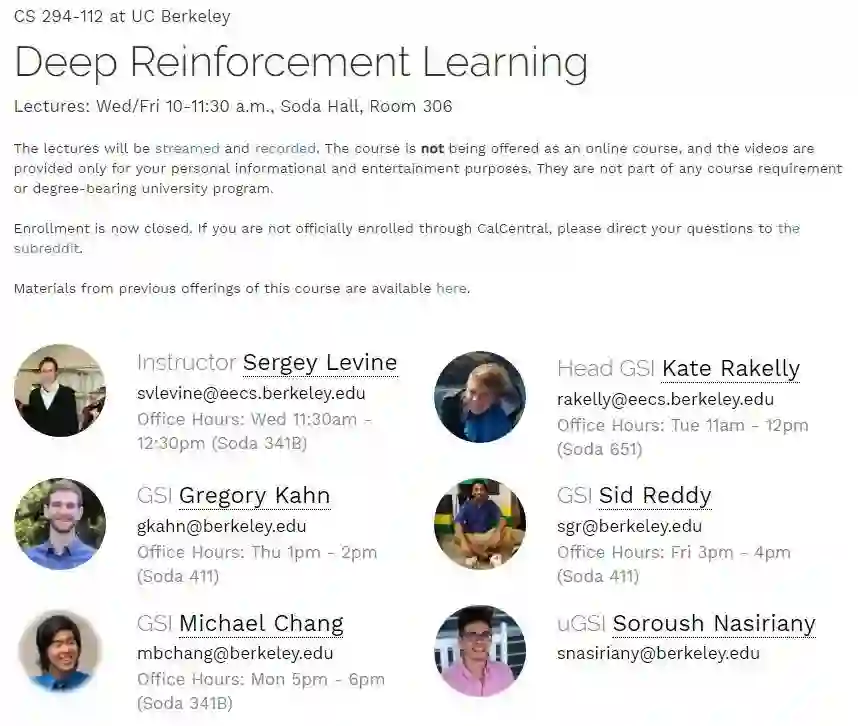
伯克利大学 CS 294-112 《深度强化学习》为官方开源最新版本,由伯克利大学该门课程授课讲师 Sergey Levine 授权 AI 研习社翻译。
12 月 20 日开始正式同步更新在 AI 研习社,大约 1 到 2 周更新一次。
该课程主题选择深度增强学习,即紧跟当前人工智能研究的热点,又可作为深度学习的后续方向,值得推荐。
先修要求
想要学习伯克利大学 CS 294-112 《深度强化学习》这门课程,学生需要先学习 CS189 或者其他同等学力课程。本课程将假定学生掌握强化学习、数值优化和机器学习的相关背景知识。
如果你对上述主题不是非常了解,那么需要自主学习补充以下知识点:
增强学习和马尔科夫决策过程(MDPs)
MDPs的定义
具体算法:策略迭代和价值迭代
搜索算法
数值最优化方法
梯度下降和随机梯度下降
反向传播算法
机器学习
分类和回归问题:用什么样的损失函数,如何拟合线性或非线性模型
训练/测试误差,过拟合
视频截图


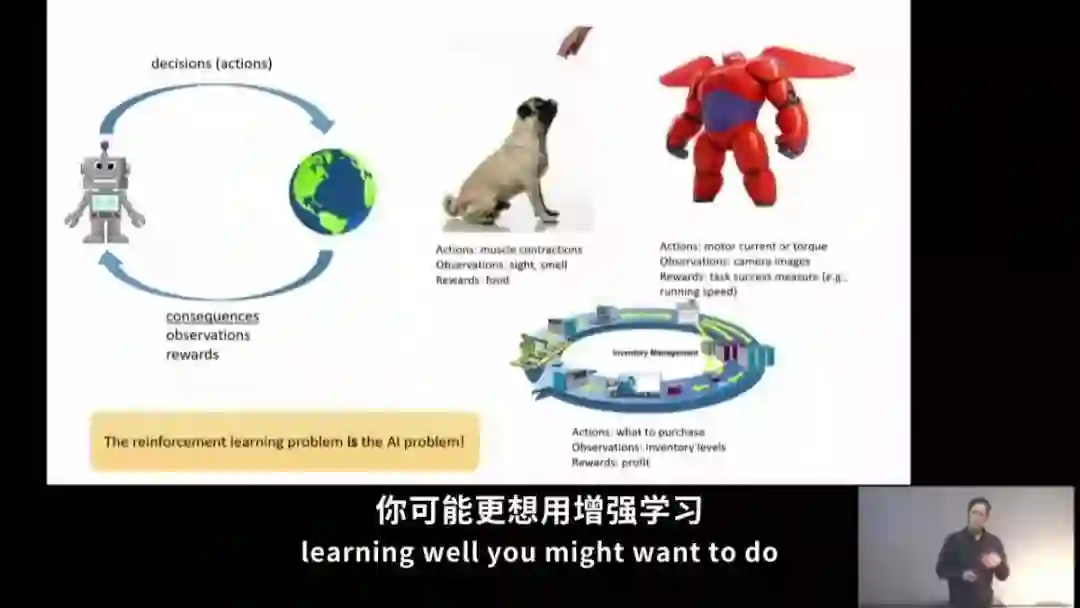
译者评价
比较有趣,讲课用很多例子来解释,不是那种光给你一大堆公式概念的,感觉偏重实际应用和前沿技术一点,推荐大家来看。
@周清逸
这门课是基本覆盖了强化学习的主要内容和前沿的研究话题,通过理论到应用例子的讲述,以及五次作业(实际上是七次)的实践练习对经典算法的复现,可以让学生达到在强化学习领域的入门研究水平。重点是免费!课程有中文字幕!有作业参考!不过这门课并不是零门槛,需要上过机器学习课程,最好是还上过深度学习(比如cmu deeplearning),最最好用过tensorflow(因为作业的官方基础代码只有tensorflow版本)。
@朱海浩
侧重于增强学习与深度学习相结合,应用在机器人方面的例子比较多,翻译的话老师语速挺快的,虽然语气词比较多,整体逻辑很清晰。
@段小杰
课程大纲
第一讲:课程介绍和概览
第二讲:监督学习和模仿学习
第三讲:TensorFlow 和神经网络简述
第四讲:强化学习简介
第五讲:策略梯度简介
第六讲:Actor-Critic 算法简介
第七讲:价值函数介绍
第八讲:高级 Q-学习算法
第九讲:高级策略梯度
第十讲:最优控制和规划
第十一讲:基于模型的强化学习
第十二讲:高级强化学习和图像处理应用
第十三讲:利用模仿优化控制器学习策略
第十四讲:概率和变分推断入门
第十五讲:推断和控制之间的联系
第十六讲:逆向强化学习
第十七讲:探索(上)
第十八讲:探索(下)
第十九讲:迁移学习与多任务学习
第二十讲:元学习
第二十一讲:平行结构和强化学习系统设计
第二十二讲:进阶模仿学习和开放性问题
第二十三讲:客座讲师:Craig Boutilier
第二十四讲:客座讲师:Gregory Kahn
第二十五讲:客座讲师:Quoc Le & Barret Zoph
第二十六讲:客座讲师:Karol Hausman
写在最后:想要参与这门课程的翻译?添加雷锋字幕组微信 leiphonefansub 为好友,备注CS294译者,即可报名,译者招募长期有效哦~
点击【阅读原文】观看第二讲
↓↓↓





