企业网络安全之基础安全
一次性付费进群,长期免费索取教程,没有付费教程。
教程列表见微信公众号底部菜单
进微信群回复公众号:微信群;QQ群:460500587

微信公众号:计算机与网络安全
ID:Computer-network
不管安全实践是多么优秀的互联网公司,其安全体系都离不开一些看起来不那么高大上的基础安全措施,没有了这些,上层那些大数据的入侵检测都如同空中楼阁。之所以能够精确检测是因为在纵深防御中层层设卡,只需要在每个环节关注有限的“点”,也因此入侵检测需要的覆盖面(广度)和检测层次(深度)上随着攻击面的缩小而大幅缩减,提高入侵检测ROI的就是一些看起来不太起眼的安全措施。相反,在低效的安全解决方案里,一个安全设备放在链路上要检测所有的协议并关注所有的行为告警,让本来就不够高效的盒子疲于奔命,最后真正有效的告警被一大堆误报淹没。
一、安全域划分
安全域划分的目的是将一组安全等级相同的计算机划入同一个安全域,对安全域内的计算机设置相同的网络边界,在网络边界上以最小权限开放对其他安全域的NACL(网络访问控制策略),使得安全域内这组计算机暴露的风险最小化,在发生攻击或蠕虫病毒等侵害时能将威胁最大化地隔离,减小域外事件对域内系统的影响。
1、传统的安全域划分
图1是一个典型的传统中小型企业的安全域划分,虚线表示网络边界,也正好是一个安全域。通常会分出DMZ区和内网,在传统的安全域划分中还会通过硬件防火墙的不同端口来实现隔离。但是如今这种方法越来越多地只适用于办公网络,对于大规模生产网络,这种方法可能不再适用。
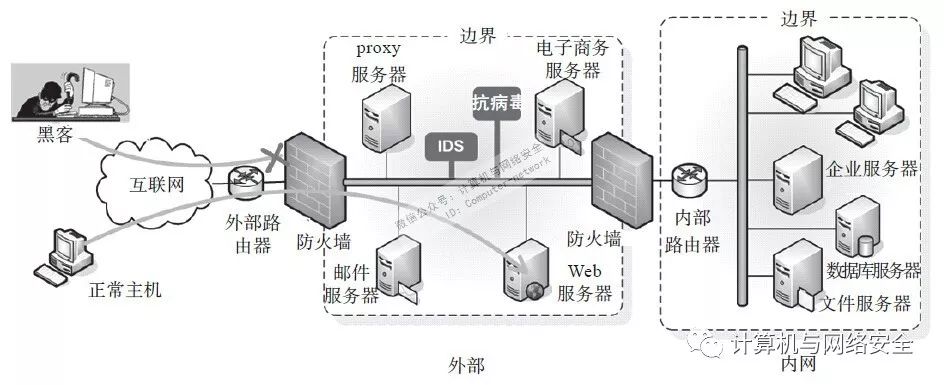
图1 传统安全域示例
2、典型的Web服务
典型的Web服务通常是接入层、应用层、数据层这样的结构,其安全域和访问控制遵循通用的模型,如图2所示。
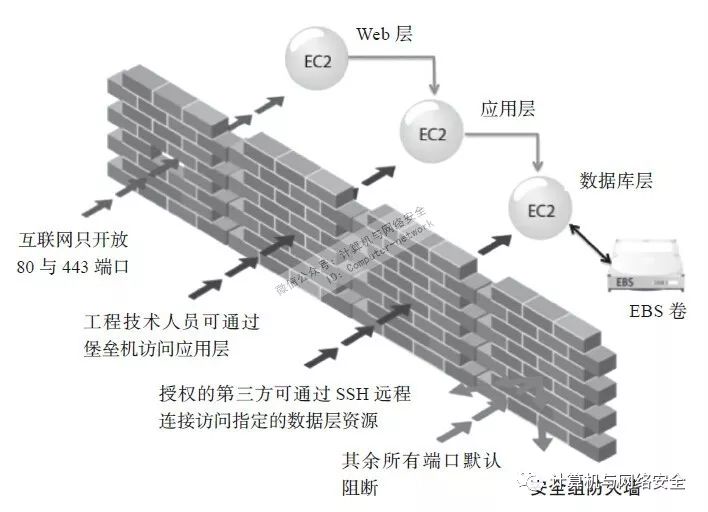
图2 亚马逊Web服务的安全组(ACL)示例
这张图源于AWS对云平台的securitygroup(安全组,相当于3层的防火墙ACL)功能的举例描述。其中Web层是直接在互联网上暴露给用户的,而应用层不需要直接暴露在互联网上,它只需要接受Web的请求,以及能访问位于更靠后一层的数据库层,数据库层则只需要接受来自应用层的请求,同时自己的I/O来自于EBS卷,默认这些服务器都需要接受管理员的SSH连接,但管理员并非从互联网直接发起连接,而是先登录到堡垒主机或统一的运维跳板机,由此再发起向Web层、应用层、数据库层的各SSH连接,如果是使用自动化运维工具的场景,则3层的服务器要接受来自运维管理平台(例如Puppet、SaltStack服务端)的连接,这样每层只对外开放最小端口,除必要的协议外默认全部阻止访问。
安全域划分没有限定为一定要划vlan,基于L3、L4的防火墙规则,甚至NAT都可以起到隔离的作用。仅仅是基于L2的划分比L3以后的更加可靠一点。
3、大型系统安全域划分
Open Stack有一个API流程图,如图3所示。
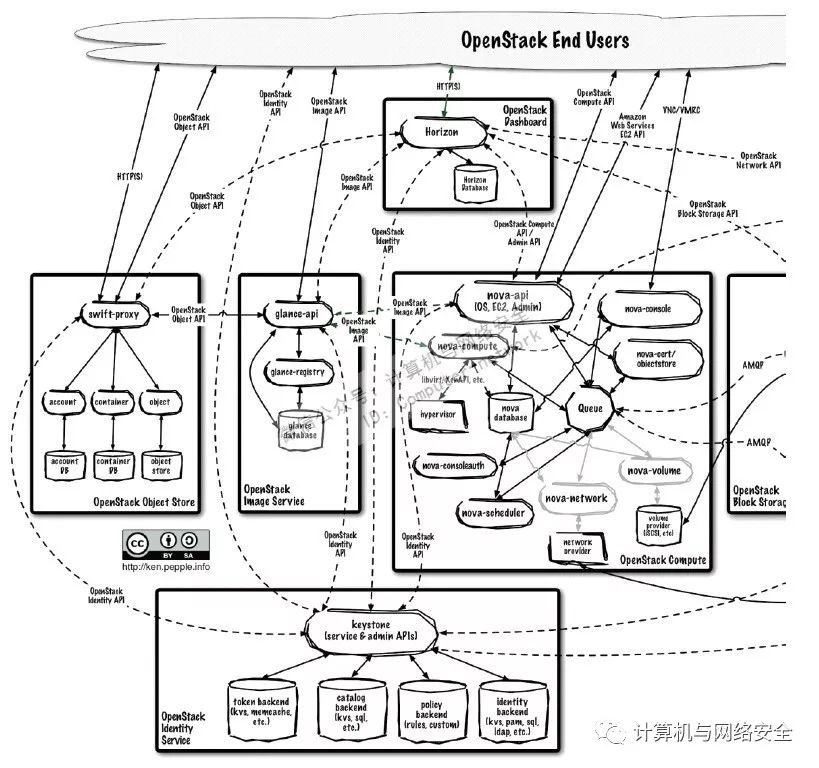
图3 OpenStack API流程图
大家觉得图3可以用来做OpenStack安全域划分的参考吗?图示中表明了一些数据流和引用关系,但最大的问题在于没有标示出OpenStack各节点的安全等级,例如租户资源池和管理节点没有区分出来,管理服务中也有分类分级,偏后端的和更接近租户容器的应该区分开来,公共服务类的也应独立标示,这样才能从整体上区分不同的资源(服务器、存储、网络设备)属于什么安全域。
在大型互联网服务中,一般可以用图4来抽象表示对外提供的服务的关系。当然,这只是一个对典型服务区域的抽象,真正的结构可能比图示要庞大得多。
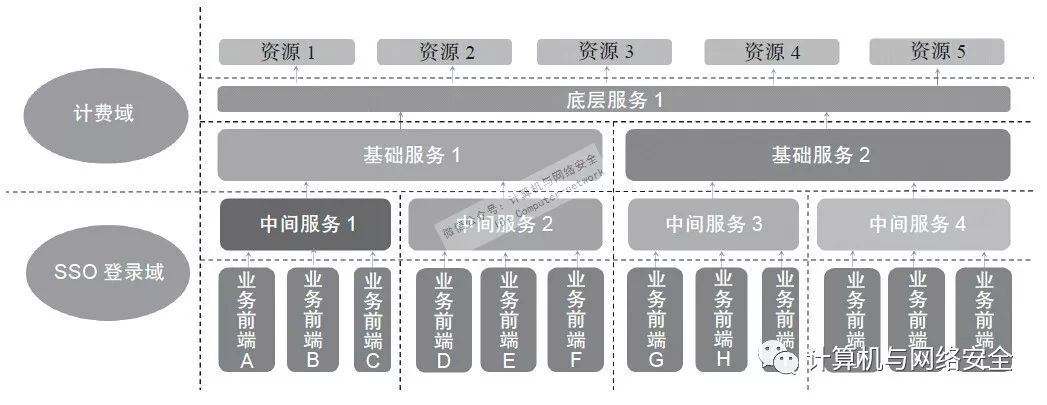
图4 互联网服务安全域抽象示例
虚线部分代表安全域的边界。其实通俗一点讲就是个“切蛋糕”的游戏,把不同的业务(垂直纵向)以及分层的服务(水平横向)一个个切开,只在南北向的API调用上保留最小权限的访问控制,在东西向如无系统调用关系则彼此隔离。当然,这个隔离的程度在不同规模的网络里会不一样,小一点的网络可以做到很细,但是大型网络如果做得非常细,运维工作量会非常大,当一个网络需要变更的时候访问控制策略会让人彻底歇菜。所以具体实践上是需要权衡这些方法的。相同之处在于,不管网络规模大和小,基本都遵从类似的架构,区别只在于粒度粗细。
如果希望尽可能在内网少隔离,有利于弹性网络伸缩,前提是基于服务器的单点入侵检测和防护能力比较强。
4、生产网络和办公网络
这里只介绍办公网络和生产网络连接部分所涉及的安全域问题,如图5所示。
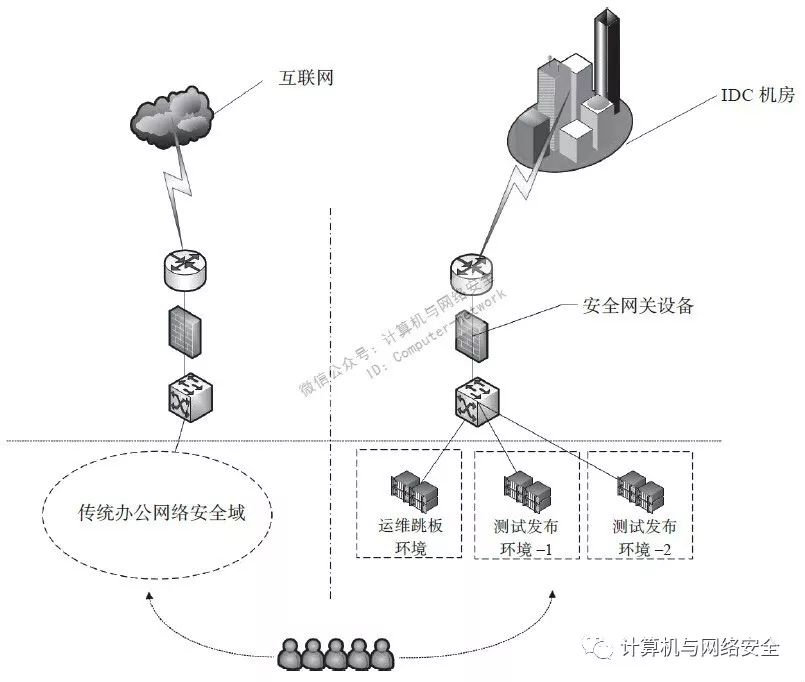
图5 办公网络安全域划分
渗透生产网络可以用社会工程学从办公网络绕一圈的方法,加上互联网公司的主营业务就是对生产网络的频繁发布和变更,所以才使得运维、产品交付及测试环境需要“区别”对待。为保证最大的隔离,需要尽可能地采取如下几个方面的措施:
● 生产网络的SSH 22端口在前端防火墙或交换机上默认阻止访问。
● 远程访问(运维连接)通过VPN或专线连接到机房生产网络。
● 通过生产网络的内网而非外网登录各服务器或自动化运维平台。
● 办公网络中运维环境、发布源和其他OA环境VLAN隔离。
● 虽然在同一个物理办公地点,但运维专线和办公网络的接入链路各自独立。
● 为保证可用性,运维专线最好有两条以上且来自不同的ISP,防止单链路故障时无法运维。
● 跳板机有所有的运维操作审计。
有了这些隔离措施之后,“绕一圈”的渗透方法并非绝对不可行,但会难很多。
二、系统安全加固
系统安全是所有安全工作的第一步,这部分内容可以归入安全基线。当然这部分并不是完整的系统安全加固方案,仅仅是拿一些例子来说明,什么才是攻防意义上的安全加固。市面上的很多加固措施,有一半操作是“不痛不痒”的,既不能说它无用,也没觉得对系统安全提升有多大帮助。
1、Linux加固
关于Linux加固的文章,网上已经有很多,所以只挑一些有针对性的点说一下。
(1)禁用LKM
在一定程度上为了规避类似于knark、adore这类的LKM rootkit,把入侵检测聚焦于用户态:

也可以使用sysctl命令:

无论是echo 1>赋值还是sysctl的方法在系统reboot后都会失效,所以需要加入启动项,编辑/etc/sysctl.conf文件把相关项写入。
当然,上面这些属于治标型的方法,不是治本型的,如果入侵者拿到root后,装载内核rootkit重启一次系统就能开启LKM功能。治本的方法是在编译内核时去掉LKM支持,这样相关代码就不会编译进内核:
#make config
Loadable module support(可加载模块支持)?(1)Enable loadable module support (CONFIG_MODULES) [Y/n/?] 选择“n”
或者:
#make menuconfig
结果如图6所示。
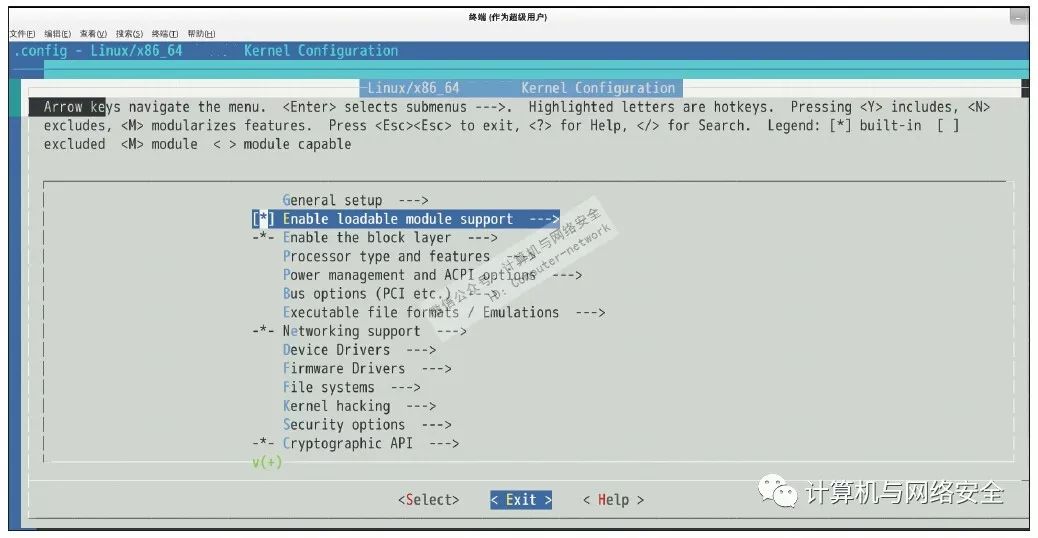
图6 Linux内核编译选项
采用治标型还是治本型的方法根据场景而定,如果确定基本不会频繁用到内核模块功能,可以激进一点选择治本型方法,如果某些机器需要经常变更驱动,保守一点可以选择治标型。
(2)限制/dev/mem
新版本的系统默认都不再使用/dev/kmem这个文件,查看/boot目录下的config文件确保CONFIG_DEVKMEM设置为“n”:

CONFIG_STRICT_DEVMEM设置为“y”:

如果只禁用LKM,则phrack 58(http://phrack.org/issues/58/7.html)中“Linux on-the-fly kernel patching without LKM”这篇文章提到的通过/dev/kmem&/dev/mem读写全地址空间的方法的rootkit仍然可以在用户态实现内核rootkit的功能,典型的代表就是suckit,而在使用上述设置后suckit也会失效。
虽然不绝对,但一般情况下可以无视内核态,把入侵检测聚焦于用户态,如果要提高入侵检测的效率,就必须只关注更少的点,如果关注的点非常多,很容易被信息淹没。可能也有人会问这样做是否有些过激,其实还好,服务器环境相比客户端环境还是有很大的不同,服务端环境相对固化,比如通常不需要开发工具,经常变更部分主要集中在服务器软件的配置和应用的代码数据,其余的变更比较少。而入侵过程则相反,可能会动到一些运维不经常变更甚至不应该变更的部分。
(3)内核参数调整
加固文档系统的ASLR,地址空间随机映射(一种缓冲区溢出缓解机制),启动设置为2:
kernel.randomize_va_space=2
/proc/sys/kernel/randomize_va_space的值如下:
0 关闭ASLR
1 mmap base、stack、vdso page将随机化。这意味着.so文件将被加载到随机地址。链接时指定了-pie选项的可执行程序,其代码段加载地址将被随机化。配置内核时如果指定了CONFIG_COMPAT_BRK,randomize_va_space默认为1。此时heap没有随机化。
2 在1的基础上增加了heap随机化。配置内核时如果禁用CONFIG_COMPAT_BRK,randomize_va_space默认为2。
隐藏内核符号表,启动设置为1:
kernel.kptr_restrict=1
/proc/sys/kernel/kptr_restrict
内存映射最小地址,启动设置为65536:
vm/mmap_min_addr=65536
/proc/sys/vm/mmap_min_addr
实际上目前除了Docker的公有云多租户环境(私有云不需要),一般情况下也不会选择这么激进。更多的还是希望某些Linux的发行版本中以默认配置集成各种攻击缓解机制。退一步则希望即便默认不开启,但以内核参数等形式提供更高保护级别的选择权。Windows新版本提供的这方面的保护也越来越强,Linux应该也会有这种趋势。
(4)禁用NAT
攻击者在渗透内网时经常用到的一个技巧就是在边界开启端口转发,这样能提供一个方便的途径访问内网服务器,所以防御者要做的就是禁用IP转发:
# echo 0 > /proc/sys/net/ipv4/ip_forward
当这个值无缘无故变更为1时,说明很可能是出了安全问题。
但有些服务可能会用到,比如需要网关路由功能的,例如LVS提供负载均衡,Docker也需要。
(5)Bash日志
系统默认有一个日志文件.bash_history在用户目录下:

打开~/.bashrc文件添加以下配置。
设置环境变量为只读:
readonly HISTFILE
readonly HISTFILESIZE
readonly HISTSIZE
readonly HISTCMD
readonly HISTCONTROL
readonly HISTIGNORE
为history文件添加时间戳:

使之生效:
source ~/.bashrc`
设置history文件只能追加:
# chattr +a ~/.bash_history
对所有可登录用户的shell history全都添加以上属性。
禁用其他的shell:
● /bin/ksh(Kornshell由AT&T贝尔实验室发展出来的,兼容bash)
● /bin/tcsh(整合C Shell,提供更多的功能)
● /bin/csh(已经被/bin/tcsh所取代)
● /bin/zsh(基于ksh发展出来的,功能更强大的shell)
更改HISTFILE为其他文件:
HISTFILE=/usr/local/log/cmd
并保留原路径下的.bash_history文件。
上面这些配置其实都只是一些小技巧,本意是希望应急响应时有命令行记录,能够尽可能“省事”。很多加固项其实都能绕过,但这个比较低的防御门槛还是会起些作用:
● 对Linux系统不够熟悉的入侵者。
● 不够“机智”的自动化日志清理工具。
● 自动化攻击的bot程序。
对于高手的入侵者而言,这些措施可能就不太管用了,在安全防御的中高阶一段,会逐步开始自己发明轮子,不完全依赖于系统提供的既有机制。
(6)高级技巧
争取“一劳永逸”地解决shell历史记录的问题。为什么如此偏爱命令行记录呢?因为再优秀的入侵者也要用shell,另一方面对于安全工作者而言,由shell命令行记录做入侵分析会简单很多。高阶的方法就是修改shell本身,不依赖于内置的HISTFILE,而是对所有执行过的命令无差别的记录。
修改shell源代码是一种方式,不过相比之下,直接修改libc可能会更加高效。主要涉及的对象就是exec函数族:
#include <unistd.h>
extern char **environ;
int execl(const char *path, const char *arg, ...);
int execlp(const char *file, const char *arg, ...);
int execle(const char *path, const char *arg, ..., char * const envp[]);
int execv(const char *path, char *const argv[]);
int execvp(const char *file, char *const argv[]);
int execve(const char *path, char *const argv[], char *const envp[]);
修改以上库函数,支持额外的syslog,这样能记录所有运行过的程序。实际上,另外5个函数都是调用的execve()。
另一种shell审计的高级方式是将shell的log统一收集后基于机器学习,以算法学习正常管理员的shell命令习惯,而不是以静态规则定义黑白名单。比如公司的运维人员习惯用“ls–al”而不是用“ls–la”或者“ll”,还有比如正常的管理员可能不太会去敲击一些冷门的命令,如“whoami”,更不可能用“xxxxxx|/bin/bash|xxxxxx”或“xxxxx/dev/tcpxxxxx”这种反弹shell的命令。
2、应用配置加固
(1)目录权限
有句话在安全圈流传:“可写目录不解析,解析目录不可写”,这句话主要用于对抗webshell,寓意为攻击者通过文件上传漏洞,上传webshell或通过应用层漏洞(例如SQL注入)在可写目录下写入一个webshell功能的脚本后,因为没有执行权限,无法通过webshell执行命令,或者当目录有解析执行权限的时候,因为没有写权限,无法在目录下生成webshell的文件也不能向已有的业务代码中写入webshell而达不到渗透的目的。这个规则实际上源于新型编程语言诞生之前的时代,在诸如node.js等新兴语言发展的时候,这些规则可能适用面会越来越小。
解析目录不可写,以root用户为例:
#chmod 755 /web/root
如果业务需求部分子目录要改为777权限,则更改目录属主为Web进程用户:
#chown nginx: /web/root/childdir
可写目录不解析。对于PHP,在Nginx配置文件中添加如下配置,即可禁止log目录执行php脚本:
location ~* ^/data/cgisvr/log/.*\.(php|php5)$ {
deny all;
}
对于Java,Tomcat默认解析jspx文件格式后缀,若不需要使用jspx文件,则删除对jspx的解析,具体操作为修改conf/web.xml文件:将如下代码注释掉。
<url-pattern>*.jspx</url-pattern>
(2)Web进程以非root运行
Web进程以非root权限运行遵循了最小权限原则,假如以root权限运行则带来两方面的问题:
● 如果守护进程存在远程溢出类漏洞,则通过exploit攻击后远程基本上就能得到:rootshell“#”。
● 如果应用层代码出现漏洞,所有的脚本(也包括上传的webshell)将直接以root权限执行系统命令,整个入侵过程无须提权就可以一步到位,入侵的途径平坦了很多:

Nginx的master进程默认以root权限运行,而处理用户数据的worker进程默认以Nginx(nobody)权限运行。
(3)过滤特定文件类型
一些文件对于正常用户访问并不需要,但是扫描器喜欢,渗透者也喜欢人肉猜测,例如管理员不小心在Web目录下留了一个备份文件,里包含了一个重要的key,通过这个key得到了应用后台管理员的权限,攻击者就达到了目的。诸如.bak、.log、.zip、.sql这些都是正常访问的用户不需要的,一般用户体验做得比较好的网站会把HTTP 404重定向到公益或广告类的友好界面,对于安全来说,则需要通过rewrite规则把攻击特征的URL重定向到我们自己的页面,而避免让攻击者下载到不该下载的文件,如下所示:
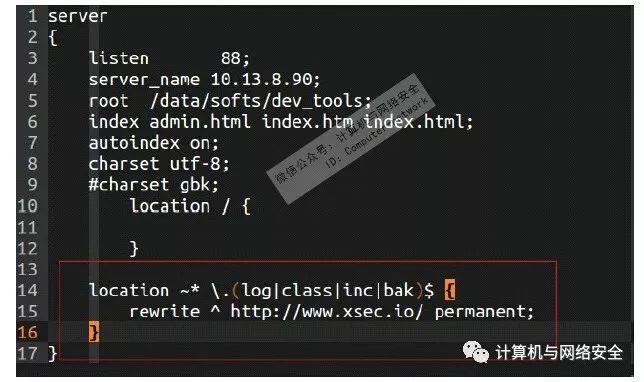
在这个配置中:
location ~* \.(log|class|inc|bak)$ {
rewrite ^ http://www.xsec.io/ permanent;
把.log.class.inc.bak类型的文件做了重定向。当然,有些例如.inc不能完全过滤,这些都需要与运维以及开发讨论一下。
Modrewrite还可以做很多事情,比如根据客户端cookie做人机识别,但是毕竟还是有WAF这个东西在,所以就不打算让它承担太多职责了。
3、远程访问
SSH是目前最常见的远程访问之一,在生产网络中占比率最高,一般来说需要几点:
使用SSH V2,而不是V1:
Protocol 2
禁止root远程登录:
PermitRootLogin no
4、账号密码
账号密码的涉及范围非常广,包括OS、数据库、中间件/容器、所有的应用管理后台、网络设备、安全设备、自动化运维管理后台、VPN账号等,之所以在系统加固之外单列出来是因为密码暴破已成为当下比较主要的渗透方式之一,从来都没有哪个时代像当前这样热衷于猜解密码。
对付暴力破解最有效的方式是多因素认证或非密码认证,考虑到可用性的问题,不太可能开启账户登录失败锁定策略,那样的话就随着互联网上的暴破直接变成拒绝服务了,所以在无法使用MFA(多因素认证)或证书认证的场合,最低的底线的还是设置复杂的密码,但是什么才算复杂的密码呢?这个定义可能跟过去完全不同。过去满足一定长度和复杂度的就算是可以,而如今攻击者早已站在大数据的维度,即攻击者手上拥有各种社工库,拥有几十亿网名的常用密码,尽管可以设置一个看上去有一定复杂度的密码,但只要这个密码在黑客的“字典”里,在攻击者的数据库中,那实质上还是一个“弱”密码。有些入侵事件的根因分析,因为觉得自己管理员密码比较长所以就主观排除了通过口令入侵的可能,但是在其他点上又找不到原因,然后顺着APT的方向去了,再然后就没有然后了……其实没想到就是“弱”密码导致的。
站在攻击者的角度,自己主动破解密码在当下的互联网行业已经算不上是什么激进的手段了。作为甲方安全团队,平时也应该收集各种社工库,把公司内部研发测试运维常用的“弱”密码做成字典,周期性地更新这个字典并主动尝试破解公司内各个系统的账号,能破解的都视为弱密码,即可要求相关人员整改。越往后,一厢情愿地站在防御者角度做安全会越来越难做,防御者必须跟随攻击者的脚步,避免被“领先一个时代”。
5、网络访问控制
安全域和访问控制的区别在于,安全域是更加高层次的圈地运动,而NACL相对更具体化,针对的是每一个系统;安全域相对固化,基本不会变动,而NACL则会应需而变。
有人说防火墙这种东西会淘汰,这种观点跟“计算机终究会消亡”是一样的,没什么意义。防火墙在安全管理的技术手段里占的整体比重是越来越小,但不代表它没有价值或彻底淘汰,实际上防火墙在NACL领域里扮演着无可替代的作用。
在大型互联网里,购买商业防火墙产品可能会越来越少,大部分都会转为使用Netfilter+高性能PC服务器。当然,也有用得到商业产品的时候,例如在DC的出口可能会部署高性能的硬件防火墙,这个防火墙实际并不充当传统意义上访问控制网关的作用。而是很多时候需要在总出口部署几条类似于“黑名单”的总体策略(几条策略几十万元,一条策略十万元是不是有点小奢侈),例如公有云环境,租户的业务需要开放哪些端口是不确定的,不能替他做主一刀切,这个策略有可能是临时的,也可能是持久的,但在核心交换机上做太多NACL不合适,于是把NACL还是单拆出来,串联一个硬件防火墙,在防火墙上做具体的NACL。如果防火墙后的业务是确定开放某几个端口,则防火墙可以过滤所有的不必要端口充当起访问控制网关的作用。
除了网关级的访问控制以外,还有机柜级的NACL和系统级的NACL,机柜的上联交换机可以做一些简单的NACL,其细粒度以不影响正常的运维便利为准。
系统级的NACL用OS自带的防火墙就完全够用了,只开放服务端口和管理端口,个别高等级安全域的机器可以对源进行更细粒度的限制,对于数据库应限制只允许应用服务器IP连接3306、1433等端口。
生产网络多层NACL架构如图7所示,采用多层NACL的原因在于,一方面安全域之间需要隔离,安全域内部也需要划分,另一方面当某一层的NACL失效时,还有其他层的NACL在抵挡,不会马上变成“裸奔”模式。实际上,某一NACL失效可能是一件很容易碰到的事情,因为某些网络变更,或者因为调试,人为地申请了临时策略,或临时取消防火墙策略,完事后又忘了“回滚”,甚至连审批策略的人自己都忘了这事了。不太严重的情况下,由于暴露了攻击面,入侵检测的告警数量会因网络蠕虫和自动化攻击工具的行为急剧增多,严重一点,被盯梢的情况下,可能就被渗透了。
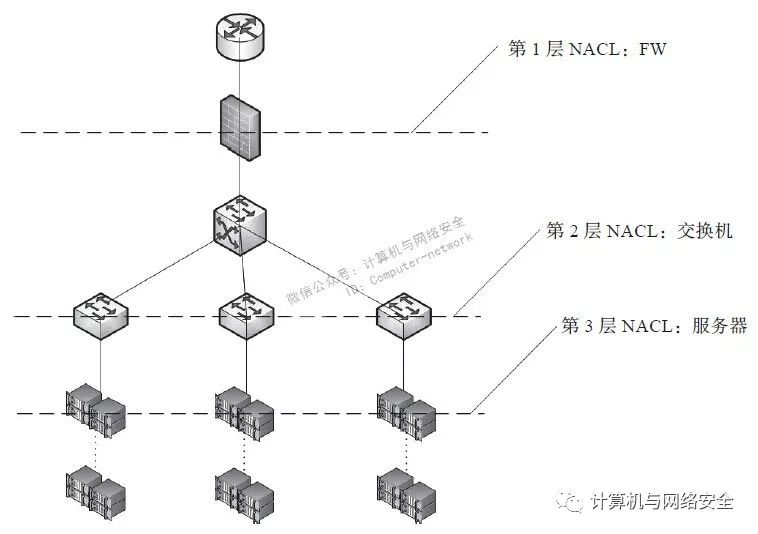
图7 生产网络多层NACL架构
在海量IDC追求弹性运维的架构中,可能NACL无法实施到理想状态,这就要求在两个方面做补偿:
1)资产权重划分到位,对最高安全优先级的网络追求多维和细粒度NACL,余下的可适当放松。
2)单点实现较强的入侵检测和降维防御能力。
超大规模IDC下的安全域和NACL是一个比较有挑战的话题,尤其是对于快速成长的业务,其IDC资产往往都是分散的,甚至数据库都不在一块儿,如何在这种状态下做网络访问的风险隔离是进入“最佳实践阶段”会面临的问题。
6、补丁管理
打补丁似乎应该算是安全日常工作中最基础的项目了,不过在互联网行业里,这项工作已经跟安全的相关性不是特别大,而是越来越多的体现运维的能力:
● 自动化运维:如何大批量地push补丁。
● ITSM成熟度:打补丁尽可能不影响在线服务的可用性。
● 架构容灾能力:支持有损服务,灰度和滚动升级,好的架构应该支持比如让逻辑层的某些功能服务器下线,接入层把流量负载均衡到其他服务器,打完补丁后再切回来。
● 系统能力:提供热补丁,不需要重启。
● 快速单个漏洞扫描:补丁push升级成功的检测。
安全团队需要考虑的是评估漏洞的危害和对自有系统的影响,这点依赖于很多能力,包括:1)资产管理和配置管理;2)海量IDC下的系统层和应用层漏洞判定,需要用到很多维度的数据,比较严重的可能就要加班加点了,不那么严重的可以合并到下一次运维时间窗口实施,没有实际攻击面和利用可能性的可以直接忽略。
7、日志审计
日志成千上万,一开始就想建SOC的往往都是没有经验的人。看的PPT多了,听厂商介绍多了,自己也想弄一个SOC,其实一开始是完全没有必要的,这个时候建SOC只会成为一个摆设。基础的数据源和告警的误报都没解决的时候,纵深防御体系还完全没弄起来,也就是生态链的底层地基都未建好,就直接想去建金字塔顶,那是理论派才做的事情。
很多日志800年都不会去看的,安全团队就那么点儿人,哪有人天天有时间去看那么多的日志。但是在初期有些是比较重要的,运维操作的远程访问SSH等限定唯一入口,且通过堡垒主机,那这个时候就可以关注一下lastlog和/var/log/secure看一下成功登录的部分是否有不是自己雇员的行为,不是堡垒机发起的成功登录很可能就是入侵者。对于这一类有切实需求,且有人会去关注一开始可以纳入日志审计的范畴,具体实现上,可以通过syslogd导出日志,统一集中存储,是否要用ELK、splunk之类的就看每个公司具体的需求了。
三、服务器4A
4A指:账户(Account)、认证(Authentication)、授权(Authorization)、审计(Audit)。对于较大规模的服务器集群,不太可能使用每台服务器单独维护用户名密码(或是证书)的权限管理方式,而必须使用类似于SSO的统一权限管理。目前主要有两种方式:一种是基于LDAP的方案,另一种是基于堡垒机的方案。
1、基于LDAP
基于LDAP的服务器SSO架构如图8所示。
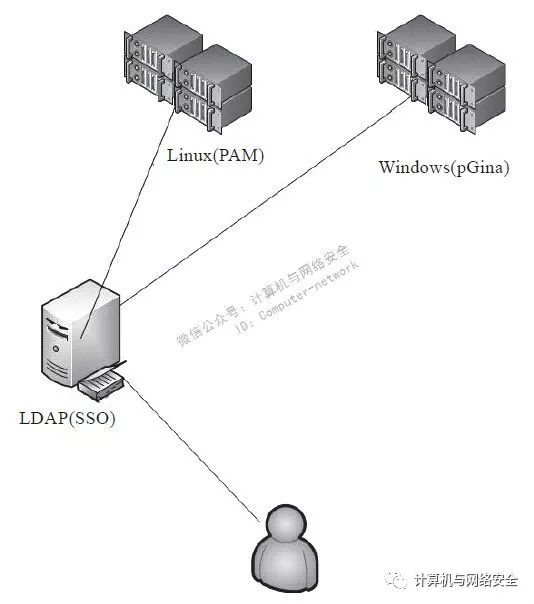
图8 基于LDAP的服务器SSO架构
LDAP的方案可以使用LDAP服务器作为登录的SSO,统一托管所有的服务器账号,在服务器端对于Linux系统只要修改PAM(Pluggable Authentication Modules?),Windows平台则推荐pGina(pGina是一个开源插件,作为原系统凭证提供者GINA的替代品,实现用户认证和访问管理),使登录认证重定向到LDAP服务器做统一认证。
2、基于堡垒机
基于堡垒主机的方式如图9所示。
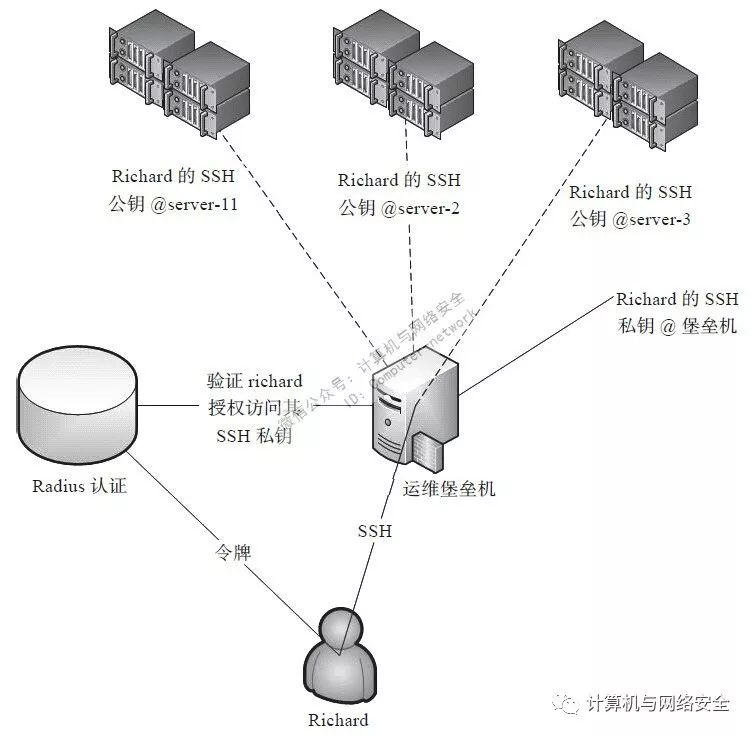
图9 基于堡垒机的服务器SSO架构
在Radius上新建用户Richard,为该用户生成SSH的公私钥对,使用自动化运维工具将公钥分发到该用户拥有对应权限的服务器上。用户的SSH连接由堡垒机托管,登录时到Radius服务器使用动态令牌认证身份,认证成功后授权访问其私钥,则对于有SSH公钥的服务器该用户都可以登录。网络访问控制上应设置服务器SSHD服务的访问源地址为堡垒机的IP。
微信公众号:计算机与网络安全
ID:Computer-network