![]()
来源:reddit
编辑:舒婷、白峰
【新智元导读】近日,Reddit社区一篇批判机器学习领域的文章引发了热议,获得了3.1k的赞。作者细数了机器学习领域存在的「八宗罪」,让科研人员对机器学习大环境有了新的思考。
越来越多的科研人员都选择进入机器学习这个领域。
科研人员进入领域时的初衷是「伟大」的:他们相信,机器学习能够真正的改善人们的生活。所以每年机器学习有关的顶会投稿数目几乎是成倍的增长,这些新的科研成果似乎真的能带来一个更好的未来。
Reddit社区一位作者却站出来说:「The machine learning community has a toxicity problem.」
![]()
他细数了机器学习领域的「八宗罪」,让科研人员对现行的机器学习大环境进行有了新的思考。这篇文章在Reddit收到了3.1k的赞。
NeurIPS会议中接收的论文,每四篇就会有一篇被放在arXiv上。 有些DeepMind 的研究人员公开追究那些批评他们 ICLR 投稿的评论者。
虽然审稿人对这些知名机构的arXiv论文给出了拒绝的意见,但是最后仍然被一些顶会接收。
在测试集中调整优化超参数似乎是现在的标准做法。但是,即便使用技巧让超参数得到了调优,性能是否真正提高是一件不置可否的事情。
和斯坦福,Google或DeepMind存在联系的每篇论文都会得到赞誉
,BERT被引用的次数是ULMfit的七倍。ICML会议上,DeepMind海报吸引力远高于别的海报。此外,尽管NeurIPS 和ICML都是顶级ML会议,前者提交量是后者的两倍,或许仅仅是因为「神经」这个词语?
前几日Yann LeCun谈论偏见和公平话题时的语气是直率的,但是攻击他的人的语气却是恶毒的
,并且太多太多人选择攻击他而忽略了事件本身。人们或许没有意识到,逼迫LeCun离开推特其实没有解决任何问题。
像其他的计算机科学学科一样,机器学习也存在着多样性问题。不可否认的,
在我们的CS系中,只有30%的本科生和15%的教授是女性。
在博士学位或博士后休育儿假通常意味着学术生涯的结束。领域中的研究者选择逃避来掩饰自己对种族主义或性别歧视的害怕,但是却让这个问题更严峻。
美国国内政治主导着所有讨论,包括学术界的。计算机视觉算法的数据集几乎不涉及超10亿人口的非洲人,但没人在乎。
每个人都会在研究最后说「有更深远的影响」,但是这样的影响往往限定在特定人群内。
研究只是为了发表,
撰写论文的唯一目的已经变成在简历中增加一行文字
。论文质量?那是次要的,重点是通过同行评审。研究小组的人数多到导师不一定能知道每个博士生的名字,每年向NeurIPS提交50篇以上的论文已经成为某些研究人员的常态。
Schmidhuber称Hinton为小偷,Gebru称LeCun为白人至上主义者,Anandkumar称Marcus为性别主义者。
研究人员很容易受到攻击,被套上「侮辱性」的帽子,但这甚至和研究本身无关。
「盲目崇拜确实存在,但我想提出另一个假设,说明Google / DeepMind 的论文为何受到更多关注:信任」。
每天都会有大量新发表的论文,所以不可能全部读完。
使用作者进行过滤是我常用的方法,尽管有偏见,但是很有效。
不是说DeepMind的研究人员比其他人更有才华,但他们承担更多的风险。
DeepMind发表的论文通常是有效的,如果论文灌水或者不可复现,那将对整个公司产生不良影响,因此,这些组织发表的论文很可能在发布之前就经过了更严格的「质量控制」流程和内部同行评审。
我自己对此感到内疚,因为我定期阅读的是arXiv提交的新文章的「标题」。
当我看到一些有趣的东西时,我会先看作者,如果是DeepMind / Google / OpenAI / etc,我会仔细看一下。如果是一群我从未听说过的人,我就会翻篇。为什么?因为在我看来,后一组作者更有可能「编造东西」,而且他们的错误没有被注意到,因为他们没有像DeepMind论文那样经历相同的内部质量控制,我更有可能收到错的信息。这与我崇拜DeepMind无关,由于他们的工作方式让我更信任。
这样做错了吗?
也许确实有偏见,我们应该更多关注内容本身
,但是有时论文太多了,谁也不想浪费时间。
也有人反驳这种偷懒的行为。「我就能不看作者,快速读完一堆论文」。好吧,一目十行君真的有。
关于第三宗罪也有网友为Google鸣不平,BERT让语言模型变得非常易用给其他研究者做了很多铺垫,确实该获得更多关注,ULMfit引用量没BERT多也很自然。
网友@dataism和几个小伙伴还专门写了一篇论文讨论当前机器学习领域论文存在的几个突出问题。
最近机器学习的进展,尤其是深度学习,引入了几个复杂任务中超越传统算法和人类的方法,从图像中的物体检测、语音识别到玩困难的战略游戏, 然而
很多算法以及它们在现实世界中的应用,似乎存在一个循环 HARKing (结果已知然后还提出假设)。
这篇文章详细阐述了这一现象的算法、经济和社会原因以及后果。文中列举了一些常见的操作,例如
将负面结果隐去,不提泛化能力
等等,感兴趣的同学可以仔细读一下,降低论文被拒的风险(我并不是在宣传这些灌水技巧)。
还有一个比较热的讨论是关于作者学校的歧视,这在学术界很普遍,尤其是在CS / ML领域。
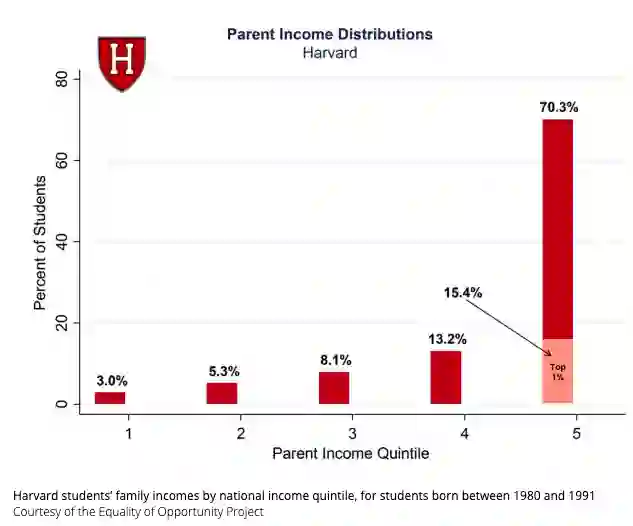
当你身处哈佛、斯坦福,你的论文被接受的概率就会高很多。而这些名校的录取本身就是有财富和名誉偏见的,你可以找一堆理由否认,但数据不会说谎。
如果你的父母念过斯坦福,那么你被录取的概率就是其他人的三倍!哈佛的情况也不例外。
![]() 父母收入在Top 1%的学生占了15.4%的比例。
「多元化与包容性」的口号在机器学习领域几乎完全抛弃了贫穷家庭或没有接受过高水平教育的家庭。在学术界,来自社会底层的学生被拒绝的比例可能更疯狂。
https://www.reddit.com/r/MachineLearning/comments/hiv3vf/d_the_machine_learning_community_has_a_toxicity/
父母收入在Top 1%的学生占了15.4%的比例。
「多元化与包容性」的口号在机器学习领域几乎完全抛弃了贫穷家庭或没有接受过高水平教育的家庭。在学术界,来自社会底层的学生被拒绝的比例可能更疯狂。
https://www.reddit.com/r/MachineLearning/comments/hiv3vf/d_the_machine_learning_community_has_a_toxicity/
![]()





 父母收入在Top 1%的学生占了15.4%的比例。
父母收入在Top 1%的学生占了15.4%的比例。



