百度王海峰Quora精华整理:未来5-10年,NLP领域将会有什么进展?

AI科技评论按:近日吴恩达发文将在4月底离职百度。几乎在同一时间,百度也宣布进一步深度整合,将包括NLP、KG、IDL、Speech、Big Data等在内的百度核心技术,组成百度AI技术平台体系(AIG),并任命百度副总裁王海峰为AI技术平台体系(AIG)总负责人,同时晋升为Estaff成员,转向百度集团总裁和首席运营官陆奇汇报。
王海峰是自然语言处理领域的权威科学家,是该领域最具影响力的国际学术组织ACL 50多年历史上唯一出任主席(President)的华人,同时也是截至目前最年轻的ACL Fellow,也是唯一来自中国大陆的ACL Fellow。
此外,王海峰博士还是中文信息学会理事、中文信息学报编委、中国计算机学会(CCF)高级会员、国家自然科学基金委员项目评审会评审专家组成员。
王海峰博士出席的媒体活动不多,但在Quora上比较活跃。AI科技评论根据王海峰博士在Quora上的五个精华问答整理成本文。另外此前王海峰博士在AAAI2017上应邀做了名为《百度的自然语言处理》的报告,全面梳理百度这些年在NLP领域的工作,在此也一并奉上。
王海峰Quora五答
1、从一名科学家转变为一个IT公司的总裁,你如何看待这种职业变化?
我对技术感到着迷,并乐于沉浸在研究工作里。我始终相信,科技能够改变世界。百度为我提供了一个理想的平台,在这里我从事的技术工作可以快速直接地让用户受益。这就是我一开始加入百度的原因。在百度最初的几年时间里,我领导了NLP、语音、图像、数据挖掘、知识图谱、机器学习、深度学习等多个团队。后来,我意识到伟大的产品将会连接技术与广大用户,反过来也会更加促进技术进步。伟大的产品,不仅需要先进的技术,还需要杰出的设计、优秀的营销和高效管理。因此我渐渐改变了自身的角色,从一个单纯的研发团队负责人,转变为管理层的一员。我如今领导的团队有3000多人,包括技术、产品和营销成员,他们都很年轻、精力充沛、富有激情。我们拥有着一个共同目标:用技术和产品改变大众日常生活。
当掌管一个大型商业团队的时候,我需要首先制定策略和目标,然后建立一个合适的执行团队。对于一个大型团队来说,良好的规则和文化,开始成为支撑和保证业务运行的重要因素。与此同时,对于科技领域的重大突破、用户需求的演变,以及整个社会的发展趋势,我都保持极大的关注。
2、未来5-10年,NLP领域将会有什么进展?
机器翻译、语义理解、问答和对话技术将会有重大突破。这些技术将会被广泛应用,并最终改变人与计算机、人与各种硬件设备、以及人与人之间的沟通方式。
这些技术的发展将得益于以下四个领域的发展:大数据、学习机制、知识图谱、推理和规划。
大数据。随着互联网的繁荣,数据量和种类都在高速增长。即便是非常传统的商业领域,都在开始把数据放到网上。一切都在网上进行,一切都在互联。大数据的价值将继续在物联网领域增长。
学习机制。学习机制的发展将会持续进行,这使得我们能从大数据中学习更多的东西。
知识图谱。通过大数据和更多强大的学习机制,我们可以打造更大的知识图谱,来对整个世界进行建模。
推理和规划。通过大型知识图谱,我们可以在推理和规划领域取得突破。推理和规划的能力将会把更多智能注入NLP系统中。
3、在NLP领域,中文和英文的主要区别是什么?
从语言学上来说, 中文与英文有很大不同。中文书面文本单词之间是没有空间的,中文的语法关系是通过单词的顺序来表达的。这些因素增加了中文在词汇、语法和语义层次上的模糊性,因为现代语言概念和原则更适用于英文,而非中文。
目前,主流NLP方法都是语言无关性(language-independent)的。这些统计学或神经网络算法,根据不同的应用,都更进一步优化了特定语言 。
比如,在2015年5月,百度发布了第一个大型在线神经机器翻译系统。基础的NMT模型就是语言无关的,并输出了非常好的翻译结果。为了进一步改善翻译性能,我们使用特定语言特征优化了翻译系统。
4、NLP技术如何应用于百度产品里?
在百度,我们开发出很多NLP技术,包括知识图谱、语义理解、内容标注、情感分析、生成、摘要、问答、机器翻译和对话系统等等。这些技术已经应用于许多百度的产品里,比如搜索、新闻流(news feed)和智能助理,每天为数亿用户服务。我们将以上这些技术通通整合进一个名为NLP Cloud的平台中。
NLP Cloud提供20多种NLP模块和方案,服务于百度产品。我们的NLP Cloud服务每天被调用1千多亿次。
以搜索为例,典型的NLP模块,比如切词、命名实体识别、语法分析、释义都是基本特征。这些模块一直在持续优化并取得突破。另一个典型的NLP技术应用案例就是问答系统。一个高性能的问答系统需要对查询语句进行精准的语义分析,构建覆盖面广的知识图谱,同时对网页搜索结果进行全面分析。当用户在搜索框输入查询语句时,搜索引擎能够立马提供答案。很多用户也使用搜索引擎来查询相关性高的信息,帮助做决策。这种情况下,情感分析(也称观点挖掘)技术可以帮助提取多种备选观点,并将聚合的信息提供给用户。
另一个案例就是新闻流,这个领域文章质量是极其重要的。NLP技术可以帮助检测各种垃圾文章,比如谣言、抄袭等等;而文本分析技术可以帮助识别高质量文章,并生成最能够描述该文章的标签。此外,从不同维度描述用户偏好的“用户模型”也十分依赖于NLP技术。
总而言之,在所有跟自然语言相关的产品里,NLP技术都是不可或缺的。
5、在未来10年,搜索引擎将会如何演变?
今天当我们谈及搜索引擎的时候,首先想到的就是搜索框和搜索结果。而未来的搜索引擎将会是什么样子呢?我们并没有确切答案。但是我们乐于拥有更强大的搜索引擎,让我们在不同的场景、不同的产品或不同的交互界面里,能够看见、听见和感受到。搜索,将会无处不在。
第一点,更深入理解用户的意图、更深入理解内容,并将两者更精准地进行匹配,这将会使搜索引擎更为强大。用户的意图理解并不是依赖于单一查询语句,也还依赖于更广泛的搜索语境,包括查询session、时间、地点、设备以及用户性格特征。另一方面,内容理解涉及的范围也非常广,需要更好地理解每一部分内容的语义、语境、观点,以及从内容中提取的知识。意图与内容的匹配,将会涉及到以上提到的所有因素,使得在任何一个特定语境下,为每一个查询提供最好的结果。此外,搜索引擎将会变得更像一个“回答引擎”和“执行引擎”。大部分用户的查询,将会得到直接的回答或执行。
第二点,搜索交互界面将会发生很多新变化。除了键盘以外,其它输入方式,比如声音和图像,将会越来越广泛地使用。伴随更实际的语音和图像等技术,用户会十分青睐高效和便利的多模式搜索。特别地,自然语言交互将会成为搜索引擎的主流交互方式。用户可以跟搜索引擎“对话”,告诉它自己想要什么,这绝对比现有的键盘输入文字查询要方便和自然的多。用户也可以跟搜索引擎进行多轮对话交互。百度搜索已经率先应用了这类新型交互方式,提升用户体验。
第三点,搜索将会超越现有的搜索引擎的范围。搜索会嵌入各种产品当中。比如,搜索会是AI硬件产品的基本特征之一。未来,搜索将会包围在我们身边,无处无在。相应地, 我们也将重新定义什么是可以被搜索的。除了现有的被索引的内容,在未来,服务、物品、设备和数据都可以被索引,变得可搜索。
很长时间以来,搜索引擎在人们日常生活中扮演至关重要的角色。人们的需求决定了搜索引擎演变的方向,而技术进步则决定了这种演变将走向多远。
附: 王海峰详解百度在NLP领域都做了什么?
2017年美国加州当地时间2月5日,人工智能顶级会议AAAI大会召开,AAAI今年首次设置了AI in Practice (应用人工智能)环节,百度副总裁王海峰应邀做了名为“百度的自然语言处理”(Natural Language Processing at Baidu)的主题演讲。AI科技评论根据王海峰现场演讲整理成本文。

大家好,我是来自百度公司的王海峰。在介绍百度NLP工作之前,我想先谈谈语言对于AI意味着什么。
思考和获得知识的能力成就了今天的人类,这种能力需要通过语言来找到思考的对象和方法,并外化为我们看、听、说和行动的能力。而语音、视觉、行为和语言等正是现在AI领域的重要研究内容。
相对于看、听和行动的能力,语言是人类区别于其他生物最重要的特征之一。语言是人类思考的载体,通常我们的思考语言是母语。当我们学习外语时,老师希望我们要努力使用外语来思考。另一方面,从人类历史之初,知识就以语言的形式进行记录和传承,用来书写语言的工具不断改进:从甲骨到纸张,再到今天的互联网。
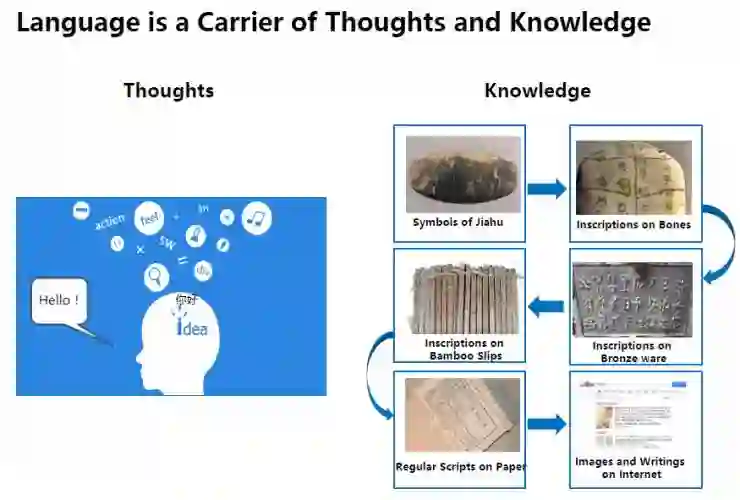
所以我们说,语言是思想和知识的载体,而对语言的处理和理解就显得尤为重要。计算机领域中自然语言处理(Natural Language Processing: NLP)的目的,就是让计算机能够理解和生成人类语言。
在百度,基于大数据、机器学习和语言学方面的积累,我们研发了知识图谱,我们分析理解query、篇章及情感,我们构建了问答、机器翻译和对话系统。NLP技术已经应用在百度的众多产品上,比如搜索、Feed、o2o和广告等。
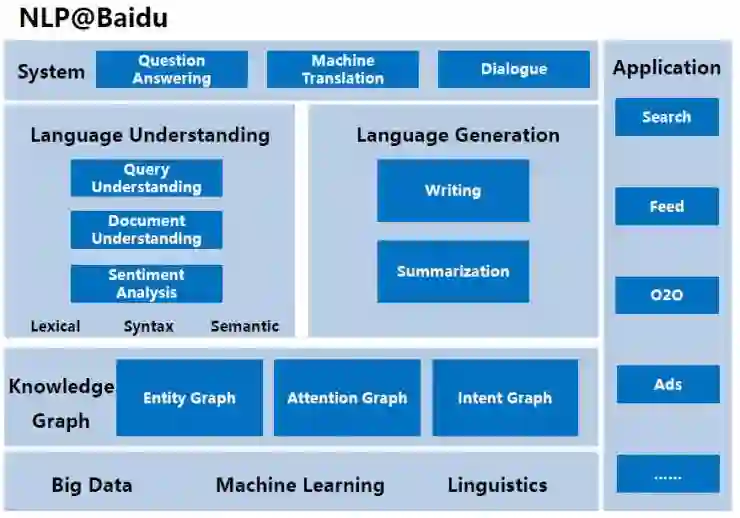
| 知识图谱
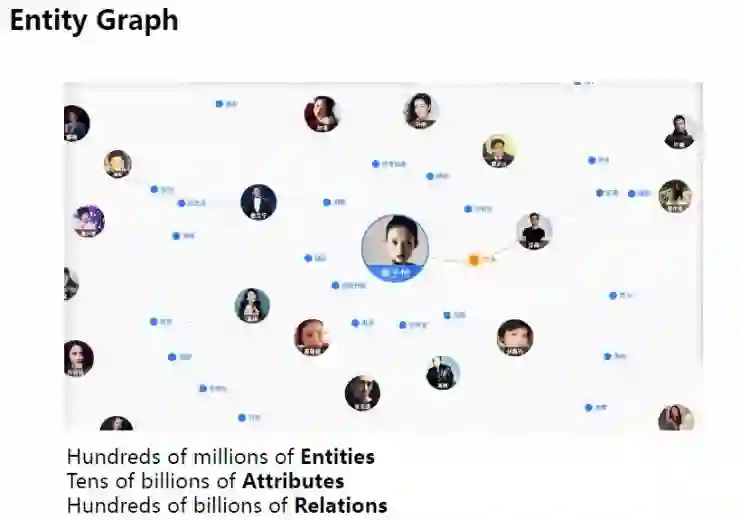
基于不同的应用需求,我们建立了三类知识图谱,包括实体图谱(entity graph)、关注点图谱(attention graph)和意图图谱(intent graph)。
在实体图谱里,每一个节点都是一个实体,每个节点都有几个属性,在这个例子中,节点之间的连接是实体之间的关系。目前我们的实体图谱已经包含了数亿实体、数百亿属性和千亿关系,这些都是从大量结构化和非结构化数据挖掘出来的。
这儿有一个例子,搜索的问题是:窦靖童的爸爸的前妻的前夫。
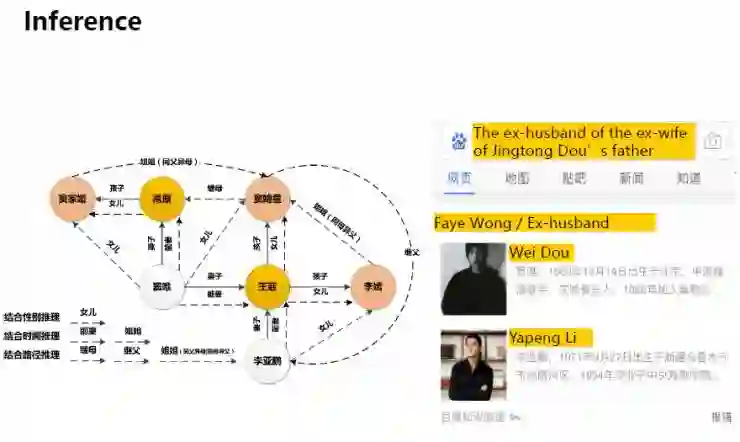
这句话里包含的人物关系是非常复杂的,然而,我们的推理系统可以轻松地分析出各实体之间的关系,并最终得出正确答案。
除了实体图谱之外,我们还建立了关注点图谱和意图图谱,稍后我在篇章理解和对话系统的部分将给大家介绍。
| 语言理解
Query理解
基于实体识别、语法和语义分析等技术,我们研发了query、篇章和观点分析和理解技术。接下来,我将进一步介绍query理解。我们结合“依存句法分析(Dependency Parsing)”和“语义理解(Semantic Understanding)”来实现query理解。
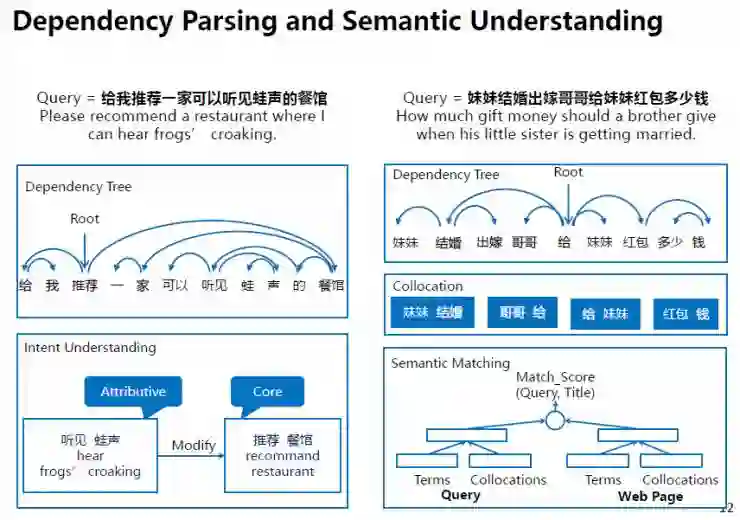
在上图所示例子里,左边用户输入的query是“给我推荐一家可以听见蛙声的餐馆”。我们使用了依存句法分析技术,来分析该语句的句法结构,帮我们找到句子里的各个组成成分。比如,“推荐、餐馆”是核心成分,表明了用户的主要意图,而“听见、蛙声”是修饰成分,对用户的意图进行了修饰和限定。
右边用户输入的query是“妹妹结婚出嫁哥哥给妹妹红包多少钱”,说明我们是如何提升query和网页之间的语义匹配(semantic matching)。首先,我们基于依存句法分析识别出这条query中的搭配,这种词语搭配相比于单个词语更能够准确表征query的语义,进而可以将其应用到query与网页的精确匹配中。
另外,基于语义理解技术,我们可以理解一个query的语义,实现语义级的搜索而不仅仅是字面匹配。

上图里前两句话是:
英达的儿子是谁
英达是谁的儿子
这两个句子里包含着相同的词语,只是词语的语序不同。如果使用传统的基于关键词的搜索技术,我们将会得到几乎相同的搜索结果。然而,经过语义理解技术的分析,我们可以发现这两个句子的语义是完全不一样的,相应地就能从知识图谱中检索到完全不同的答案。还有第三句话:
谁是英达的父亲
在字面上来看,这跟第二个句子并不一样,但是经过语义理解技术,我们发现这两个句子要找的是同一个对象,所以我们可以从知识图谱中检索到相同的答案。
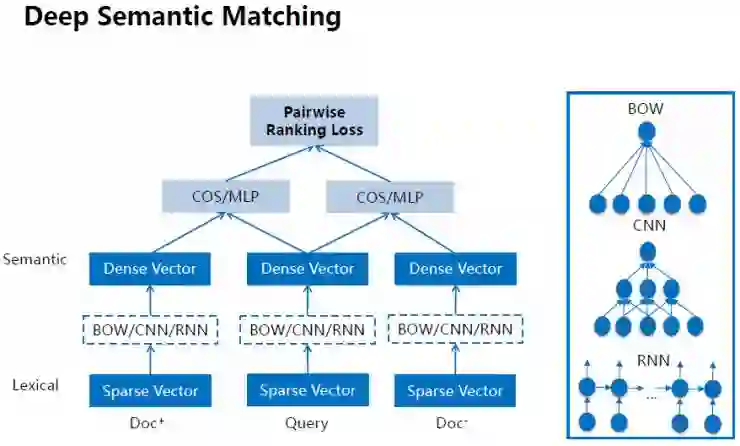
我们同样开发了基于深度学习的语义理解技术,实现了一个基于深度学习来计算query和文本语义关联。我们使用了超过1000亿的用户数据来训练模型,对于一个query,包括用户点击过的正例和未点击的负例。我们使用了BOW、CNN和RNN模型来学习语言的语义表示。为了提升模型对语义的表征,我们融合进多种句法和语义结构,将“依存关系结构”融合进模型中。
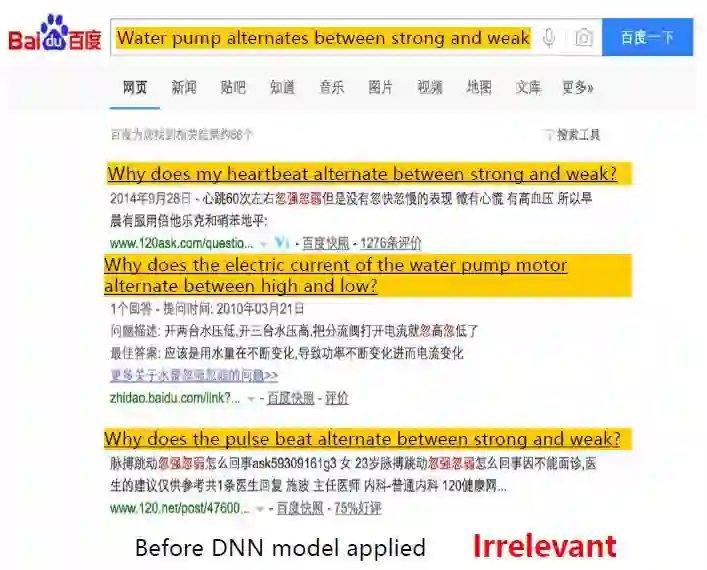
下图是在不应用深度学习模型时的搜索结果,结果是不相关的。
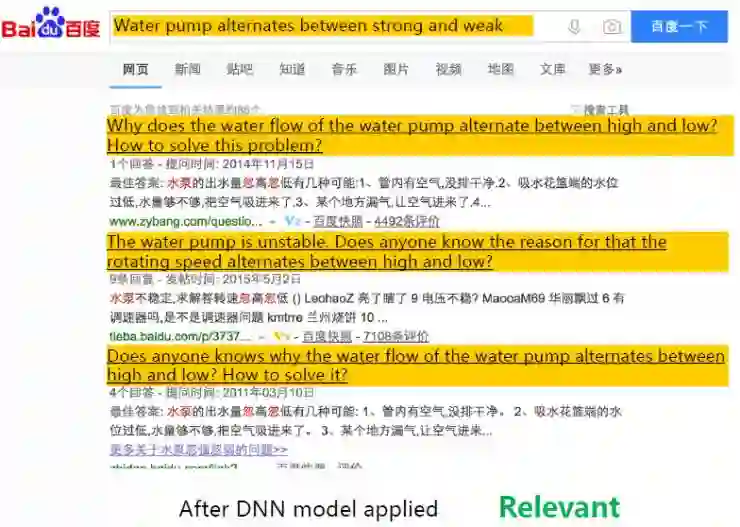
应用了深度学习模型之后,搜索结果里的前3个都是相关性的。从2013年开始应用DNN模型至今,我们已经对这个模型进行了几十次的升级迭代,DNN语义特征是百度搜索里非常重要的一个特征。
篇章理解
用户获取信息另一个重要渠道就是Feed,里面的资讯是个性化的,这其中,篇章理解技术发挥了重要作用。现在,我来为大家介绍一下我们在篇章理解方面的一些工作。
我们给文档打上各种各样的标签,包括:主题、话题和实体标签。主题标签表示抽象的概念,话题标签表示具体发生的事件,实体标签表示人、地点等实体信息。这些标签,从不同角度描述一个文档的内容,以满足不同应用需求,并与不同的query相关联。
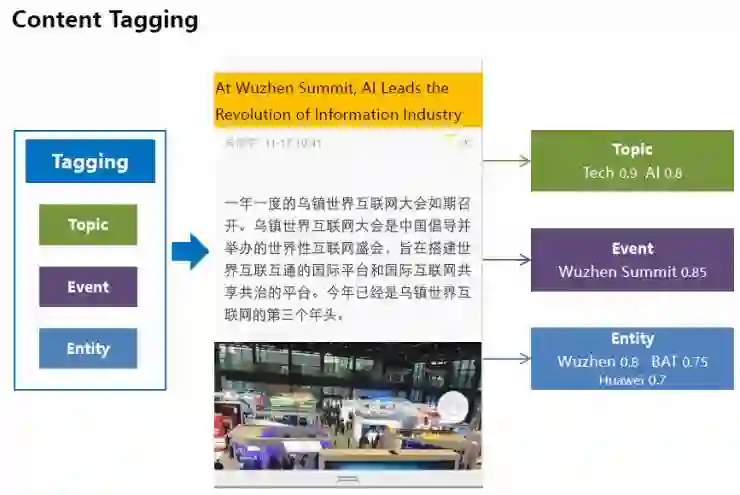
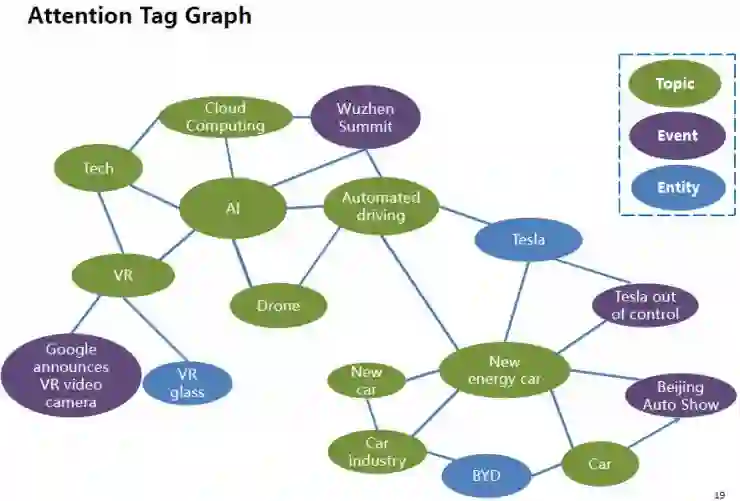
融合了话题标签和实体标签,我们形成了关注点标签图谱。这种关注点标签能更好地描述用户与文档之间的关系,因为它能同时对用户和文档进行表征。我们也在不同类型的关注点标签之间建立关系,这样我们可以对用户关注点进行推理和计算。在下图所示例子里,“AI”话题与“科技”、“VR”等话题及“乌镇峰会”等事件关联在一起。
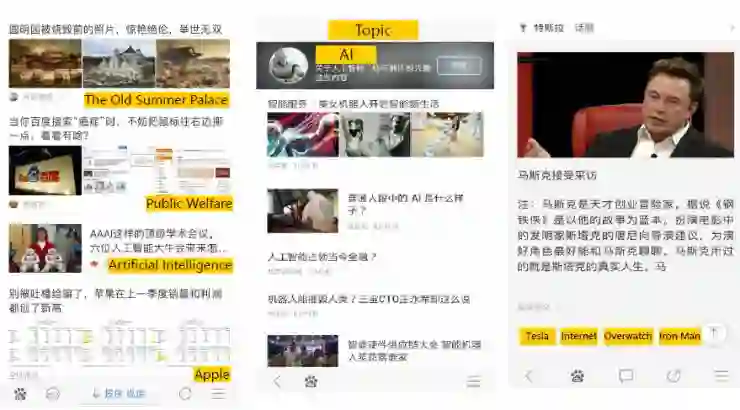
以下是关注点标签图谱应用在百度Feed里的一个例子,在左图中,标签表征了文章里的内容,用户可以点击标签进入到以一个话题为主题的聚合页(第二张图)。然后第三张图是基于关注点标签图谱进行个性化推荐,更能契合用户的关注点,带来了更高的点击率。
情感分析是篇章理解里另一个有趣的话题。情感分析技术也被称为“观点挖掘”(opinion mining),用来分析人类对各种对象(比如产品、组织机构等)的观点、情感和情绪。下面是我们在“观点挖掘”和“观点摘要”方面的一些工作。以“酒店评价”为例子,我们从已有的在线评论数据中抽取评论句,并进而从中提取用户观点。基于这些观点,我们可以生成标签级的观点摘要和句子级的观点摘要。我们也可以以此为基础来进行酒店推荐。
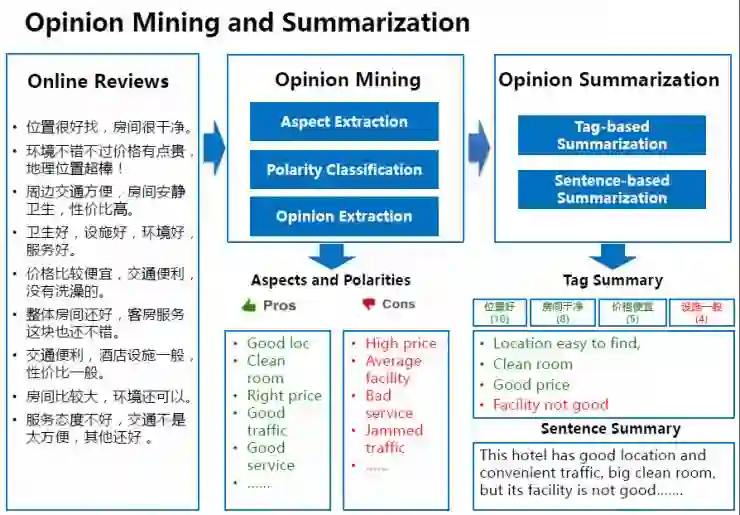
这里是一些关于情感分析应用于百度产品的例子,观点自动摘要技术为用户提供观点标签,在左边的例子里,我们提供了关于“八达岭长城”的多个维度的评价,在右边的例子里,我们在观点分析的基础上为用户提供了精炼的推荐理由。

| 语言生成
自动新闻写作
自动新闻写作,即从结构化和非结构化数据里生成新闻文章。这里面共涉及四个步骤:
数据分析(data analysis):确定要生成文章所需包含的关键信息
文章规划(document planning):确定生成文章的内容和结构
微观规划(micro-planning):生成单词、语句、段落和标题
文章实现(surface realization):生成最终的文章内容
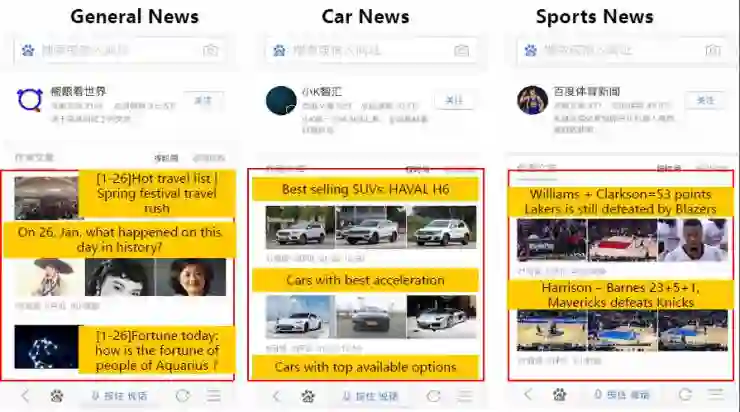
以下是我们自动写作的新闻。左边第一个例子,是一般的新闻,第二个是生成汽车领域的新闻,第三个是体育新闻,目前我们的自动写作系统已经完成了数千篇文章的写作,在百度Feed产品中得以被数百万的用户阅读。
AI 篮球解说员
我们的AI解说系统,可以像人类解说员一样,生成一场比赛的实时解说并与观众互动。这里面的实现主要包括四个步骤:
信息搜集(information gathering):从网上实时收集和提取比赛的关键信息
生成结构化数据(structured data generation):基于不同消息源的比赛信息,生成结构化解说数据
比赛场景推理(game scene inference):基于比赛数据(比如得分和统计),推断出现场比赛场景
生成直播解说(live commentary generation):基于解说模型,生成直播解说
以下是我们AI解说员生成的关于一场真实比赛的解说。
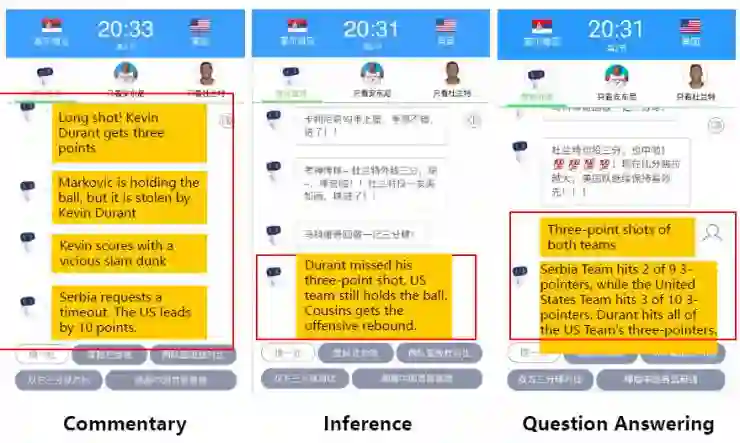
中间这个图,显示出这个AI解说员也可以进行推理,它在其中的一段解说中提到“考辛斯抢到了进攻篮板”,“进攻篮板”这个短语表明我们的AI解说员通过已有的知识了解到考辛斯所在球队目前处于进攻阶段,经过推理从而得出“进攻篮板”的结论。
最右边的例子,说明了我们的AI解说员除了解说,还可以同时回答多个观众的提问,而这是人类解说员所不能做到的。
诗歌生成
语言生成技术还可以应用在另一个方面:中国诗歌生成,而且文采并不比一般诗人差。中国诗歌有超过两千年的历史,是中国文化重要的组成部分,但对普通人来说,作诗还是很有难度的。
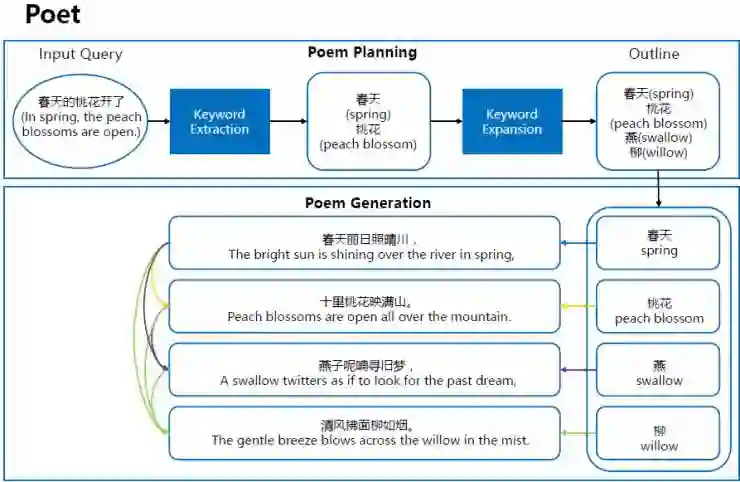
我们提出了两步生成中国诗歌的方法:首先对每一行诗的主题进行规划,然后进行具体诗句的生成。
举个例子,如果用户想要写一首和春天有关的诗,那么诗歌规划模型就会首先生成一个内容概要,包括春天,桃花,燕和柳这四个主题,然后由RNN模型根据这四个主题生成四句诗,来完成整首诗歌的创作。

文本摘要
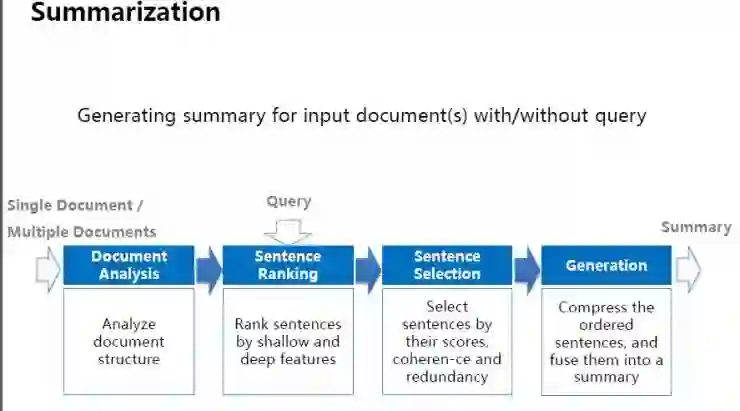
另外,我们还研发了文本摘要技术。具体来说,包括一般的文摘(general summarization)和基于query的文摘(query summarization)如下表中展示的具体过程:
文本分析(document analysis):分析文本结构
句子排序(sentence ranking):通过句子的表层含义和深层含义来实现对句子的排序
句子选择(sentence selection):从句子重要性、句子间是否连贯,以及去除冗余等角度来考虑如何选择文摘中的句子。
生成文摘(generation):把选定的句子进行压缩,并整合成最终的结果
一般文摘和基于query的文摘这两种技术的不同之处在于“句子排序”环节。在基于query的文摘里,我们对query的特征进行计算,以使得最终文摘体现出与query的相关性。
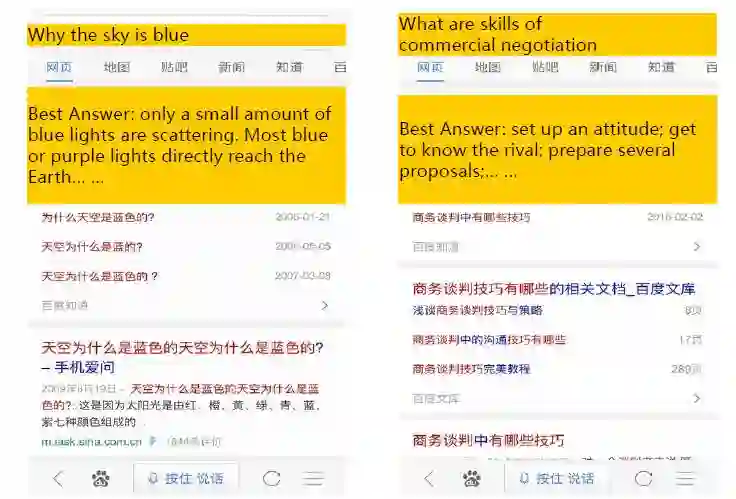
这里有两个文摘在搜索结果中体现的例子。左图显示,输入query“天空为什么是蓝的”,系统可以挑选出与这句话相关的网页,从中抽取出摘要并显示出来;右图中的例子也是同样道理。
| 自然语言处理应用系统
下面介绍三种自然语言处理的应用系统:问答、机器翻译和对话系统。
问答
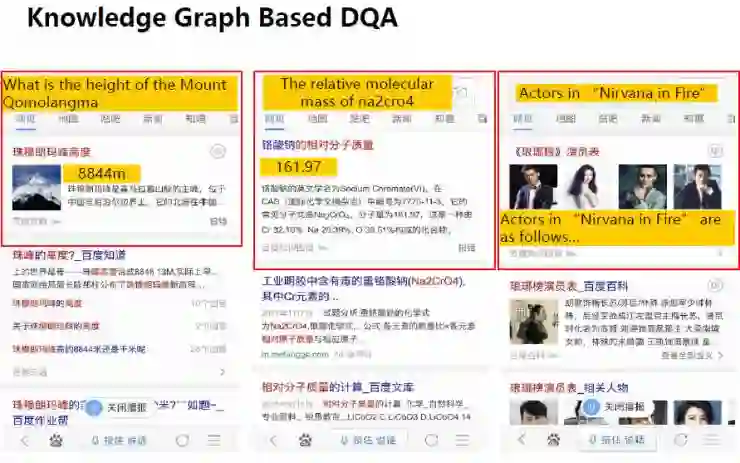
当用户在提出问题时,系统可基于知识图谱加以回答。
比如,当用户在搜索框内输入“珠穆朗玛峰高度”时,网页就会出现有关珠穆朗玛峰的图片和其高度说明;用户也可以输入“琅琊榜演员表”,那么百度搜索网页上就会直接出现《琅琊榜》的演员表及其照片。
除了基于知识图谱的问答,我们还设计了一种基于网络的深度问答系统。该系统对网页搜索结果中的内容进行分析,并识别用户问题中的关键词。然后系统会从网页中分析出和问题相关的文档,从中抽取出问题的答案,并展现在搜索结果页的最上方。
比如,用户可以搜索“糖尿病患者应该吃什么”,那么系统则会回答“饮食建议、饮食禁忌”等内容。这些信息来自于网上的医疗领域数据,经过信息挖掘和匹配,生成答案呈现在用户面前。

机器翻译
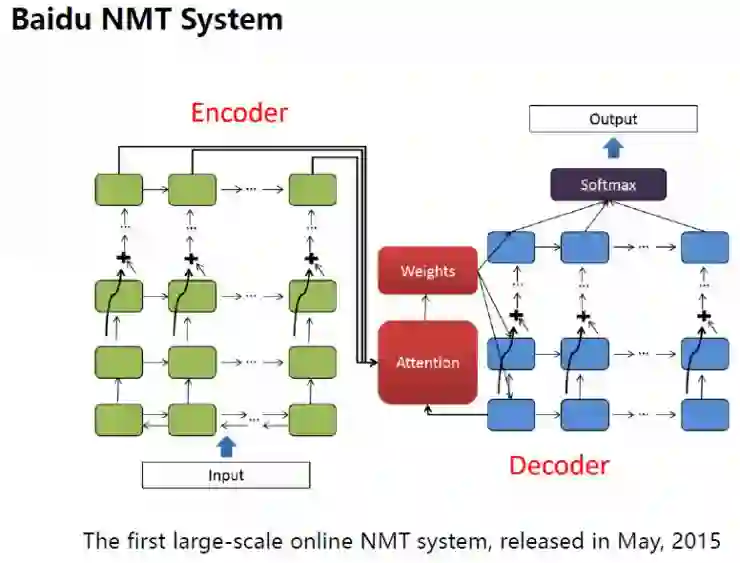
如今,基于神经网络的机器翻译十分火热,不过,传统的机器翻译方法仍有价值。所以,我们的系统结合了新旧四种方法:
神经网络机器翻译(neural MT)
基于规则的机器翻译(rule-based MT)
基于实例的机器翻译(example-based MT)
基于统计的机器翻译(statistical MT)
2015年5月,百度将神经网络机器翻译技术应用到百度在线翻译服务中,推出了全球首个基于深度学习的大规模在线翻译系统。同年,百度还在百度翻译app中上线了离线翻译功能,让用户在没有网络连接的情况下也可以使用翻译服务。
目前,百度翻译已可支持全球28国语言、756个翻译方向之间的互译,每日翻译次数达1亿以上。
不仅如此,我们还提供多样化的功能以满足用户的不同需求——除了文字翻译,百度翻译还能进行语音翻译以及利用OCR技术进行图片内容翻译。所以,以后到国外旅行就不用担心语言不通这个问题了。去餐馆吃饭时,只要用手机照一下菜单,立刻就能将其翻译成你所需要的语言。
同时,我们已经为超过2万个企业和开发者提供百度翻译API,让他们提升自己的产品功能,为用户提供更优质的服务。
另外,我们还把百度翻译和百度搜索引擎结合在一起——当用户在搜索框内输入外语时,百度搜索引擎会自动识别出翻译需求并将翻译结果显示在搜索结果最上方。
在2015年的ACL会议上上,百度的智能机器人“小度”还担任了ACL终身成就奖获得者李生教授的同声传译。在问答环节,小度将现场观众提问的英文问题立刻翻译成中文,然后将李教授的中文回答翻译成英文呈现给观众。现场观众(大部分是自然语言处理方面的专家学者)对小度的表现大为赞叹,并对机器翻译目前的成就感到欣喜。

对话系统
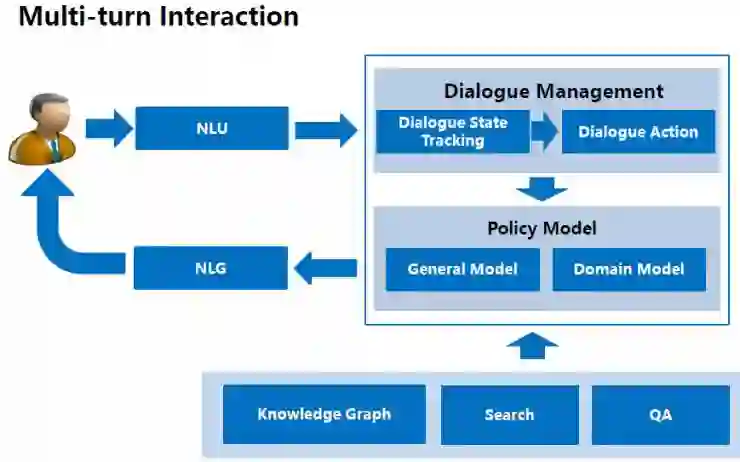
接下来,我会介绍百度的对话系统。该对话系统能与用户进行多轮交互(multi-turn interaction)。首先,用户的输入经过自然语言理解(NLU)模块,进入对话管理系统。该系统识别出当前的对话状态(dialogue state),并确定下一步的对话行为(dialogue action)。我们的对话策略( policy) 模块,包含通用模型和领域模型,即前者负责处理通用的交互逻辑,后者则处理特定领域的交互逻辑。最后,该系统会为用户生成交互回复。
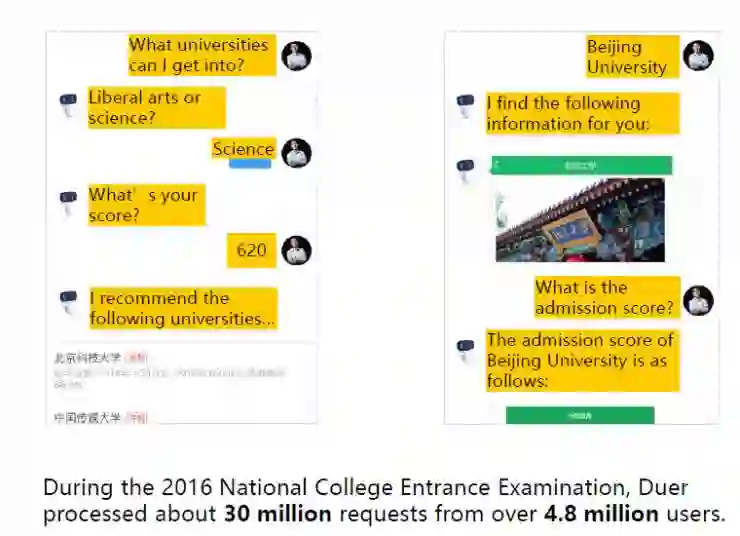
这里有一个例子,是高考之后,百度智能助理“度秘”和用户之间的对话。当用户问:“我能进入哪所大学?”度秘会反问他问题,以进一步了解情况。度秘问:“你是文科还是理科?”对方回答:“理科”。度秘接着问:“你考了多少分?”他回答:“620 分。” 度秘随即根据这些信息,推荐适合他填报志愿的学校。在 2016 年的全国高考期间,度秘处理了480 万百用户的 3000万个请求。
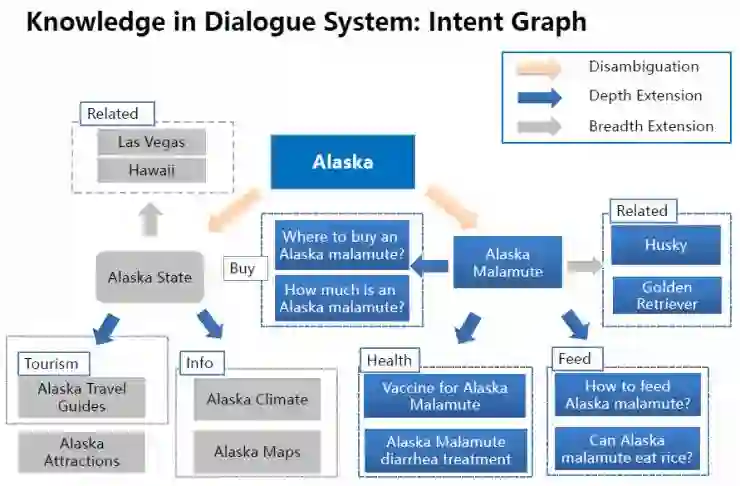
接下来我要谈一谈我们的意图图谱技术。与我之前讲过的实体图谱不同,意图图谱的节点代表一个个意图节点。这些“意图”之间的关系包括需求澄清(disambiguation)、需求细化(depth extension)、需求横向延展(breadth extension )等。在下图所示例子中,当“阿拉斯加”的意思是“阿拉斯加州”时,与之关联的意图是城市、旅游等信息。当“阿拉斯加”的含义是“阿拉斯加犬”时,它延伸的意图是宠物狗、宠物狗护理,以及如何喂食等。
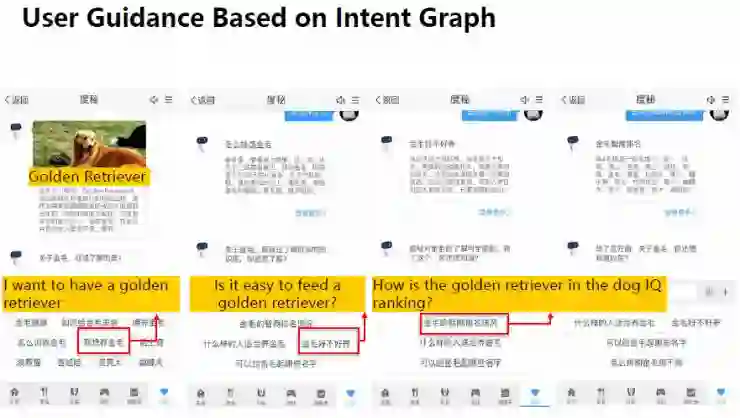
这样的意图图谱可用于人机对话系统当中,下面让我们来看一个度秘基于意图图谱的用户引导例子。
用户想要查询关于“金毛”的信息,基于意图图谱,度秘提供给用户关于金毛的一般信息;接着进入第二轮,用户点击了“我想要一只金毛”的选项,度秘便可以猜测用户接下来会想要知道“如何喂养一只金毛”、“什么样的人适合养此类犬”等信息,并将这些引导项展现给用户。然后用户点击了“喂养一只金毛容易吗”的选项。对话进行到此轮,用户的需求基本被满足了。
以上,我介绍了百度在NLP领域的诸多工作,包括知识图谱、语言理解、语言生成和几个应用系统(包括问答、机器翻译和对话),我们已经将这些技术应用在百度的产品当中,另外我们也通过平台化的方式对更多产品进行支持,比如我们开发的NLPC(NLP Cloud)平台,现在已经可以提供20多种NLP模块,每天被调用超过1000亿次。
最后我想说的是,我们今天在NLP领域里的探索和追求,将会对我们逐步实现人类的人工智能梦想产生至关重要的影响。谢谢大家。
AI科技评论招聘季全新启动!
很多读者在思考,“我和AI科技评论的距离在哪里?”,答案就是:一封求职信。
AI科技评论自创立以来,围绕学界和业界鳌头,一直为读者提供专业的AI学界,业界,开发者内容报道。我们与学术界一流专家保持密切联系,获得第一手学术进展;我们深入巨头公司AI实验室,洞悉最新产业变化;我们覆盖A类国际学术会议,发现和推动学术界和产业界的不断融合。
而你只要加入我们,就有机会和我们一起记录这个风起云涌的人工智能时代!
如果你有下面任何两项,请投简历给我们:
*英语好,看论文毫无压力
*计算机科学或者数学相关专业毕业,好钻研
*新闻媒体相关专业,好社交
*态度好,学习能力强
简历投递:lizongren@leiphone.com







