让计算机拥有一双眼睛,人工智能科学家已经努力了半个世纪

来源:科技行者
概要:计算机算法可以从面相判断一个人的性取向,引发了对隐私、道德、伦理问题的争议。然而回过头去看,在人工智能领域,它是图像识别和机器人视觉的核心部分。
最近斯坦福大学一篇论文《Deep neural networks are more accurate than humans at detecting sexual orientation from facial images》一出,舆论哗然,该论文研究指出,计算机算法可以从面相判断一个人的性取向,引发了对隐私、道德、伦理问题的争议。然而回过头去看,这原本是一个卷积神经网络应用的技术文章,在人工智能领域,它是图像识别和机器人视觉的核心部分。
图像识别技术,是人工智能道路上的一座高峰,如今你可以看到包括个人相册图片管理、刷脸解锁手机、刷脸上班打卡等广泛应用。你一定好奇,图像识别是什么?如何让机器理解一张图甚至一个动态的生物?背后又用到了哪些技术?
今天,我们就从源头挖一挖图像识别的概念、技术和应用。
什么是“图像识别”?
从概念来看,图像识别是指利用计算机对图像进行处理、分析和理解,以识别不同模式的目标和对像(人物、场景、位置、物体、动作等)的技术。
而图像识别算法一般采用机器学习方法,模拟人脑看图,随后计算机依靠大量的数据,理解图像,最后建立相关的标签和类别。整个识别过程的核心,就是神经网络,经过优胜劣汰,目前已经发展到卷积神经网络(CNN或ConvNets)。
据不完全统计,科学家们从神经网络研究到卷积神经网络,就花了从20世纪60年代末到20世纪80年代末的时间。
让计算机看见,经历了一个剥茧抽丝的神经网络演进过程
我们先来看,人如何辨识物体。人脑的神经细胞(神经元)包括很多彼此相邻并相连的层,层数越多,网络越“深”。单个神经元从其他神经元接收信号——可能高达10万个,当其他神经元被触发时,它们会对相连的神经元施加兴奋或抑制作用,如果我们的第一个神经元输入加起来达到一定阈值电压(threshold voltage)时,它也会被触发。
也就是说,人不但可以用眼看字,当别人在他背上写字时,他也认得出这个字来。就好比下图,人一眼看过去,就能感知到图片中存在某种层级(hierarchy)或者概念结构(conceptual structure),一层一层的:
地面是由草和水泥组成,图中有一个小孩,小孩在骑弹簧木马,弹簧木马在草地上。

关键点是,我们知道这是小孩,无论小孩在哪种环境都认识,因此人类不需要重新学习小孩这个概念。
但机器不同,它需要经过多次反复的学习过程。我们再来看,机器如何辨识物体。在人工神经网络中,信号也在“神经元”之间传播,但是,神经网络不是发射电信号,而是为各种神经元分配权重。 和权重较小的神经元相比,权重更大的神经元会对下一层神经元产生更多的作用,最后一层将这些加权输入放在一起,以得出答案。
比如,要想让一个计算机认出“猫”,需要建立一组数据库,包含数千张猫的图像和数千张不含猫的图像,分别标记“猫”和“不是猫”,然后,将图像数据提供给神经网络,最终输出层将所有信息——尖耳朵、圆脸、胡须、黑鼻子、长尾巴——放在一起,并给出一个答案:猫。这种训练技术被称为监督学习(supervised learning)。
还有一种技术叫做无监督学习(Unsupervised learning),就是使用未标记的数据,计算机必须自己看图识物,比如从“尖耳朵”辨别这是一只猫而不是其他动物。然而这些方法容易误导机器,误把“尖耳朵”猫识别成狗,或者把浣熊猫误认为暹罗猫。
但是,如果图片是这样的呢?

一个3 岁小孩都能识别出猫的照片,计算机科学家们却花了多年时间教会计算机看图识物。关键就是自主训练量。
直到20世纪80年代,来自加拿大多伦多大学的“神经网络先驱”Geoff Hinton领导的小组,提出了一种训练神经网络的方法,叫做卷积神经网络,意味着它不会陷入局部陷阱。
于是强大的图形处理单元或GPU出现了,研究人员因此可以在台式机上运行、操纵和处理图像,而不用超级计算机了。
同时大数据的加持,让卷积神经网络应用越来越广泛。2007年,美国斯坦福大学计算机科学系副教授李飞飞推出了ImageNet——一个来自互联网的数百万带有标签图像的数据库。ImageNet为神经网络提供了约1000万张图像和1000个不同的标签。
一直到现在,神经网络成为机器人视觉的核心工具。尽管现代神经网络包含许多层次——Google Photos有大约30层——但卷积神经网络的出现,仍然是前进了一大步。
当你教会计算机认图,它需要反复学习
与传统神经网络一样,卷积神经网络也是由加权神经元层组成。但是,它们不仅仅是模仿人脑的运作,而是非常恰到好处地从视觉系统本身获得了灵感。
卷积神经网络中的每个层,都在图像上使用过滤器拾取特定的图案或特征。前几层检测到较大的特征,例如下图斜线,而后面的层拾取更细的细节,并将其组织成诸如“耳朵”的复杂特征。
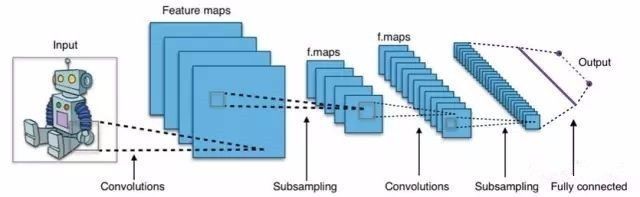
图:典型的卷积神经网络架构
最终输出层像普通神经网络一样是完全连接的(也就是说,该层中的所有神经元都连接到上一层的所有神经元)。它集合高度具体的特征——其中可能包括猫的狭缝状瞳孔、杏仁形眼睛、眼睛到鼻子的距离——并产生超精确的分类:猫。
在2012年,谷歌用数千个未标记的YouTube剪辑缩略图培训了一个卷积神经网络,看看会出现什么。毫不奇怪,它变得擅长寻找猫视频。
卷积神经网络如何进行图片处理?基本上有三个步骤,卷积层、池化层、采用下采样阵列作为常规全连接神经网络的输入。
譬如,从刚刚那张“小孩骑马图”可以分解出,卷积神经网络辨识物体的五个步骤:
第一步:把图片分解成部分重合的小图块

于是图片被分解成了 77 块同样大小的小图块。
第二步:把每个小图块输入到小型神经网络中
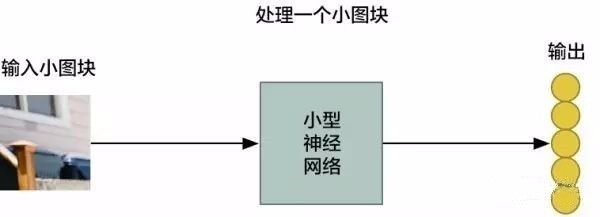
重复这个步骤 77 次,每次判断一张小图块
然而,有一个非常重要的不同:对于每个小图块,我们会使用同样的神经网络权重,也就是说,如果哪个小图块不一样,我们就认为这个图块是“异常”(interesting)的。
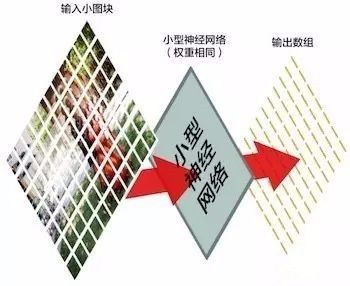
第三步:把每一个小图块的结果都保存到一个新的数组当中
我们不想并不想打乱小图块的顺序,所以就把每个小图块按照图片上的顺序输入并保存结果,就像这样:
第四步:缩减像素采样
第三步的结果是一个数组,这个数组对应着原始图片中最异常的部分。但是这个数组依然很大:

为了减小这个数组的大小,我们利用一种叫做最大池化(max pooling)的函数来降采样(downsample)。但这依然不够!
让我们先来看每个 2×2 的方阵数组,并且留下最大的数:
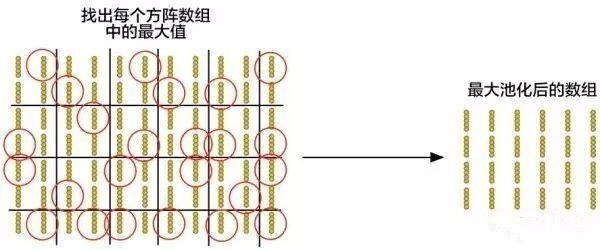
这里,一旦我们找到组成 2×2 方阵的 4 个输入中任何异常的部分,但我们就只保留这一个数。这样一来我们的数组大小就缩减了,同时最重要的部分也保留住了。
最后一步:作出预测
到现在为止,我们已经把一个很大的图片缩减到了一个相对较小的数组。
数组就是一串数字而已,所以我们我们可以把这个数组输入到另外一个神经网络里面去。最后的这个神经网络会决定这个图片是否匹配。为了区分它和卷积的不同,我们把它称作“全连接”网络(“Fully Connected” Network)。
所以从开始到结束,我们的五步就像管道一样被连接了起来:
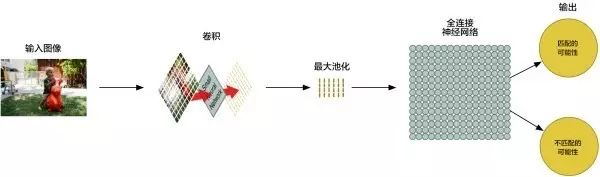
整个过程中,你可以把这些步骤任意组合、堆叠多次,卷积层越多,网络就越能识别出复杂的特征。当你想要缩小数据大小时,也随时可以调用最大池化函数。而深层卷积网络(Convolutional Neural Networks)就是使用了多次卷积、最大池化和多个全连接层。为了实现卷积神经网络应用,机器学习需要反复学习测试。
如何构建卷积神经网络?这里有一些API
从零开始构建卷积神经网络,费钱又耗时,业内开放了一些API(Application Programming Interface,应用程序编程接口),使开发者无需自己研究机器学习或计算机视觉专业知识。
谷歌 Cloud Vision
GoogleCloud Vision是谷歌的视觉识别API,使用REST API。它基于开源的TensorFlow框架。它检测单个面部和物体,并包含一个相当全面的标签集。
另外,谷歌图像搜索可以说是一个巨大的图像数据库,基本上改变了我们处理图像的方式。
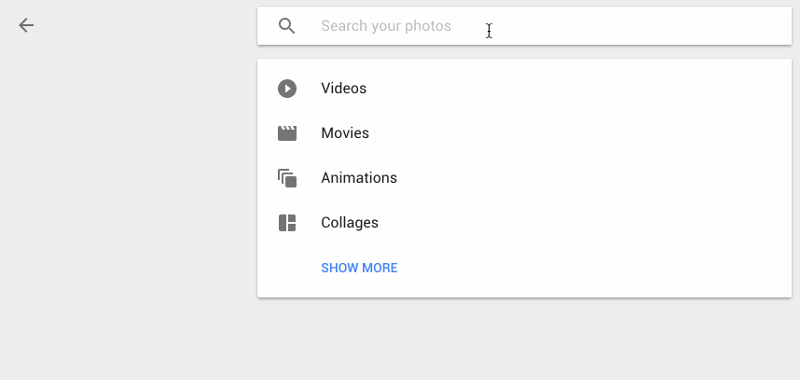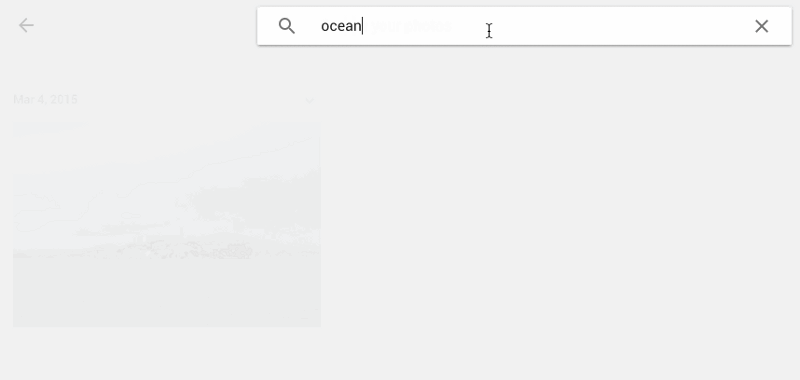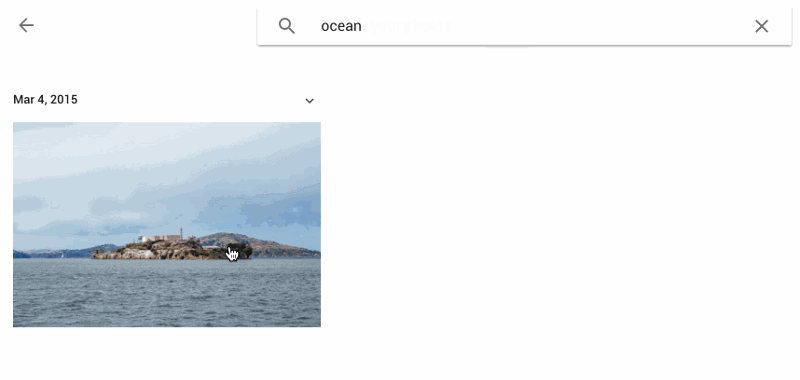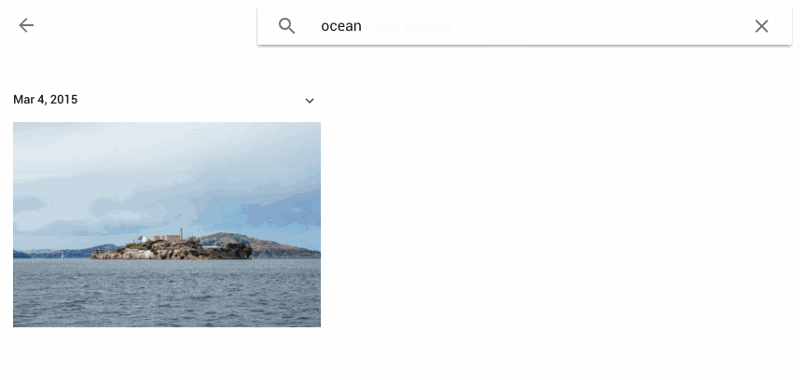
这里有一张谷歌图像搜索的时间表。
IBM沃森视觉识别
IBM沃森视觉识别是沃森开发者云(Watson Developer Cloud)的一部分,并附带了一大批内置的类别,但实际上是为根据你提供的图像来训练自定义定制类而构建的。它还支持一些很棒的功能,包括NSFW和OCR检测,如Google Cloud Vision。
Facebook的MultiPathNet 3
Facebook AI Research(FAIR)认为,深度卷积神经网络让我们已经看到图像分类(图像中有什么)以及对象检测(对象在哪里?)上的巨大进步(见下图a和b),但这只是一个开始,目标是设计一种识别和分割图像中每个对象的技术,如下图c。
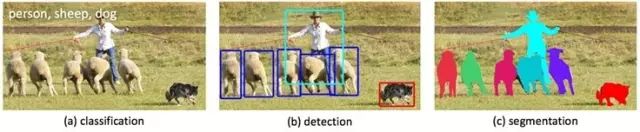
于是Facebook想将机器视觉推向下一个阶段——在像素级别上理解图像和对象。推动的主要新算法是DeepMask 1分段框架以及SharpMask 2细分模块。它们共同使FAIR的机器视觉系统,能够检测并精确地描绘图像中的每个物体。识别流水线的最后阶段使用一个专门的卷积网络,称之为MultiPathNet 3,以其包含的对象类型(例如人,狗,羊),为每个对象掩码标记。
Clarif.ai
Clarif.ai是一个新兴的图像识别服务,也使用REST API。关于Clarif.ai的一个有趣的方面是它附带了一些模块,有助于将其算法定制到特定主题,如食物、旅行和婚礼。
尽管上述API适用于少数一般应用程序,但你可能仍然需要为特定任务开发自定义解决方案。幸运的是,许多库可以通过处理优化和计算方面来使开发人员和数据科学家的生活变得更加容易,从而使他们专注于训练模型。有许多库,包括Theano、Torch、DeepLearning4J和TensorFlow已经成功应用于各种应用。
-END-




