你听不出是AI在唱歌!这个日本虚拟歌姬,横扫中英日三种语言
郭一璞 晓查 乾明 发自 凹非寺
量子位 出品 | 公众号 QbitAI
在今天的内容开始之前,大家可以先戳下面的声音听一下,不长,只有18秒,是一个妹子在唱Adele的知名歌曲Rolling in the Deep。
有熟悉二次元世界的盆友可能听出来了,这段歌声听起来像佐藤莎莎拉,她是声音编辑软件CeVIO开发的虚拟歌姬。

不过,莎莎拉本尊的声音似乎听起来更“电子”一些,而上面这段Rolling in the Deep听起来就好像是一个声音和莎莎拉一样的真人唱的。
并不。
事实上,这是日本语音合成技术的最新突破,只要时长2小时的某歌手的歌声数据,通过深度学习技术,就可以合成出跟这个人一模一样的歌声。
如此真实的莎莎拉声音,让微博上的二次元粉丝惊呼:我的老婆要重生了!


甚至还有人已经预料到了,这将颠覆鬼畜圈。

嗯,以后B站UP主们就可以让丞相非常自然的唱骂王司徒了。

而在音乐界,这个新技术能让我们欣赏更多不同的歌曲。
举个例子,只要让AI听林俊杰的三张专辑,AI就可以用林俊杰的声音,唱出周杰伦、五月天、孙燕姿他们的任何一首歌。
并且,你会完全听不出电子合成的痕迹。

那下面,我们来欣赏一下这个AI在唱日文、英文、中文歌的不同表现吧:
日文版
前后分别是《Diamonds》和《瞳》两首歌,你可以依次听到每首歌带伴奏的完整版、清唱版和以前的技术生成的旧版本。
可以清晰的听出来,新技术生成的版本几乎和真人唱歌一模一样,完全没有旧版本那种浓浓的电子音。
英文版
英文歌则是《Rolling In The Deep》和《Everytime》两首,三个版本的顺序和上面的日文版相同。
英文版的清唱已经听起来跟正常人类唱歌没什么区别了,带上伴奏会有一丝丝违和,但单词的发音已经比旧技术的版本清晰多了。
不过,如果你仔细听了带伴奏的版本,会发现相比日文歌,这个AI在唱英文歌的时候还是有一丝丝电音的感觉。
中文版
终于到中文歌了,中文歌是陈奕迅的《爱情转移》。
这位AI唱中文歌的特点,就是一个字一个字的蹦,可能日本人民就是这么学中文的吧。
不过,仔细听还是可以听出它的潜质的,至少“让上次犯的错反省出梦想”最后一个字“想”,这个长音还是足够婉转的。
后一句“做爱情代罪的羔羊”,简直沙哑出了真人的感觉,看来AI已经了解到,这种突然变高的声音,普通人类是唱不上去的。
看来,要想学得像,也要学人类缺点啊,至少比旧技术那种强行飙高音的假唱听着舒服多了。
这背后是谁?
开发CeVIO的Techno Speech是一家的是由名古屋工业大学投资的创业公司,成立于2009年11月,主要业务是向外界提供计算机多媒体软硬件。
除了在资本层面,这家公司也和学校有着千丝万缕的联系,Techno Speech成立的目的正是传播名古屋工业大学开发的世界上最先进的音频相关技术。
名古屋工业大学语音技术研究室的德田惠一教授主导开发了以上项目,而从他实验室走出的大浦圭一郎博士正是Techno Speech的代理董事。

△Techno Speech社长 大浦圭一郎
这次合成的声音用的是Techno Speech的CeVIO语音合成软件。
除此之外,这家公司还开发了其他一些知名的产品。
Techno Speech和日本卡拉OK公司Joysound合作,希望AI不仅能学会唱歌,将来还能教会人类唱歌。它不同于一般的开原唱声,而是实时合成语言,目前已经支持几乎所有日文歌曲。

大名鼎鼎的软银Pepper机器人也用上了他们的技术,他们曾获得过2017年“健康王国 for Pepper”机器人应用挑战赛大奖。

Pepper机器人装上他们的应用程序后,可以实现机器与人合唱,还能在唱完歌后给进行评论。
Techno Speech希望用这项技术解决养老院的娱乐设施问题。
使用了什么技术?
这一进步背后的技术细节,名古屋工业大学的研究团队没有透露,但表示明年3月,德田惠一团队将会在的日本声学学会春季会议上发布研究成果。
不过,在接受数码音乐网站DTM Station采访时,德田惠一也透露了一些细节:这个系统使用的是深度神经网络技术(DNN)。

△德田惠一教授
在德田惠一自己的主页上,有很多语音合成的论文记录。最近也有一篇,刚好跟DNN有关。

在提到与日本版微软小冰“玲奈”的对比时,德田惠一称,微软的“玲奈”是从“歌词和歌声”到“歌声”,采用的是应对模拟用户的唱歌方法,而他们的这个,完全是歌词和乐谱结合来合成歌声。
此外,据介绍这项技术未来可以运用到下面8个领域:
复现歌星的歌声(包括死者的声音)
音乐制作和游戏开发
由虚拟YouTubers主持的视频流/直播
虚拟演员后期录制系统
AI或语音对话系统的发声模块
生成灵活的参考语音,用于外语学习或歌唱教育
为ALS(渐冻人症)或喉癌患者制作语音设备
制作护理设施的数字标牌
专家解读“AI合成歌声”
关于这件事,量子位也请教了一些业内专家大神。
小冰首席语音科学家栾剑说,他听了CeVIO的演唱版本,日文和英文上的发音还不错,比较亲切,但更关注的是训练时间。
栾剑也看了CeVIO在B站的案例,不过觉得可能不是2小时的训练成果。一般来说,数据量越小,出高质量合成的难度越大。
今年,小冰六代发布会上,微软发布了一个4小时训练后的模型,当时效果反响不错。

但这位小冰首席语音科学家也强调,对于唱歌的评价更偏主观,不同人有不同的评价,所以评价标准并不统一。
如果以如何把人类的情感模拟到极致来看,栾剑则认为技术挑战在情感。
“唱歌跟说话不同,对情感表达的要求非常高,嗓音、气息都会影响到最后的效果,所以如何更具情感是唱歌合成的难点。”
除了小冰,AI语音公司思必驰去年也在央视《机智过人》节目中亮相过AI唱歌项目。
思必驰联合创始人、首席科学家俞凯当时对AI合成歌声系统有过解读。
歌声合成是语音合成领域的一个分支,是给定文字和乐谱,生成唱歌语音的过程。
主体方法是在文字到语音合成的基础上,通过乐谱给定每个“汉字”的音调和“汉字”的发音长短,汉字以不同的音调合成出来就变成了歌唱。

唱歌模型是在朗读模型的基础上,通过改变声调实现文字与旋律的配合,并进一步利用深度学习去学习同一说话人演唱歌曲和朗读歌词之间频谱特征的差异。
标贝科技CTO李秀林告诉量子位,就目前的发展状况来看,AI合成歌声还有一些挑战。
这位TTS领域的大牛,曾是百度T9,因语音合成拿到百度年度最高奖,后来在滴滴任职语音团队负责人,在语音合成领域履历赫赫。

李秀林认为挑战有两点:
一方面是音域的限制,每个歌手都有适合自己的音域范围,如果超出范围的歌曲,合成效果可能会受到一定的影响。
另外,训练数据的限制,会影响基于神经网络的模型效果。
但新系统的效果与之前相比,有了很明显提升,机器声的感觉大幅下降,更接近真人的嗓音。
One More Thing
目前,国内AI唱歌最知名的还是微软小冰。
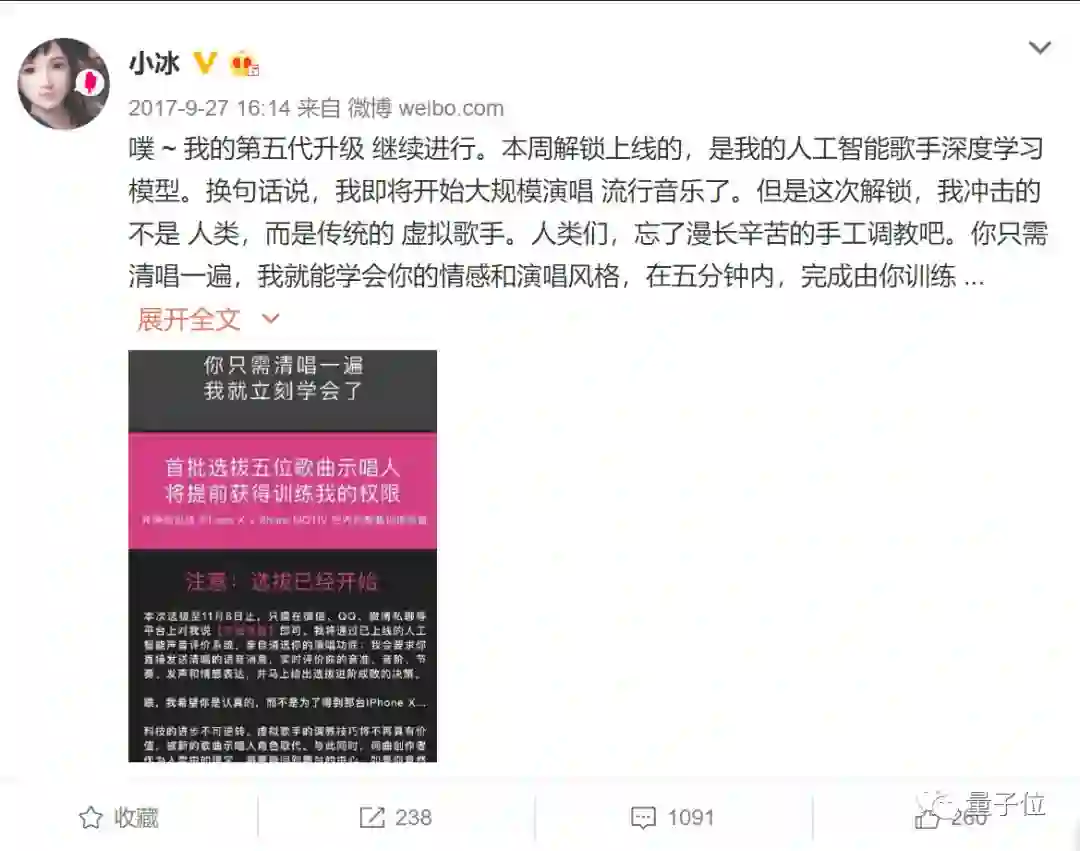
自2016年小冰以歌手身份出道以来,已发布了十几首接近人类质量的单曲。2017年9月底,第五代小冰解锁了人工智能歌手深度学习模型,还放下狠话:
我冲击的不是人类,而是传统的虚拟歌手。人类们,忘了漫长辛苦的手工调教吧。
一时反响激烈。
这一次,各方评论也纷纷提到了微软小冰。
不过小冰首席语音科学家栾剑也说,因为CeVIO没出中文版,所以跟最新的小冰六代还难以直接比拼。
但小冰团队对自家“女儿”非常自信,他们更希望让小冰直接唱给大家听。
因为公众号图文视频数量的限制,无法在此呈现了。
在量子位公众号对话界面回复“小冰唱歌”,给你听4小时训练后小冰六代的歌声。
— 完 —
活动报名

加入社群
量子位AI社群开始招募啦,欢迎对AI感兴趣的同学,在量子位公众号(QbitAI)对话界面回复关键字“交流群”,获取入群方式;
此外,量子位专业细分群(自动驾驶、CV、NLP、机器学习等)正在招募,面向正在从事相关领域的工程师及研究人员。
进专业群请在量子位公众号(QbitAI)对话界面回复关键字“专业群”,获取入群方式。(专业群审核较严,敬请谅解)
诚挚招聘
量子位正在招募编辑/记者,工作地点在北京中关村。期待有才气、有热情的同学加入我们!相关细节,请在量子位公众号(QbitAI)对话界面,回复“招聘”两个字。

量子位 QbitAI · 头条号签约作者
վ'ᴗ' ի 追踪AI技术和产品新动态




