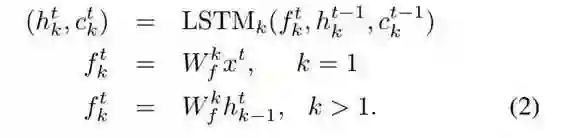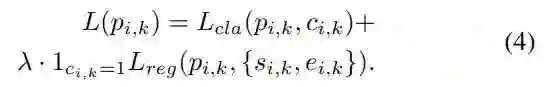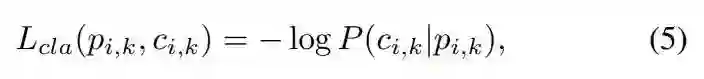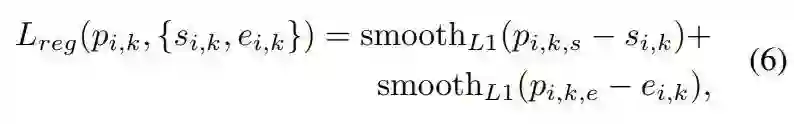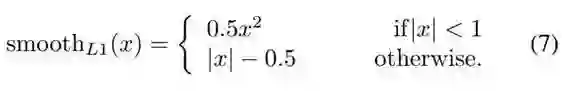选自arXiv
作者:Fan Yang等
机器之心编译
参与:Panda、杜伟
这是短视频盛行的时代。很多播主或 up 主生产内容的过程都是先从一段长视频截取所需的部分,再进行加工和编辑。近日百度等的 ICCV 论文提出了一种有望简化这一流程的 AI 方法,能自动帮助用户定位和截取视频中完整故事片段的起止位置。此外,他们还创建了一个供这类方法学习的数据集。
这篇论文引入了一个新问题,研究者将其称为「保留故事型长视频裁剪(story-preserving long video truncation)」,这需要算法将持续时间长的视频自动裁剪为多段有吸引力的短视频,而且其中每段短视频都包含一个不间断的故事。
论文链接:https://arxiv.org/pdf/1910.05899v1.pdf
这不同于传统的视频亮点检测或视频摘要问题,其中每段短视频都需要维持一个连贯且完整的故事,对于 YouTube、Facebook、抖音、快手等资源生产型视频分享平台而言,这种功能尤其重要。
为了解决这个问题,研究者收集并标注了一个新的大型视频裁剪数据集 TruNet,其中包含 1470 段视频,每段视频平均有 11 段短视频。
下图 1(a) 展示了 TruNet 中的一段示例视频。这段视频是一场综艺节目,其中包含 9 个歌唱和舞蹈节目。这 9 个短故事表示成了不同的颜色。图 1(b) 用更高的时间分辨率(temporal resolution)展示了第 3 个节目。
![]()
图 1:
TruNet 中每段长视频平均包含 11 段短视频。
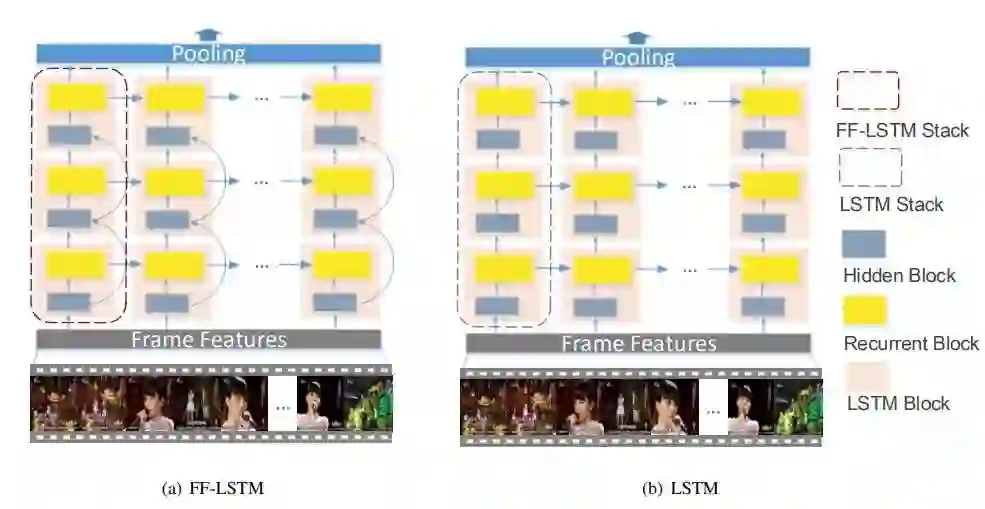
研究者不仅构建了这个新的数据集,还用它训练了一个视频裁剪神经网络架构,该架构由两部分组成:边界感知网络(BAN/ Boundary Aware Network)和快速前向长短期记忆(FF-LSTM/ Fast-Forward Long Short-Term Memory)。
首先,研究者使用 BAN 通过联合考虑帧级的吸引力和边界性质来生成高质量的时间提议(temporal proposal)。然后再应用 FF-LSTM,这往往能得到帧序列之间的高阶依赖性,从而可用于决定一个时间提议是否为连贯完整的故事。
不同于之前的最佳方法(这些方法的提议生成仅取决于动作性质),BAN 使用了额外的帧级边界性质来生成提议,这能在提议数量较小时实现更高的精度。而且,不同于用于序列建模的传统 LSTM,FF-LSTM 引入了连接堆叠的 LSTM 层的快速前向连接,从而能在深度循环拓扑结构(deep recurrent topology)中助力实现稳定高效的反向传播,进而提升视频故事分类的效果。
研究表明,不管是在定量指标还是在用户研究上,新提出的网络在保留故事型长视频裁剪问题上都优于之前的方法。研究者表示,这是首个将 FF-LSTM 用在视频领域建模序列的研究。
用户可在公共学术研究中使用该数据集:https://ai.baidu.com/broad/download
保留故事型长视频裁剪问题的数学形式类似于时间动作定位(temporal action localization)问题。其训练数据集可以表示为:
![]()
其中帧级特征 u 来自长视频 V_i,其对应于一个 ground-truth 的切片式短视频集。{s_{i,j} , e_{i,j}} 是 V_i 的第 j 个区间的起始和结束索引。N 是训练视频的数量,T_i 是 V_i 的帧数量,l_i 是 V_i 的区间数量。
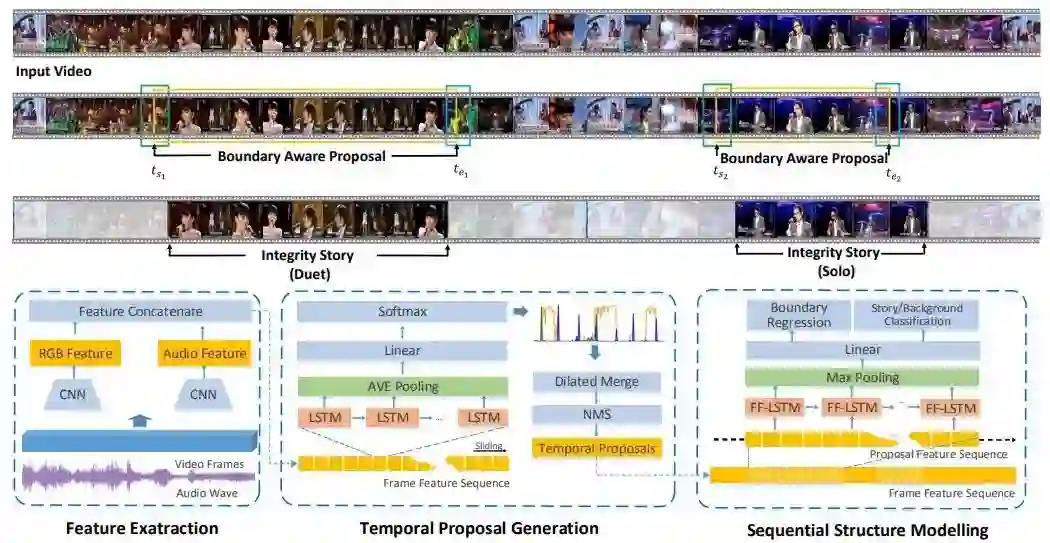
下图 4 展示了所提出框架的架构,其包含三个主要组件:特征提取、时间提议生成和序列结构建模。
![]()
给定一段输入的长视频,先提取出基于 RGB 的 2D 卷积特征和音频特征,并将它们连接起来。在时间提议生成组件中,将这些特征输入 BAN,预测每帧的吸引力和边界性质。然后执行一个扩张融合算法(dilated merge algorithm),根据帧级的吸引力和边界性质分数生成时间提议。在序列结构建模组件中,通过 FF-LSTM 建模每个提议的序列结构,这能输入提议的分类置信度分数以及经过细化微调的边界。
这篇论文提出了一种全新的边界感知网络(BAN),它可以提供高质量的故事提议。如上图 4 所示,BAN 将连续 7 帧的特征作为一个 LSTM 层的输入。这个 LSTM 的输出经过平均池化后,再使用一个线性层来预测 4 个类别的概率分数,包括故事中、背景、故事起点边界和故事终点边界。中间帧的标签由分数最大的类别确定。
如果一个帧序列中的每一帧都属于「故事中」类别,那么便将该帧序列视为一个候选故事。再执行一个简单的扩张融合算法,将距离较小(5 帧)的相邻候选故事合并到一起。然后执行非最大抑制(Non-Maximal Suppression,NMS),减少冗余并生成最终提议。
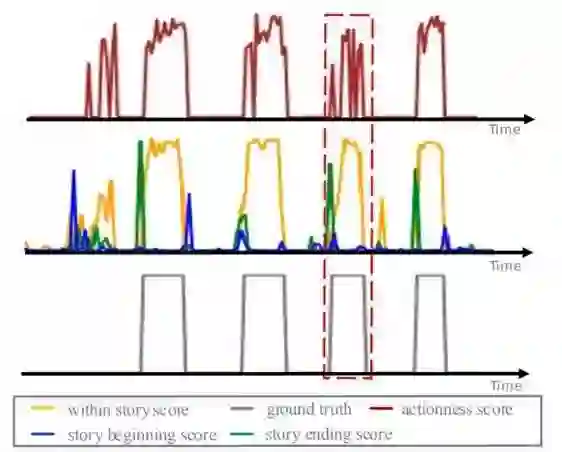
不同于之前仅依靠动作性质来生成提议的常用方法,BAN 利用了额外的帧级边界性质来生成提议。下图 5 展示了 TAG [30](上排)与新提出的 BAN(中排)的动作性分数的比较。
![]()
图 5:
TAG [30](上排)与新提出的 BAN(中排)的动作性分数的比较。
对于 TAG,研究者展示了大于 0.5 的动作性分数。对于 BAN,他们用不同颜色展示了三个前景类别的最大分数。最下面一排是 ground-truth 提议区间。可以看到,BAN 的分数曲线比 TAG 更平滑,而且边界与 ground-truth 提议区间的匹配也更好。
首先简要回顾下用作序列结构建模基础的 LSTM。长短期记忆(LSTM)是循环神经网络(RNN)的一种增强版本,其带有一组记忆单元 c。LSTM 的计算可以写为:
![]()
其中 t 是时间步,x 是输入,[z_i, z_g, z_c, z_o] 是连接起来的大小一致的四个向量,h 是 c 的输出,b_i、b_g 和 b_o 分别是输入门、遗忘门和输出门,σ_i、σ_g 和 σ_o 分别是输入激活函数、遗忘激活函数和输出激活函数,W_f、W_h、W_g 和 W_o 都是可学习的参数。(1)式的计算可有效地分为两个连续的步骤:隐藏模块
![]() 和循环模块
和循环模块
![]() 。
通过直接堆叠多层 LSTM,可以构建得到一个简单直观的深度 LSTM。
令 LSTM_k 是第 k 个 LSTM 层,则:
。
通过直接堆叠多层 LSTM,可以构建得到一个简单直观的深度 LSTM。
令 LSTM_k 是第 k 个 LSTM 层,则:
![]()
![]()
图 6:
FF-LSTM 与传统 LSTM 的比较。
上图 6(b) 展示了一个有三个堆叠层的深度 LSTM。可以看到,隐藏模块的输入是其前一层的循环模块的输出。在 FF-LSTM 中,增加了一个连接相邻层的隐藏模块的快速前向连接。新增的连接构建了一个既不包含非线性激活,也不包含循环计算的快速通道,这样就能轻松地传播信息或梯度。图 6(a) 展示了一个有三层的 FF-LSTM,这个深度 FF-LSTM 的计算可以表示为:
![]()
![]()
其中 c_{i,k} 是提议的标签,P(c_{i,k}|p_{i,k}) 是由多层 FF-LSTM、最大池化和二元分类器定义的分类分数。
λ 是一个平衡的权重参数,1_{c_{i,k}=1} 的意思是只有当提议标签为 1 时,第二项才有效。
![]()
![]()
s_{i,k} 和 e_{i,k} 分别是通过最大 IoU 选择的 p_{i,k} 的 ground-truth 故事的起点索引和终点索引。
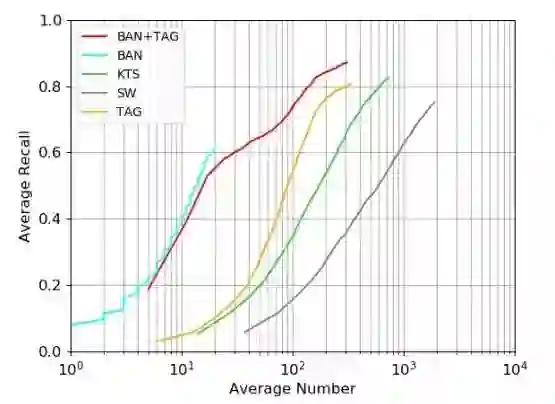
为了探究所提出 BAN 的有效性,研究者比较了滑动窗口搜索(sliding window search,SW)、KTS 和 TAG。下图 7 总结了比较结果。
![]()
图 7:
在 TruNet 数据集上不同时间提议生成方法的 AR-AN 曲线。
可以看到,当提议数量较小时,新提出 BAN 的平均回调指标(average recall)显著高于其它方法,但由于其选择标准,它不能生成其它方法那样多的提议。注意 TAG 和 BAN 是高度互补的,将它们的结果融合到一起可以得到明显更好的曲线。
下表 2 总结了时间提议生成和序列结构建模的控制变量研究结果。同时使用这两个组件对最终结果而言至关重要。
![]()
表 2:
时间提议生成和序列结构建模的控制变量研究结果。
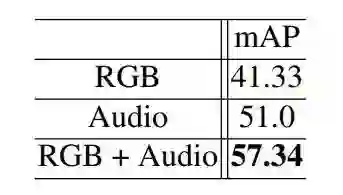
下表 3 总结了使用不同特征的控制变量研究结果。可以看到,RGB 和音频特征是高度互补的,丢弃任何一类特征都会显著影响结果表现。
![]()
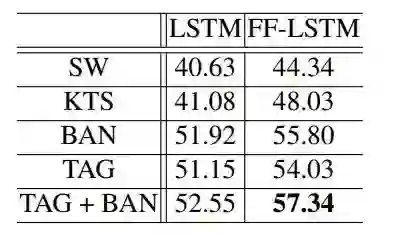
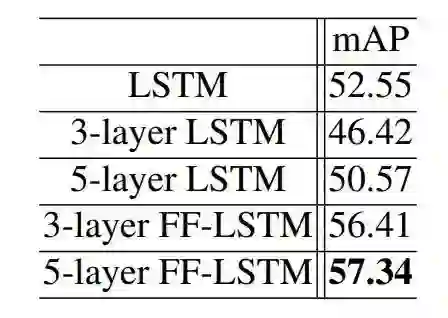
下表 4 总结了为序列结构建模使用不同的深度循环模型的控制变量研究结果。直接堆叠多层 LSTM 会导致性能下降,这是由于收敛的困难。相对而言,使用更深的 FF-LSTM 能显著提升表现。
![]()
下表 5 总结了回归损失的控制变量研究结果。可以看到,增加回归损失实现了近 4.0 的 mAP 提升。
![]()
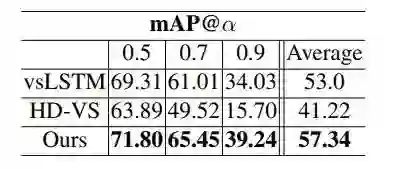
研究者还将新提出的框架与当前最佳视频摘要方法进行了比较,包括 vsLSTM [36] 和 HD-VS [33]。结果见下表 6。
![]()
表 6:
在不同 IoU 阈值 α 上用 mAP 衡量的结果比较。
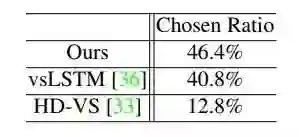
研究者还执行了主观评估,让用户比较所生成短视频故事摘要的质量,结果见下表 7。
![]()
可以看到,新提出框架生成的故事摘要收到了 46.4% 的投票,高于 vsLSTM(40.8%)和 HD-VS(12.8%)。

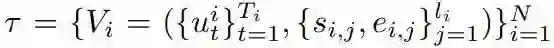
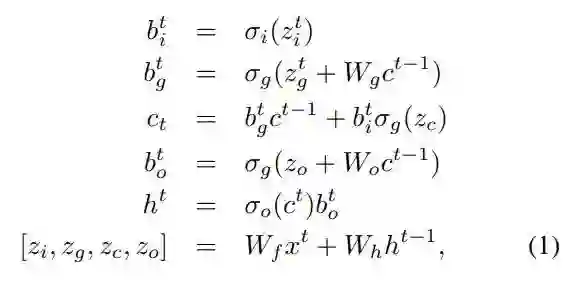
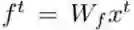 和循环模块
和循环模块
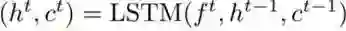 。
。