大规模升级来临,谈谈Oracle 12cR2使用经验

作者介绍
杨志洪,dbaplus社群联合发起人,新炬网络首席布道师,对数据库、数据管理有深入研究,合译《Oracle核心技术》《Oracle Exadata专家手册》。
大规模升级来临,咱们来谈谈Oracle 12cR2使用经验。
一、升级到12cR2的必要性
随着2019年2月13日,Oracle 19c (Oracle 12.2.0.3) for Exadata 版本发布,Oracle 12cR2体系的数据库版本终于迎来了长期支持版本(Oracle 12c的最后一个大版本),也就是说数据库版本还在Oracle 10g/11g的系统是时候考虑升级了。
特别是在Oracle 11.2.0.4以前的版本,用了db link的系统,务必要升级。
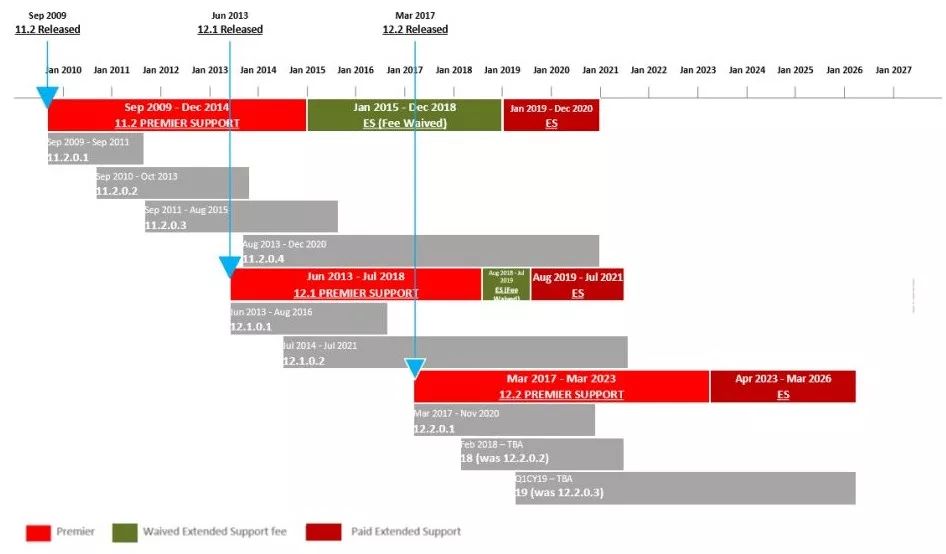
其实,根据Oracle数据库生命周期和版本演进路线,到2018年12月31日,Oracle 11.2已经结束了免费的扩展服务期(Fee Waived ES),一些新遇到的bug补丁用普通的SR账号将没有权限下载。
同时考虑到SCN天花板速率算法变化的问题,12c升级就变得更加必要了(当然,应用没有变化,或者没有使用dblink的可以不用考虑)。
Oracle每个版本的bug都很多,不过并非是Oracle数据库软件不行,而是因为Oracle是OLTP领域的绝对王者,提供了太多方便的功能,bug就多了。所以每次升级前,我们都会去撸一遍fix list,看看有没有新的bug被其他人发现并解决了。
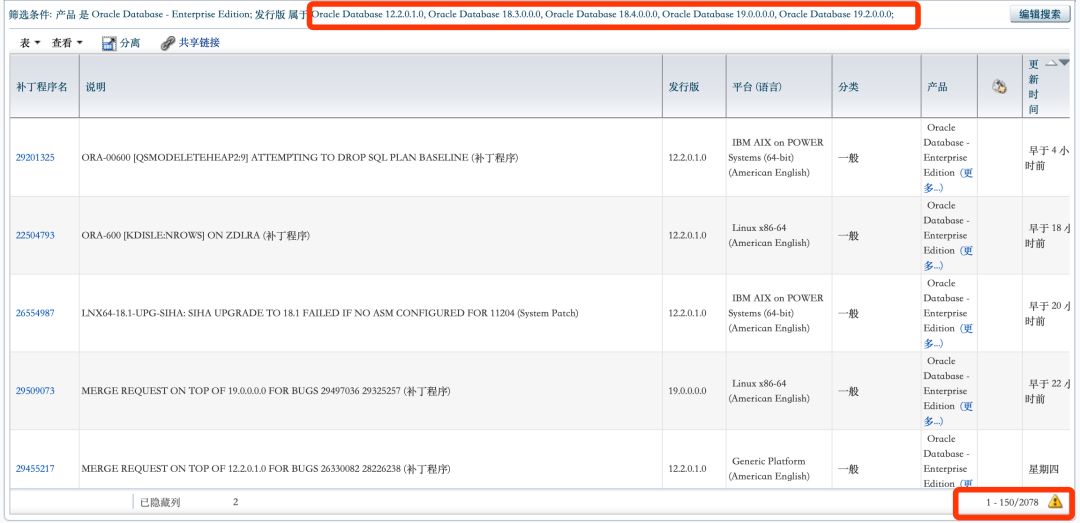
到目前为止,Oracle 12.2系列的fix patch数量是2078个:
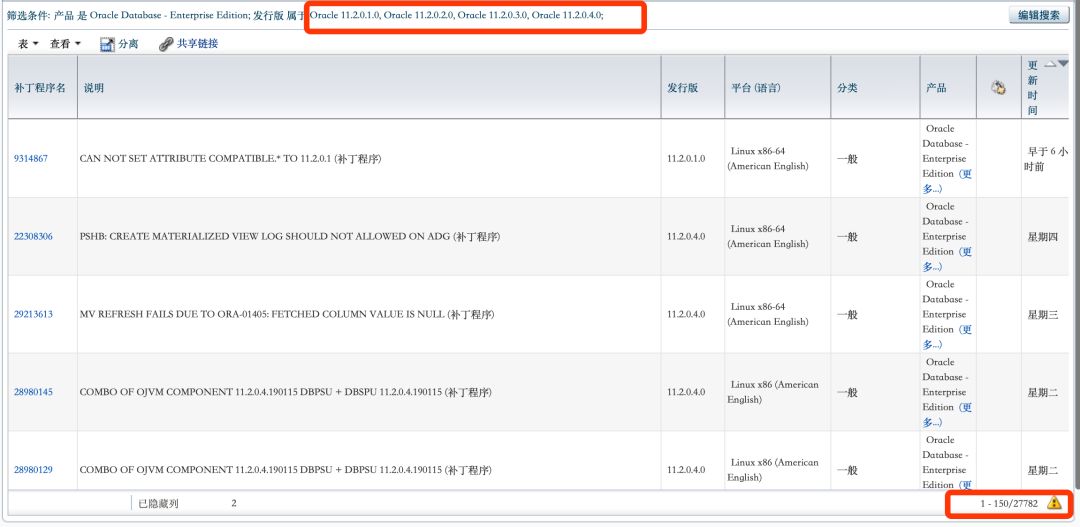
当然,这补丁数量还是远远低于Oracle11.2系列的27782个:
也远低于Oracle 10.2系列版本的26281个(这些补丁均不包含集群补丁):
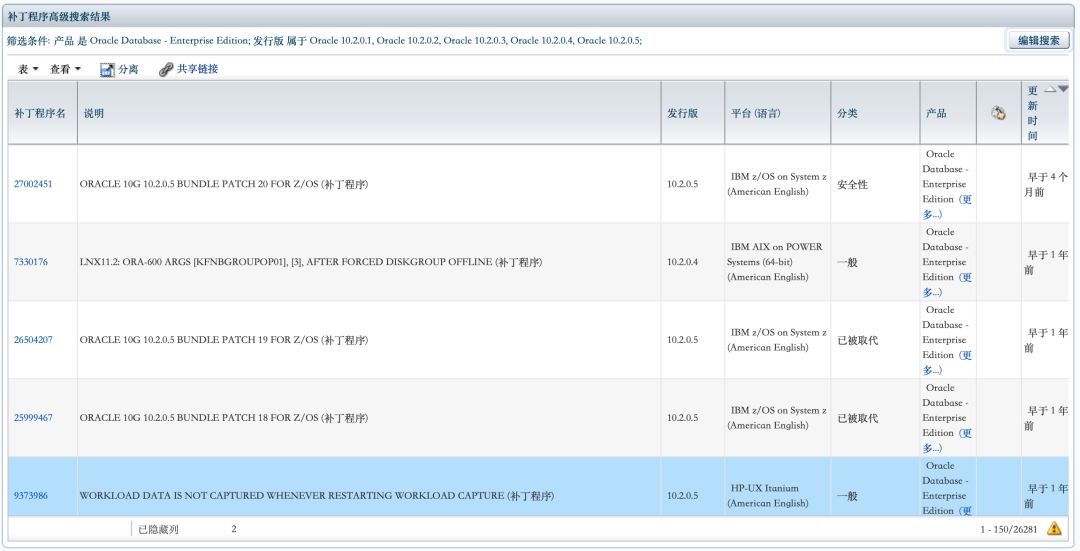
这个结果有些出乎意料,12cR2上的patch数量比前2个版本少了一个数量级。一个可能性是12cR2的bug少了很多,另一个可能性是12cR2还没有迎来大规模升级,而今年就是升级到12cR2的最佳时机。
二、Oracle 12c体系的一些新特性
Oracle 12c相比Oracle 11g,有3个特性被广为期待:
多租户:12cR1最多允许252个租户,12cR2-19c最多允许4098个租户,由max_pdbs参数控制
In-Memory Option
Sharding
从两年多的案例来看:
Sharding功能几乎没有被使用
主要原因是:在12.2,一个SDB中只支持一个Table Family,一个正常业务数据库都会需要有多个Table Family;而在Oracle 19c里,增加了Multiple Table Families特性,或许可以好好用一下
In-Memory Option没有大规模用起来
原因是一方面是使用场景,另一方面是维护成本,多租户特性成了这个版本的扛鼎之作。
多租户特性(Multitenant)是12c体系最重要的特性,在12.1.0.1版本引入。开创性地在一个容器数据库(cdb)中可以包含很多个可插拔数据库(pdb),每个pdb之间可以有自己独立的参数和资源占用限制,所以该特性成为了12c版本中最受欢迎的特性。
很多企业使用多租户特性整合那些零碎且单独占用一个数据库的小应用,大大减少了机器的数量,降低了数据库许可费用,而且pdb迁移起来更加灵活。
pdb使用过程中有几个bug,影响还是蛮大的。其中一个是pdb在Data Guard的备端运行一段时间后会”消失”:
这个bug从17年开始有one-off patch,但是一直没有彻底修复。彻底修复只能升级到Oracle 18c,或者今年将推出来的19c。
我此前一直非常好奇,为什么一个bug的补丁不能在下一次PSU的时候,将这个one-off patch一起打包进去呢?
直到2018年一个叫oraguy的用户在Hacker News爆出了如下信息:

Oracle 12.2这个版本,有将近2500万行C代码!(相比较而言,最受欢迎的NoSQL数据库Redis最新版本5.0.4也不过2万多行代码,真是短小精干。)
oraguy是这么描述一个Oracle数据库程序员的工作流程的:
拿到一个新任务:解决一个新bug。
花两周时间了解20个不同的flag( 标记 ),这些标记用一种很奇怪的方式制造了这个bug。
尝试添加flag,写几行代码,同时要小心不会制造出更多bug。
将更改提交到包含大约100-200台服务器的测试服务器集群,这些服务器将编译代码,构建新的Oracle数据库软件,并以分布式方式运行数百万个测试。
回家。第二天来上班,继续处理别的bug 。测试可能需要20-30个小时才能完成。
再回家。再来上班,检查集群测试结果。顺利的话,会有大约100个失败的测试;倒霉的话,将有大约1000个失败的测试。随机选择一些测试并试图搞清楚你的假设出了什么问题。或许还需要考虑10多个 flag才能真正理解bug的本质。
再添加一些flag以尝试解决问题。再次提交更改以进行测试。再等20-30个小时。
来来回回,重复两周,大概理解出现这个bug的原因了。
终有一天,在你几乎锤蛋自尽之前,发现某次测试完全通过了。
再写上百个测试,以防下次哪个晦气孩子要碰项目的时候,不会把你的修改搞砸……
提交最后一轮测试的成果。然后提交以供审核。审查本身可能还需要2周到2个月。所以接下来继续去处理下一个bug 。
在2周到2个月之后,一切已就绪,代码将最终合并到主分支中。
再看看上面一两万个patch,有一些没有能合并到主分支(PSU)中,也就可以理解了。
PDB除了可以用来做小库整合外,还有一个便利,就是在当机器资源使用率不均衡的时候可以在不同CDB之间做热插拔。
但实践证明,热插拔最好在同版本之间做,否则可能出现异常。
在12c建pdb的语法里,还新出现了一个option叫PATH_PREFIX,用来限制一些对象(directory objects/oracle XML/create pfile/oracle wallets)只能在特定目录下。这个目录前缀,一旦添加将伴随着pdb直到终老,连datapump想换个目录都不行,所以添加一定要谨慎。
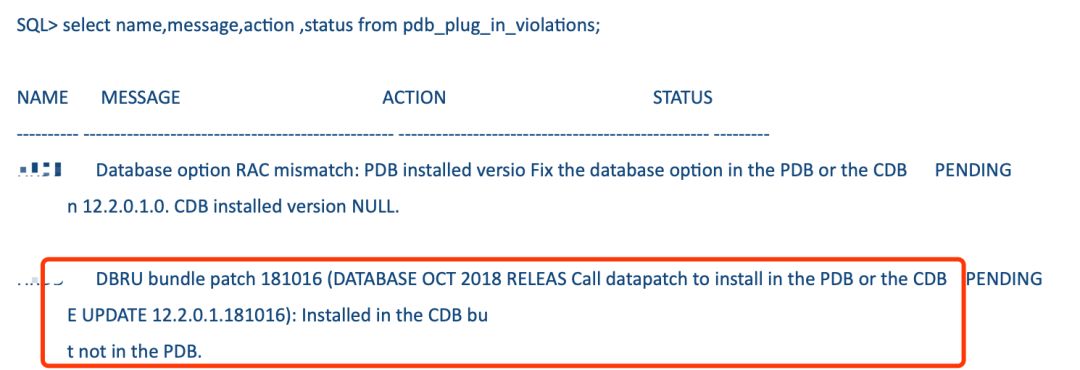
在Oracle 18c里做pdb迁移的时候,执行DBMS_PDB.CHECK_PLUG_COMPATIBILITY,可能会报ORA-7445[__intel_ssse3_rep_memcpy()],这是Bug 28502403 - ORACLE 18.3.0 MULTITENANT: COMPATIBILITY CHECK DOES NOT WORK。
不过这个bug只在18.2和18.3出现,用最新的18c可以规避这个问题。
随着国家网络安全法的实施,企业安全检查愈加严格,“定期修改数据库密码”从应付检查变成严格执行。这对11g dg的DBA来说,是一件极为痛苦的事情,每次修改主库密码,还得手动同步密码文件到各个备库实例,稍微漏了某个实例没同步到,数据就不同步了。
12cR2推出的一个新特性——自动同步密码文件到Data Guard备库,当SYS、SYSDG等的密码发生更改时,主数据库中的密码文件被更新,然后将更改传播到配置中的所有备库。
与此可以配合的是11gR2推出的一个新参数REDO_TRANSPORT_USER,创建单独的日志传输授权用户,并赋予SYSOPER权限,然后再将此账户封存即可。使用过程中需要注意的是,这个用户名是区分大小写的。
在最新Oracle19c也推出了不少新特性,我最为关注的有2个:
自动统计信息管理
统计信息管理一直是大企业数据库管理的一个难题,随着表的数据变化,统计信息能够实时更新,防止SQL语句选择次优执行计划(据官网介绍,这是AWS抛弃Oracle选用Aurora的重要理由)。
Oracle 19c内置了专家系统,内置算法捕获应用程序SQL历史进SQL仓库、识别有益于新SQL的后选索引、验证、决策、在线验证、监控的自动索引创建,并且一段时间自动创建的索引如果不合适还会自动删除。
自动索引创建
自动索引创建这一特性引入了一个开关视图dba_auto_index_config。鉴于19c目前仅推出了Exadata版本,这2个特性是否能在生产上使用还有待评估。
三、一些谨慎使用的特性
将交易型生产数据库迁移到Oracle 12c(包括Oracle12cR2、Oracle18c、Oracle 19c),有一些特性建议关闭(其中部分特性是从Oracle 10g开始一直都建议关闭的),设计很理想,现实很骨感,我们能做的就是帮忙尽量圆润一些。
下面默认数据库都是Oracle RAC:
1、实例并行执行
PARALLEL_FORCE_LOCAL该参数默认是False。理论上讲,集群多个节点,并行处理的时候多个节点一起来,均衡用力,是最优方案。事实是多节点并行处理的协调成本很高,节点间通讯负载大。因此要改为True,实现进程级别本地化并发处理。
2、内存自动管理
从10g开始sga自动管理sga_target到12c的内存级别自动管理memory_target。核心生产库全部建议改为手动,非核心几个月不看一眼的库可以设置为自动管理。
3、查询结果缓存
一次缓存,百次使用。对某些特定“静态”查询类的系统可能适用,在OLTP里这种场景几乎没有。所有result_cache_max_size=0。
4、布隆过滤算法
Bloom Filter由布隆在1970年提出,用来检索一个对象是否在某个集合中,优点是空间效率高于其他算法,缺点是有一定的误识别率。一旦识别错误,效率就是百倍降低,这对于高效稳定的系统来说是不可接受的。
_bloom_filter_enabled=false;_bloom_pruning_enabled=false
动态资源重组:每个数据库资源,都有其Master,拥有者和请求者,初衷是根据请求情况来动态调整Master,减少实例间数据传输。
_gc_policy_time=0;_gc_undo_affinity=false;"_gc_read_mostly_locking"=FALSE。
5、 段延迟创建
新建一个数据表,Oracle只会建这个对象而暂不分配segment,只有当往表里插入第一条数据的时候才创建segment。初衷是节约存储空间,但该特性bug极多。
deferred_segment_creation=false
6、内存列式存储
In-Memory Option是12c的一大亮点,对特定的应用适用。
社群曾出过专门的文章《平均提速20倍!Oracle 12c In-Memory最佳实践》、《In Memory—Oracle 12C重要新特性IMO详解》,IM特性是需要不定期维护的,不仅需要关注IM中表是否加载成功,是否出现In-Memory Area不足的情况,在内存资源有限的情况下,还要优化IM中存放的表,及时添加需要的表,删除不需要的表。
通常建议关闭:inmemory_size=0;inmemory_query=disable;
四、几个问题/bug
升级到Oracle 12c后遇到的一些重要bug,建议要去整改。
问题1:SGA手动管理模式下,Oracle偷偷去自动增大Shared pool了(Oracle 19.2解决)。
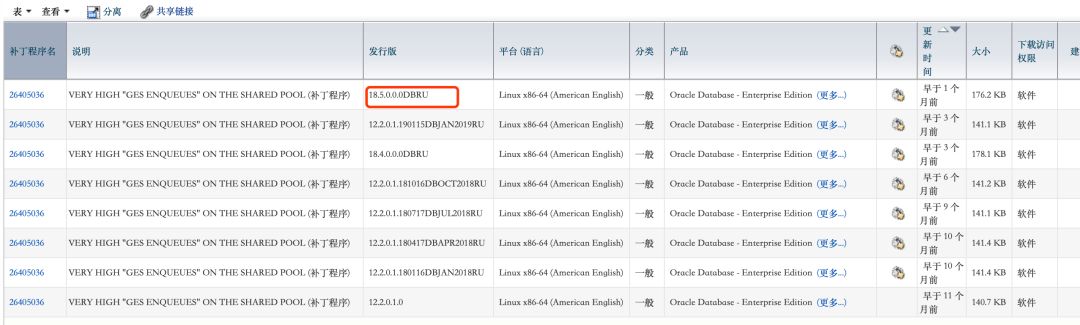
命中Bug 26405036 Large Allocation Of "ges enqueues" and "ges resource dynamic" In The Shared Pool 会把共享池从20g不断自动resize到200g以上,直到sga_max_size中无法有空余空间了,应用报ora-04031。
解决方法是打补丁,目前Oracle 18.5的补丁也出来了:
临时解决方案如下:
SQL> oradebug setmypid
SQL> oradebug lkdebug -m reconfig lkdebug
问题2:在home目录产生大量trace文件或者是单个超大文件,空间满导致系统hang。
这个问题现象相似,但不止是一个bug:
原因1:
Trace files generation with message “AUTO SGA: kmgs_parameter_update_timeout gen0 0 mmon alive 1”.
这是Bug 25415713,安装one-off patch可以解决。
原因 2:
Trace files generated from RMAN module with KRB messages.
可能是:
Bug 28174827 :RMAN Unconditional KRB Trace File After Installing Fix Of Bug 22700845
Bug 28390273 :RMAN UNCONDITIONAL KRB TRACE FILE AFTER PATCH 27674384
通过alter system set events 'trace[krb.*] disk disable, memory disable';解决。
原因3:
KZAN: ORA-55917 during CLI write.
KZAN: SYS user audit records will written to files now.
需要禁用KTLI tracing:
alter system set event='55901 trace name context off';
alter system set event='TRACE[RecordCompose] off';
alter system set event='TRACE[FileWrite] off';
alter system set event='TRACE[QueueWrite] off';
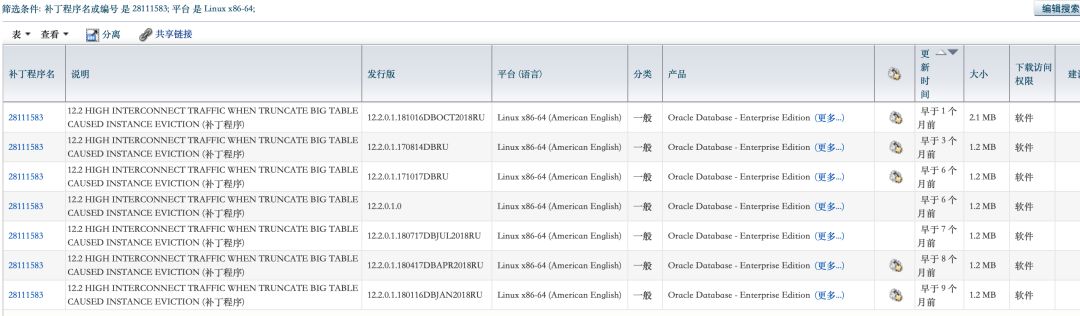
问题3:在RAC集群环境下,对大表进行truncate会导致另一个节点hang住。dbaplus社群有过专门诊断文章:你敢在Oracle 12c R2上做大表truncate吗?
该bug在最新版的PSU中已经修复:
问题4:升级到Oracle 12c/18c后,低版本数据库客户端连接会报错:
ORA-28040: No matching authentication protocol/ORA-01017: invalid username/password; logon denied
需要先在sqlnet.ora中加入SQLNET.ALLOWED_LOGON_VERSION_CLIENT=8/SQLNET.ALLOWED_LOGON_VERSION_SERVER=8,然后再重置密码解决。(参考MOS文档 ID 2296947.1)
五、几个重要参数
还有其他一些建议设置的参数,大多数是为了避免bug,还有一部分是为了关闭某些Oracle特性。
ASM初始化参数,memory_target设为2G,process设置为200或以上。
数据库参数:
_serial_direct_read= AUTO; 避免high direct path read
_lm_tickets=5000;默认1000,增加GES messaging tickets
_px_use_large_pool=TRUE;并行会话使用large pool而不是共享池,降低ora4031
_b_tree_bitmap_plans=FALSE;
SEC_CASE_SENSITIVE_LOGON=FALSE;禁用密码大小写敏感
_gc_defer_time=0;减少进程对热块争用
_datafile_write_errors_crash_instance=FALSE;数据文件(sysytem以外表空间)I/O读写错误被发现时,发生错误的数据文件进行offline而不关闭实例。
event='10949 trace name context forever:28401 trace name context forever, level 1:10849 trace name context forever, level 1' ;关闭数据库当中用户持续输入错误密码导致大量library cache lock;关闭自动serial direct path read特性,避免出现过多的直接路径读,消耗过多的IO资源
_undo_autotune=FALSE;关闭undo自动调整
_use_adaptive_log_file_sync=FALSE;写日志缓冲区到文件方式默认是采用Post/wait方式,在11.2.0.3版本开始增加了Polling的方式。关闭该参数不允许切换。
"_fix_control"='14142884:ON','8560951:ON','8893626:OFF','9344709:OFF','9195582:OFF','9380298:ON','13704562:OFF','16053273:OFF','8611462:OFF','17760375:OFF','17938754:OFF','8560951:ON'
当然,同时要说明的是,这些仅仅是认为必要注意的参数,真实环境还有其他参数也同样要注意。如果你在阅读过程中,认为还有某些参数是应该必须调整的,欢迎在文章后面留言,给其他同行做一个参考。
六、升级参考文章
核心数据库升级是一件复杂的系统工程,必须经过严谨的方案制定、升级测试、性能测试及最后的割接迁移流程,虽然我们已经经历过上千套系统的12c升级,但是每次升级前的测试仍然能发现新的缺陷。
有些是应用代码的,有些是SQL性能的,有些是数据库软件的甚至有些是存储链路的,充分的测试才是确保成功升级的唯一保证。
对于大数据量的升级迁移,Oracle副总裁swonger有一个演讲:migrate + 200TB database in less than 1 day,讲的是欧洲电网的案例,使用了TTS+expdp+perl等多种手段,值得一看。
链接:
https://www.neooug.org/gloc/Presentations/2018/Swonger_Migrate_200TB.pdf
对于升级来说,不仅要关心升级本身能否按时间完成,关于升级之后的性能如何、稳定性如何、可用性、数据一致性和完整性如何也同样重要,而且都应在正式升级割接前进行充分的模拟验证。
dbaplus社群过往也发布过与Oracle升级相关的一些文章,可以作为参考:

掌握数据库管理新思路,获得更优操作启发
不妨来这些技术盛会学点独家技能
↓↓扫码可了解更多详情及报名↓↓
2019 Gdevops全球敏捷运维峰会-北京站

↓↓点击图片可了解更多详情及报名↓↓






