R爬虫小白入门:Rvest爬链家网+分析(一)

作者:汪喵行 R语言中文社区专栏作者
知乎ID:https://www.zhihu.com/people/yhannahwang
前言
最近对爬虫有了莫名的兴趣,于是开始自学用R入门爬虫。爬链家网是因为网站源代码不是框架结构,并且不需要API就可以直接爬,没有什么反爬机制。想着正好拿上海二手房价来分析一波也是挺有趣的。
自己就把这个入门帖分一二三:
一会写如何在链家网上进行爬虫;二就拿数据来玩一玩,看看有什么有趣的东西;三是通过机器学习,根据其他的attributes来预测一套房子的均价。
package主要用到的有R的爬虫利器rvest,还有xml12,dplyr,stringr等
1rm(list=ls())
2library("xml2")
3library("rvest")
4library("dplyr")
5library("stringr")
首先我们library一下
我们想要的是,按照网页源代码,把我们想要的数据爬出来,然后放在同一个数据框里,这样比较便于分析,所以先设一个空的数据框:
1house_inf<-data.frame()
之后我们就去链家网上看一看:上海二手房|上海二手房出售|最新上海二手房信息 - 上海链家网(https://sh.lianjia.com/ershoufang/)
不难发现,第一页的网页是:https://sh.lianjia.com/ershoufang/
第二页是:http://sh.lianjia.com/ershoufang/d2
第三页是:http://sh.lianjia.com/ershoufang/d3
第n页是:http://sh.lianjia.com/ershoufang/dn
然后我们就知道,其实就可以写一个for循环,把这个规律写进去就好了。
然后看一下想爬的信息:比如有楼层,单位价格,总价格,平米,所在的区域,楼层等等,然后为了便于分析,最后全部放在一个数据框里,写进csv文件就好。

1house_tag<-web%>%html_nodes("div.info-table")%>%html_text()
发现<div='info-table'>里面有很多我们要的信息,所以就把它爬下来,放在house_tag这个里面。
然后发现这个house_tag也是有点乱的:

我们会需要把“|”左右的变成一列列,比如拿第一个房子的格局来说,就可以这样:
1house_size<-str_split_fixed(house_tag," +\\|",7)[,1]
output就是:

其他的都是一样,就不赘述了,直接上源代码:
1rm(list=ls())
2library("xml2")
3library("rvest")
4library("dplyr")
5library("stringr")
6i<-1
7house_inf<-data.frame()
8for (i in 1:300){
9 web<- read_html(paste("http://sh.lianjia.com/ershoufang/pg/d",i,sep=""),encoding="UTF-8")
10
11 house_tag<-web%>%html_nodes("div.info-table")%>%html_text()
12 # overallprice
13 house_p <- web%>%html_nodes("span.total-price")%>%html_text()
14
15 house_tag <- gsub("\t","",house_tag)
16 house_tag <- gsub("\n","",house_tag)
17 #size
18 house_size<-str_split_fixed(house_tag," +\\|",7)[,1]
19 #housetype <- gsub("\n","",housetype)
20 #location
21 house_loc<-str_split_fixed(house_tag," +\\|",7)[,3]
22 #price_unit
23 house_unitprice<-str_split_fixed(house_tag," +\\|",7)[,4]
24 house_unitprice <- gsub(".*单价","",house_unitprice)
25 house_unitprice <- gsub("元/平","",house_unitprice)
26 #m
27 house_m<-str_split_fixed(house_tag," +\\|",7)[,2]
28 house_m <- gsub("平.*","",house_m)
29 #level
30 house_level <- str_split_fixed(house_tag," +\\|",7)[,2]
31 house_level <- gsub(".*区/","",house_level)
32 house_level <- gsub("层.*","",house_level)
33 house<-data_frame(house_p,house_size,house_loc,house_unitprice,house_m,house_level)
34 house_inf<-rbind(house_inf,house)
35
36}
37
38#将数据写入csv文档
39write.csv(house_inf,file="house_inf.csv")
比较神奇的是,有几个变量我用“|”分割怎么都分割不开,最后无奈只好用gsub强行把我不要的去掉了。应该可以再简便。
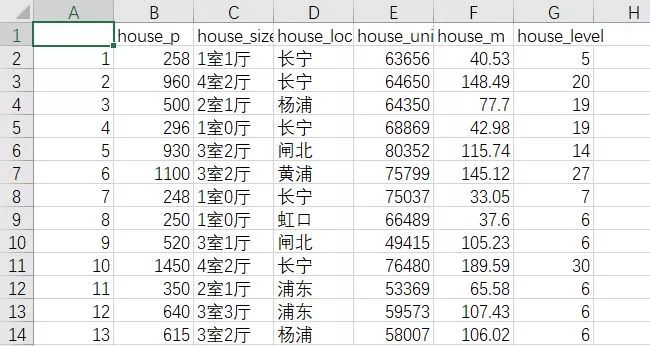
好了最后我们得到了一个csv文件,下篇小白帖就可以开始玩这个数据啦!具体见下篇!

往期精彩:

公众号后台回复关键字即可学习
回复 爬虫 爬虫三大案例实战
回复 Python 1小时破冰入门
回复 数据挖掘 R语言入门及数据挖掘
回复 人工智能 三个月入门人工智能
回复 数据分析师 数据分析师成长之路
回复 机器学习 机器学习的商业应用
回复 数据科学 数据科学实战
回复 常用算法 常用数据挖掘算法
必胜绝招,就是把全部奉献给你所热爱的一切↓



