
序列推荐旨在根据特定用户的一系列历史交互行为向用户推荐个性化的新交互项目,是当前互联网信息服务系统中广泛采用的推荐策略。然而,现有的序列推荐方法往往极大地受限于真实世界场景中的数据稀疏问题,尤其是冷启动等场景下,缺乏大量有效的用户交互行为,导致推荐系统无法充分挖掘用户意图,从而限制了推荐性能。
近日,来自清华大学以及央视频的研究团队,聚焦于序列推荐中的数据稀疏性问题,利用扩散模型的优势对序列推荐进行数据增强,提出了Diff4Rec框架,展示了实现高质量和鲁棒性推荐的潜力。该论文发表于ACM Multimedia 2023 (Brave New Ideas).
**研究背景 **
一直以来,推荐系统往往极大地受制于数据稀疏性的影响:一方面,用户驻留时间短,提供的交互数据有限,导致显著的数据稀疏问题;另一方面,用户画像和社交关联的缺失给推荐系统带来了冷启动问题。为了解决这一问题,各类数据增强方法被提出,以增强数据样本的多样性,提高推荐系统的效率和适应性。
因此,在这一过程中,如何让模型生成符合用户意图的增广数据,并有效地应用于下游推荐任务,成为了至关重要的问题: (1) 一方面,如何充分将现有模型的生成能力用于推荐数据的增广,解决数据稀疏性; (2) 另一方面,如何避免潜在的噪声数据,将增广数据有效地输入推荐模型,同时增强用户交互行为和模型学习目标。
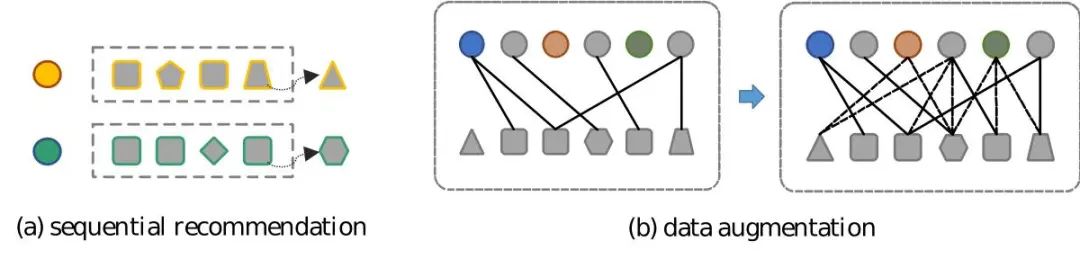
**序列推荐与数据增强 **** **
为了解决这一问题,我们提出了基于扩散模型增强的课程学习调度序列推荐方法Diff4Rec,在潜在空间中对用户-视频交互建模,生成增广样本,并从交互增强和目标增强层级使用扩散模型生成的样本,逐步实现交互序列的增强和序列推荐器的学习。
**Diff4Rec方法 **
利用扩散模型增强用户-物品交互在当前研究中存在很大的空白,并提出了以下两个挑战: (1) 当前扩散模型多为图像生成而设计,其目的是捕捉视觉像素模式,而未必能为序列推荐实现数据增强。如何将扩散模型的学习能力整合到推荐领域中,并生成与用户意图一致的可靠交互是非常重要的。 (2) 给定特定的用户-物品交互增强扩散模型,如何确保扩散过程生成的数据始终有利地作用于序列推荐,同样也需要精心的设计。
为了解决以上问题和挑战,Diff4Rec采用两阶段设计,首先利用扩散模型在潜在空间中对用户-物品交互建模,生成增广样本,然后通过课程调度策略,从交互增强和目标增强两个层级利用扩散模型生成的样本,学习序列推荐器。
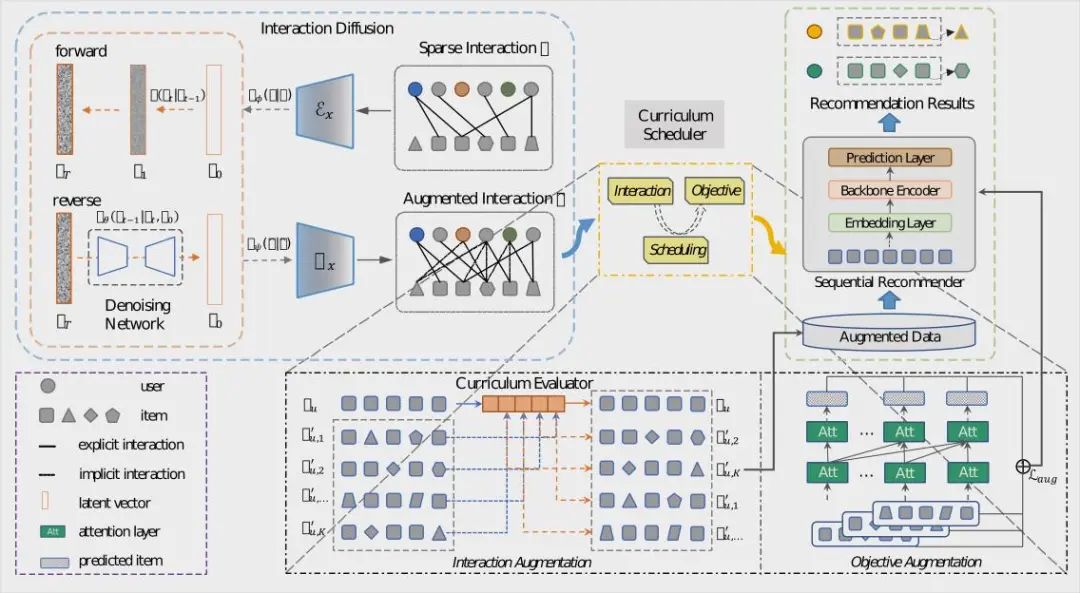
Diff4Rec框架
具体而言,我们针对推荐任务设计了一个扩散模型来逐步破坏和恢复用户-物品交互,并将其编码到一个潜在空间中,以压缩复杂信息并捕获潜在的用户意图: 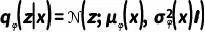
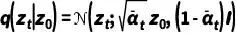

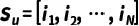
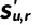
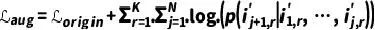
同时,我们提出了由易到难的课程训练策略,以减轻扩散模型生成样本中隐藏的潜在噪声。训练样本的难度可以根据增广序列与原始序列的相似性决定:

**实验结果 **
我们在真实世界数据集上进行了丰富的实验,以证明Diff4Rec框架的优越性。
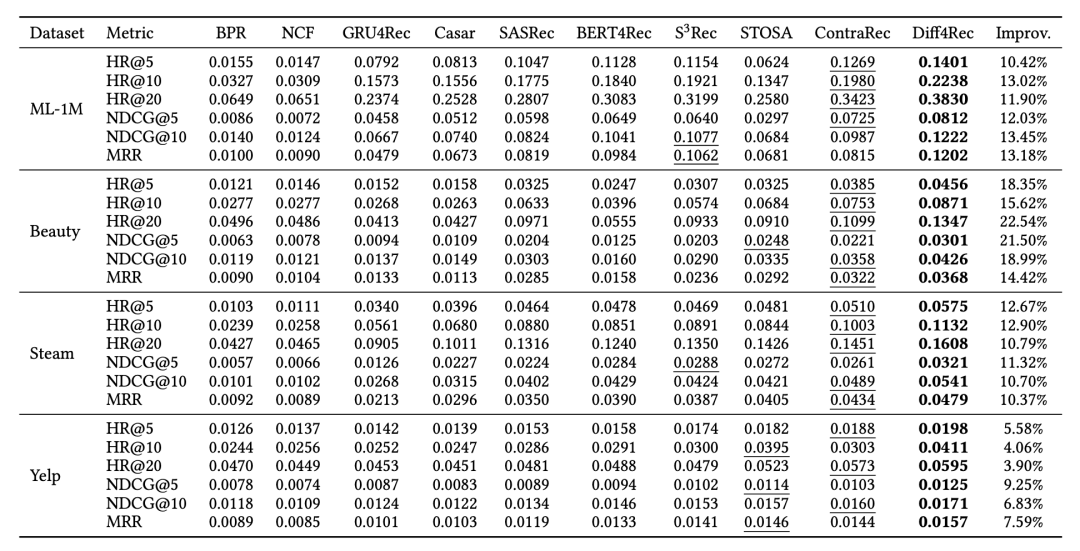
结果表明Diff4Rec在多个公共数据集上优于SOTA模型。同时表明i) 在潜在空间中学习到的扩散模型能有效地拟合用户的各种潜在意图;ii) 课程调度策略通过精选数据有效地增强了序列行为,并鼓励模型在更大范围内进行优化,从而产生更好的推荐。
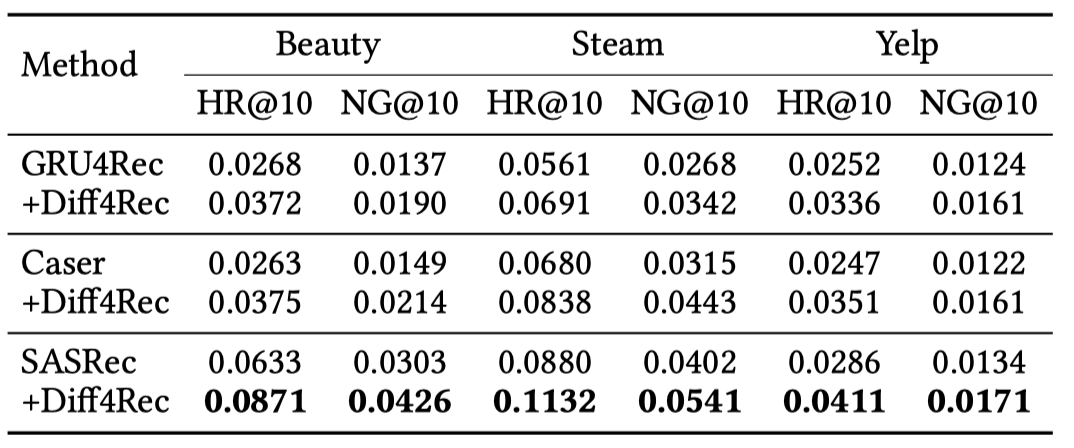
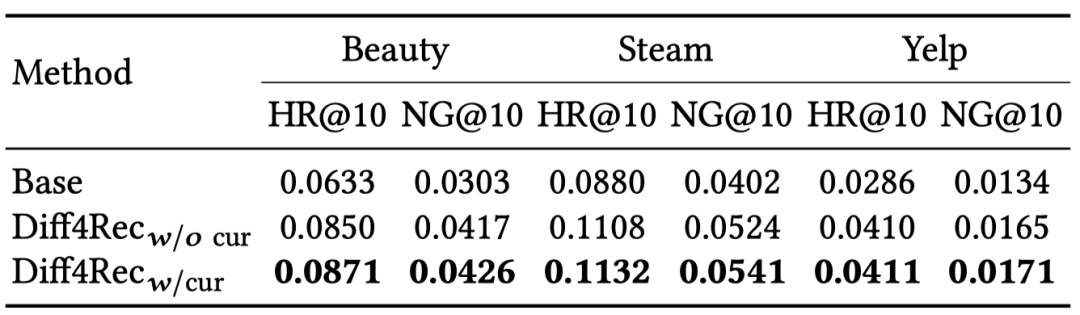
消融研究表明Diff4Rec在多个基本序列推荐模型上表现出稳定而优越的性能,体现了我们方法的有效性和灵活性。此外,Diff4Rec正确地选择了有利于序列增强的样本,课程调度器的交互增强和目标增强有效地丰富了稀疏交互。
**总结与展望 **
Diff4Rec能够利用扩散模型强大的生成能力实现用户交互的数据增广,并通过课程学习进行数据选取和推荐模型的联合优化,提升推荐系统的性能。实验结果表明,使用扩散模型来促进序列推荐的性能改进,特别是在减轻数据稀疏性问题方面有着极大的潜力。

