NeurIPS 是关于机器学习和计算神经科学的国际会议,宗旨是促进人工智能和机器学习研究进展的交流。NeurIPS 2025 会议将于12月2日至12月7日在圣地亚哥会议中心召开。

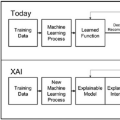
理解 AI 系统行为已成为确保安全性、可信性以及在各类应用中有效部署的关键。 为应对这一挑战,三个主要研究社区提出了不同的可解释性方法: * 可解释人工智能(Explainable AI) 聚焦于特征归因,旨在理解哪些输入特征驱动了模型决策; * 数据中心人工智能(Data-Centric AI) 强调数据归因,用于分析训练样本如何塑造模型行为; * 机制可解释性(Mechanistic Interpretability) 研究组件归因,旨在解释模型内部组件如何对输出作出贡献。
这三大方向的共同目标都是从不同维度更好地理解 AI 系统,它们之间的主要区别在于研究视角而非方法本身。 本教程首先介绍基本概念与历史背景,阐述可解释性为何重要,以及自早期以来该领域是如何演进的。第一部分技术深度解析将涵盖事后解释方法、数据中心解释技术、机制可解释性方法,并通过一个统一框架展示这些方法共享的基本技术,如扰动、梯度与局部线性近似等。 第二部分技术深度解析则聚焦于内生可解释模型(inherently interpretable models),并在可解释性的语境下澄清推理型(chain-of-thought)大语言模型与自解释型 LLM 的概念,同时介绍构建内生可解释 LLM 的相关技术。我们还将展示可使这些方法易于实践者使用的开源工具。 此外,我们强调了解释性研究中前景广阔的未来研究方向,以及其在更广泛的 AI 领域中所引发的趋势,包括模型编辑、模型操控(steering)与监管方面的应用。通过对算法、真实案例与实践指南的全面覆盖,参与者将不仅获得对最先进方法的深刻技术理解,还将掌握在实际 AI 应用中有效使用可解释性技术的实践技能。