
AAAI人工智能会议(AAAI Conference on Artificial Intelligence)由国际先进人工智能协会主办,是人工智能领域的顶级国际学术会议之一。第40届AAAI人工智能会议将于2026年1月20日至1月27日在新加坡召开。本系列文章将分期介绍自动化所在本届会议上的录用论文成果,欢迎交流探讨。

**22. **VAGU & GtS:用于视频异常联合定位与理解的基于大语言模型的基准数据集与框架
VAGU & GtS: LLM-Based Benchmark and Framework for Joint Video Anomaly Grounding and Understanding **作者:**高诗博,杨沛沛,刘扬扬,陈懿,朱涵,张煦尧,黄琳琳 视频异常检测(VAD)旨在识别视频中的异常事件并确定其发生的时间区间。当前主流的VAD方法主要分为两类:一类是基于DNN的传统方法,侧重于时间定位;另一类是基于LLM的新兴方法,更强调语义理解。异常理解和定位对于全面的视频异常检测都至关重要,并且可以相互补充。然而,现有的模型或数据集都无法同时支持这两项任务。 为了解决这一问题,本研究引入了VAGU(视频异常定位与理解),这是首个整合这两项任务的基准数据集。每个VAGU实例都包含异常类别、语义解释、精确时间定位和视频问答的标注。本研究还提供了多项选择题形式的视频问答在一定程度上消除了主流方法使用LLM打分的偏见。基于该数据集,研究团队提出了“粗看后细察”(GtS)框架,这是一个由文本提示引导的免训练框架,它首先实现对高概率异常区域的快速粗略定位,然后针对这些候选区域进行详细的异常解释和时间边界优化。此外,研究还提出了能够联合评估语义可解释性和时间精度的JeAUG指标,该指标联合评估语义可解释性和时间精度,克服了传统指标只能针对异常时序或异常理解其中一方面进行评估的局限性。
图1. GtS框架流程图
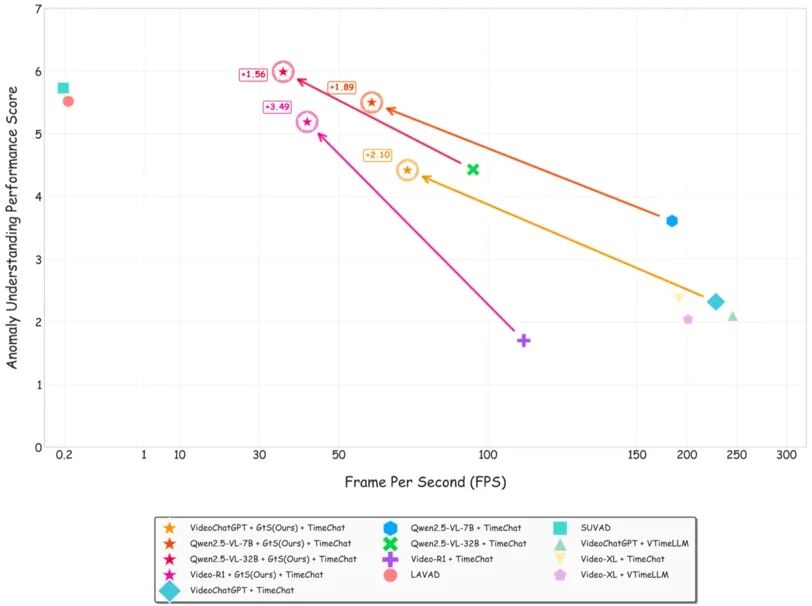
图2.主流开源模型在使用GtS框架前后的推理速度和检测性能变化
**23. **CACMI:基于上下文感知的跨模态交互实现显式时序-语义建模的密集视频字幕生成
CACMI: Explicit Temporal-Semantic Modeling for Dense Video Captioning via Context-Aware Cross-Modal Interaction **作者:**贾明达,孟维亮,傅增煌,李毅恒,曾琪,张轶凡,鞠昕,许镕涛,张吉光,张晓鹏 密集视频字幕生成用于联合定位和描述未剪辑视频中的显著事件。近年来的方法主要集中在利用额外的先验知识和先进的多任务架构以实现竞争性的性能。然而,这些流程依赖于隐式建模,使用帧级或碎片化的视频特征,无法捕捉事件序列之间的时间连贯性和视觉上下文中的全面语义。 为了解决这一问题,本研究提出了一种显式时间-语义建模框架,称为上下文感知的跨模态交互(CACMI),它同时利用视频中的潜在时间特征和文本语料库中的语言语义。具体而言,该模型由两个核心组件组成:跨模态帧汇聚通过跨模态检索聚合相关帧,以提取时间上连贯的、与事件对齐的文本特征;上下文感知特征增强利用查询引导的注意力,集成视觉特征与伪事件语义。研究团队在 ActivityNet Captions 和 YouCook2 数据集上进行了充分的实验,结果表明 CACMI 在密集视频字幕生成任务上达到了最先进的性能。
图1. CACMI框架。CACMI采用了一种通过检索增强生成的范式用于密集视频字幕生成(DVC)任务。该模型使用预训练好的CLIP图像编码器提取帧级特征。(a) 跨模态帧聚合(CFA)模块由两个协同组件组成:事件上下文聚类通过聚合时间和语义一致的帧率级特征生成聚类事件表示,事件语义检索通过余弦相似度从语料库匹配相关的语义信息,产生检索到的语义特征。(b) 上下文感知特征增强(CFE)。该模块促进检索到的文本特征与视觉表示之间的跨模态交互,弥合模态间的差距以生成增强的帧率级特征。最后,我们使用一个多任务的Transformer生成事件定位和字幕生成的联合输出。
图2.CACMI与目前先进的方法对比,在事件定位和字幕生成质量上都表现更加出色
**24. **HGATSolver: 面向流固耦合的异构图注意力求解器
HGATSolver: A Heterogeneous Graph Attention Solver for Fluid–Structure Interaction ★Oral
**作者:**张钦奕、王泓、刘思耀、林海川、曹林颖、周小虎、陈晨、王双翌、侯增广 流固耦合是心血管模拟领域的核心问题,其数值模拟通常计算成本高昂。现有神经算子难以精确学习流、固两种物理域中截然不同的动力学规律,且在耦合界面处易出现数值不稳定。 为此,团队提出了HGATSolver。受启发于分块积分算子思想,创新地将系统建模为异构图,为流体、固体及界面区域分别定义不同的节点和边类型,从而将物理结构直接编码为模型的结构化先验。这使得模型通过类型感知的消息传递机制,分别学习域内动力学和跨域耦合关系。 为进一步提升求解的稳定性和精度,设计物理条件门控机制(PCGM)作为可学习的自适应松弛因子,有效抑制显式时间积分中的误差累积;并引入域间梯度平衡损失(IGBL),使模型能够根据预测不确定性动态调整流体与固体区域的优化权重。 在两个新构建的FSI基准数据集和一个公开数据集上进行验证,结果表明HGATSolver均达到了最优性能,尤其在流体-固体界面附近表现出更高的精度。该工作有望为AI4S中多物理场耦合系统的智能求解提供有效且通用的学习框架。
HGATSolver的主要框架
**25. **VasoMIM: 面向血管分割的血管解剖感知掩码图像建模 VasoMIM: Vascular Anatomy-Aware Masked Image Modeling for Vessel Segmentation **作者:**黄德兴,周小虎,桂美将,谢晓亮,刘市祺,王双翌,项天宇,马瑞泽,肖怒放,侯增广 从X射线血管造影图像中准确分割出血管,对于辅助医生进行高效的临床诊断与治疗决策至关重要。然而,标注数据的稀缺为训练分割模型带来了巨大挑战。自监督学习,特别是掩码图像建模(Masked Image Modeling, MIM),能够有效利用大规模未标注数据学习可迁移的表征,从而显著降低对下游分割任务的标签依赖。但受限于血管像素与背景像素间严重的类别不平衡,现有的MIM方法往往难以有效捕捉细微的血管解剖结构,导致所学到的血管表征不佳。 为解决这一难题,本研究提出了“血管解剖感知掩码图像建模”(VasoMIM),其核心思想是将解剖学先验知识引入到预训练过程中。具体而言,VasoMIM包含两个互补的模块:解剖引导掩码策略和解剖一致性损失。前者优先对富含血管信息的patch进行掩码操作,迫使模型专注于重建血管相关区域;后者则强制要求原始图像与重建图像在血管语义层面保持一致,从而显著增强了血管特征表示的判别能力。实验结果表明,VasoMIM在三个基准数据集上均取得了当前最佳的性能。
图1. VasoMIM的结构示意图
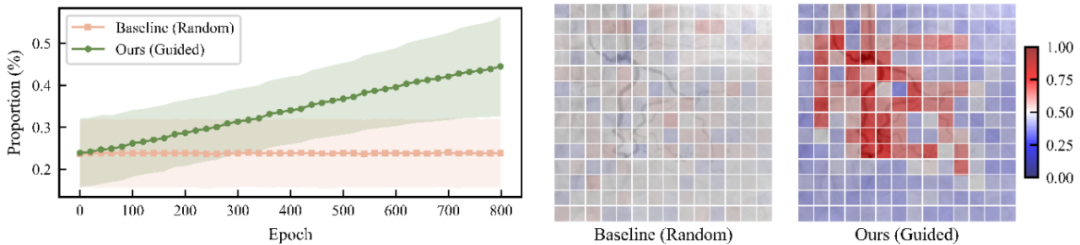
图2. 左:预训练期间,在被掩码的patch中,包含血管的patch所占的比例;右:预训练过程中的每个patch的掩码率。
**26. **大模型驱动社交媒体智能体的真实基准测试
SoMe: A Realistic Benchmark for LLM-based Social Media Agents **作者:**薛迪展,崔静,钱胜胜,胡传锐,徐常胜 由大语言模型(LLMs)驱动的智能体近期展现出令人印象深刻的能力,并在社交媒体平台上日益受到关注与欢迎。尽管LLM智能体正在重塑社交媒体的生态格局,目前仍缺乏对其在媒体内容理解、用户行为洞察以及复杂决策制定等核心能力方面的系统性评估。 为应对这一挑战,本研究提出了SoMe——一个开创性的基准测试平台,专为评估配备多种工具(用于访问与分析社交媒体数据)的社交媒体智能体而设计。SoMe 包含多样化的8类社交媒体智能体任务、来自多个社交媒体平台及外部网站的 9,164,284 条帖子、6,591 个用户档案、25,686 份报告,以及经过精细标注的 17,869 个任务查询。相较现有面向社交媒体任务的数据集与基准,SoMe 首次提供了一个兼具多样性与真实性的评测平台,支持基于LLM的智能体执行各类实际社交媒体任务。通过广泛的定量与定性分析,本研究首次系统性揭示了主流具备智能体能力的LLM在真实社交媒体环境中的表现,并识别出若干关键局限:评估结果表明,当前无论是闭源还是开源的LLM,尚无法令人满意地完成社交媒体智能体任务。SoMe 为未来社交媒体智能体的研究与发展,提供了一个兼具挑战性与重要意义的试验场。
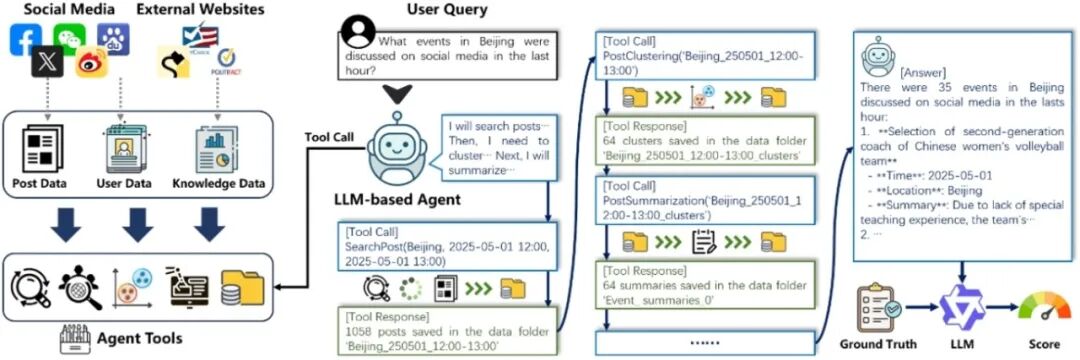
SoMe中社交智能体的工作流程图:社交媒体智能体通过调用数据获取、管理与分析等工具进行交互,从而生成针对用户查询的答案;该答案随后在大语言模型(LLM)评分器的辅助下进行评估。
**27. **基于双工奖励优化的测试时组合式图像检索
Duplex Rewards Optimization for Test-Time Composed Image Retrieval **作者:**周浩樑,张飞飞,徐常胜 组合式图像检索(Composed Image Retrieval, CIR)通过将参考图像与修改文本相结合,以检索目标图像。近年来,零样本(Zero-Shot)CIR因无需人工标记的三元组数据而备受关注。然而,这种范式不可避免地需要额外的训练语料库、存储和计算资源,限制了其实际应用。 受测试时自适应(TTA)进展的启发,本研究提出了测试时CIR(TT-CIR)范式,旨在在减少计算资源消耗的同时,使模型有效适应并精准检索测试样本。本研究发现,当前主流的基于奖励机制的TTA技术面临两个关键挑战:一是修改受限的奖励池,阻碍了模型对语义相关候选奖励的探索;二是保守的知识反馈,抑制了奖励信号对当前数据分布的适应性。针对上述挑战,本研究提出了一种基于双工奖励优化的测试时强化学习(TT-RLDR)框架,结合反事实引导的多项式采样(CMS)策略和双工奖励建模(DRM)模块。CMS通过探索与查询视觉语义相关的候选奖励池,精准发掘有效奖励信号;DRM则生成稳定且适应性强的双工奖励,指导模型适应当前测试数据。在主流CIR基准测试中,该方法在检索准确率和效率上均优于现有方案。
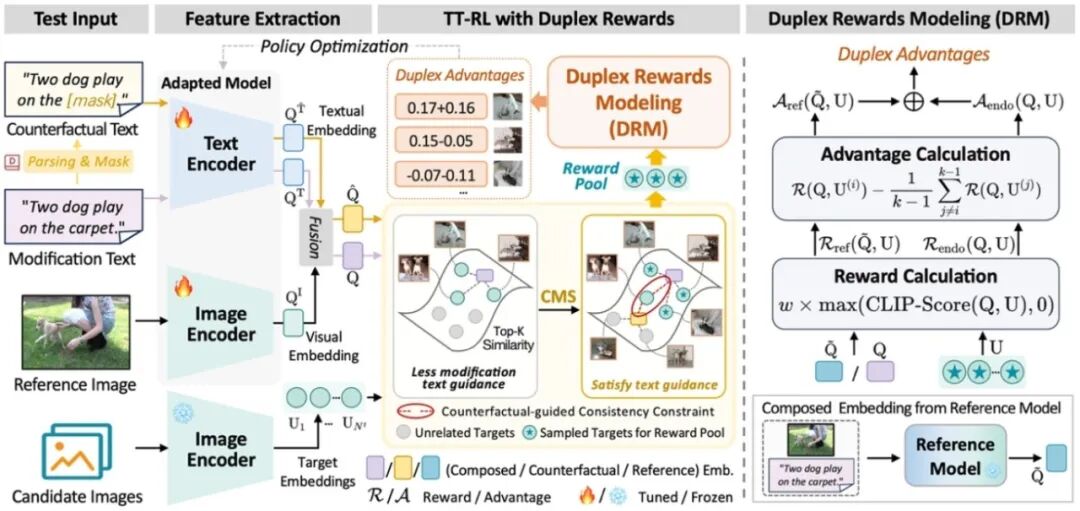
TT-RLDR整体架构图,包括两个关键组件:一个反事实引导多项式采样(CMS)策略和一个双工奖励建模(DRM)模块。
**28. **I2CD:面向组合零样本学习的基于解构-组合-再解构的可逆因果框架
I2CD: An Invertible Causal Framework for Compositional Zero-Shot Learning via Disentangle-Compose-Disentangle **作者:**袁召全,王子宁,潘圆康,罗骜,李威,吴晓,徐常胜 组合零样本学习(CZSL)是人工智能领域的一个关键挑战,旨在识别图像中未见过的状态-对象组合。现有方法在状态-对象解耦和学习因果干预不变性表征方面存在局限,导致对未见组合的泛化能力不足。 论文针对CZSL任务中的解耦问题,提出了一种新的可逆因果架构,通过解耦-组合-再解耦机制,采用可逆神经网络、因果干预和反事实生成技术,在图像的隐式解耦表空间中对状态/对象进行因果干预,从而生成反事实的新的组合,并对该新组合进行重新解耦,最后在解耦表征、组合表征空间中分别与文本的对齐,实现图像的状态-对象解耦,从而增强组合零样本识别的鲁棒性。实验结果表明,该框架在封闭世界和开世界设置下均达到了最先进的性能,尤其在未见组合上表现突出,验证了所提方法的泛化能力与因果解耦的有效性。
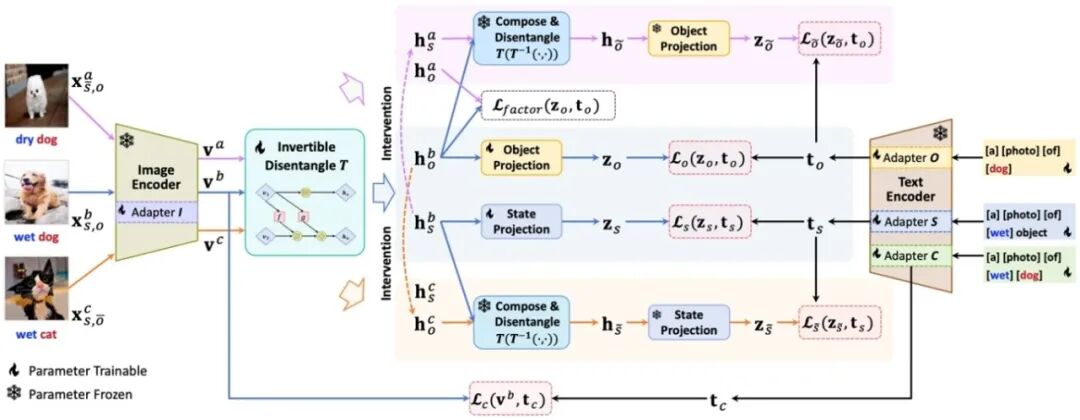
用于组合零样本学习的可逆因果架构图
**29. **MPI-Mamba:用于磁性粒子成像各向异性图像校准与去模糊的隐空间特征融合Mamba模型
MPI-Mamba: Latent Feature Fusion Mamba for Anisotropic Image Calibration and Deblurring in Magnetic Particle Imaging **作者:**张利文,苗肇基,申钰松,卫泽琛,惠辉,田捷 磁性粒子成像(Magnetic Particle Imaging, MPI)是一种新兴的医学成像技术,具有纳摩尔级体内灵敏度和无辐射的动态实时检测能力,在精准医疗领域展现出巨大潜力。然而,MPI在实际应用中面临着图像各向异性的问题,进而引发图像畸变和边界模糊。现有深度学习方法主要依赖于仿真数据,缺乏真实世界MPI数据集的支持,限制了其在实际场景中的应用效果。 为解决这一难题,本研究历时三年,设计并构建了一个真实世界MPI各向异性图像数据集,涵盖多种灵敏度、分辨率、血管及形状的数据。在此基础上,提出了一种基于Mamba架构的新方法—MPI-Mamba(如图1所示),用于各向异性图像校准。该方法创新性地设计了潜特征融合状态空间模型模块,实现多尺度特征的充分融合,并引入条件潜扩散模型分支,在高度压缩的潜空间中提取图像特征,有效指导校准和去模糊过程。实验结果显示,MPI-Mamba在模拟数据和真实世界MPI数据集上的表现均优于现有方法,显著提升了各向异性图像的校准与去模糊效果。
网络结构图
**30. **通过鲁棒时域自集成提升脉冲神经网络的鲁棒性–准确率权衡
Boosting the Robustness-Accuracy Trade-off of SNNs by Robust Temporal Self-Ensemble **作者:**王纪航,赵东城,陈若霖,张倩,曾毅 脉冲神经网络(Spiking Neural Networks, SNNs)作为一种兼具能效与类脑特性的计算模型,其对抗扰动的脆弱性缺乏系统理解。本文从时域集成的视角重新审视SNN的对抗鲁棒性,将网络视为由离散时间步上不断演化的子网络集合。该视角揭示了两个关键但尚未被充分研究的问题:其一,单个时间子网络的易损性;其二,对抗脆弱性在时间维度上的可迁移性。为解决上述问题,本文提出了一种名为“鲁棒时域自集成(Robust Temporal self-Ensemble, RTE)”的训练框架。RTE在提升各时间子网络鲁棒性的同时,有效抑制了对抗扰动在时间上的迁移。该方法通过统一的损失函数将两类目标融合,并引入随机采样策略以实现高效优化。 大量基准实验结果表明,RTE在鲁棒性–准确率权衡方面显著优于现有训练方法。进一步分析显示,RTE能够重塑SNN的内部鲁棒性分布,使其决策边界更加稳健且具有时间多样性。
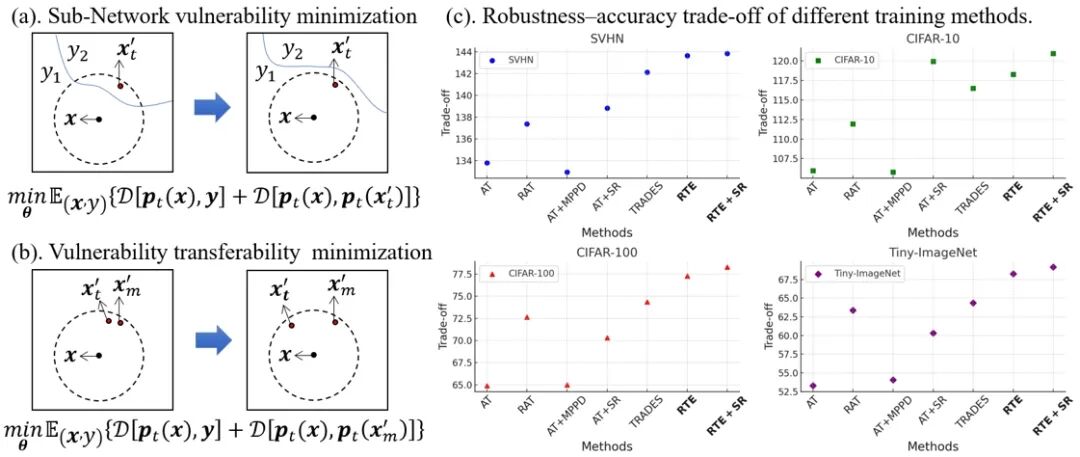
(a) 子网络的脆弱性由其对最敏感输入扰动的反应所刻画。(b) 最小化脆弱性在时间维度上的可迁移性,可以减少子网络间的共同弱点,从而提升整体集成鲁棒性。(c) 不同训练方法得到的鲁棒性-准确率权衡效果,RTE在更困难的数据集上表现显著更好。
**31. **基于正交表征的多维神经解码脑机接口
Multi-dimensional Neural Decoding with Orthogonal Representations for Brain-Computer Interfaces **作者:**田凯茜,赵圣嘉,张予涵,余山 传统脑机接口系统主要专注于单一运动变量的解码,难以支持需要同时提取多个相关运动维度的自然、高带宽神经控制。本文提出了多维神经解码(MND)任务,能够从单一神经群体记录中同时提取多个运动变量(方向、位置、速度、加速度)。MND面临两个核心挑战:从共享皮层表征解码相关运动维度时的跨任务干扰,以及跨会话、被试和范式的泛化问题。 为解决这些挑战,研究团队提出了OrthoSchema框架,这是一个受皮层正交子空间组织和认知模式重用启发的多任务框架。OrthoSchema通过强制表征正交性来消除跨任务干扰,并采用选择性特征重用迁移来实现少样本跨会话、被试和范式适应。在猕猴运动皮层数据集上的实验表明,OrthoSchema在跨会话、跨被试和具有挑战性的跨范式泛化任务中显著提高了解码精度,在微调样本有限时性能提升更为显著。消融研究证实了所有组件的协同效应至关重要,OrthoSchema能够有效建模跨任务特征并捕获会话关系以实现鲁棒迁移。
图1.多维神经解码中的关键挑战。(A) 对多样化神经信号并行解码的需求不断增长。(B) 在跨会话、被试和任务的分布偏移下泛化能力有限。
图2. OrthoSchema框架概述。尖峰数据通过全局卷积层处理,然后通过LSTM块(可替换)获得潜在表征。在潜在空间中应用正交性约束。模型包括用于方向分类和手部位置、速度、加速度回归的多个解码头。训练期间使用会话/被试分类头来建模分布偏移。推理时移除会话分类组件,选择性重用参数进行少样本微调。
**32. **基于能量的神经群体动力学自回归生成
Energy-based Autoregressive Generation for Neural Population Dynamics **作者:**葛宁凌,戴思诚,朱宇,余山 计算神经编码模型是深入理解大脑机制、建模复杂神经群体动态的核心途径。然而,该领域长期受限于高保真度建模与计算效率的双重瓶颈。具体来说,预测模型虽然高效,却难以充分捕捉神经活动固有的试验间变异性;基于VAE的方法虽能通过潜空间灵活采样,却无法精确再现复杂的群体和单神经元统计特性;而近期备受关注的扩散模型(如LDNS)尽管能有效建模统计特性,却因其迭代去噪机制导致计算成本高昂,严重影响生成效率。 为有效解决这些问题,本文提出Energy-based Autoregressive Generation (EAG) 框架,基于energy score仅通过单次前向传播即可实现高效高质的神经生成。研究结果表明,EAG不仅取得SOTA的生成质量,高度还原真实神经活动;还显著提升生成效率,相较于扩散模型达到96.9%的效率提升。此外,EAG还具有强大的泛化能力,对未曾见过的行为上下文生成神经数据;其生成的数据可帮助提升运动脑机接口的解码准确率,提升最高可达54.7%。本工作为兼具计算效率和生物真实性的神经群体建模奠定基础,具有重要的神经科学研究和神经工程应用潜力。
图1. EAG相较于LDNS取得了质量和效率上的双重提升
图2. EAG具有强大的泛化能力,对未见过的行为上下文生成神经动态
**33. **基于多模态大语言模型的广义多图像视觉定位
GeM-VG: Towards Generalized Multi-image Visual Grounding with Multimodal Large Language Models **作者:**郑姝榕,朱优松,赵弘胤,杨帆,詹宇飞,唐明,王金桥 多模态大语言模型在单图像定位和通用多图像理解方面取得了显著进展。近年来,一些方法开始探索多图像定位,但受限于单目标定位和任务类型的局限,缺乏广义定位的统一建模。 为此,本研究提出 GeM-VG,一种具备广义多图像视觉定位能力的多模态大语言模型。我们根据跨图像线索依赖和推理需求对现有任务进行分类整理,并构建 MG-Data-240K 数据集,以弥补现有数据在目标数量和图像关联性上的不足。针对多样化任务的鲁棒性挑战,我们提出混合强化微调策略,结合链式思维推理与直接回答,利用其互补优势,并通过规则奖励引导优化,有效提升模型感知与推理能力。实验表明,GeM-VG 在广义定位任务中具备优秀性能:在多图像定位任务上,MIG-Bench 和 MC-Bench 分别超越先前领先 MLLMs 2.0% 和 9.7%;在单图像 ODINW 上提升 9.1%。此外,模型在通用多图像理解任务上也保持了先进性能。
图1. GeM-VG模型整体架构
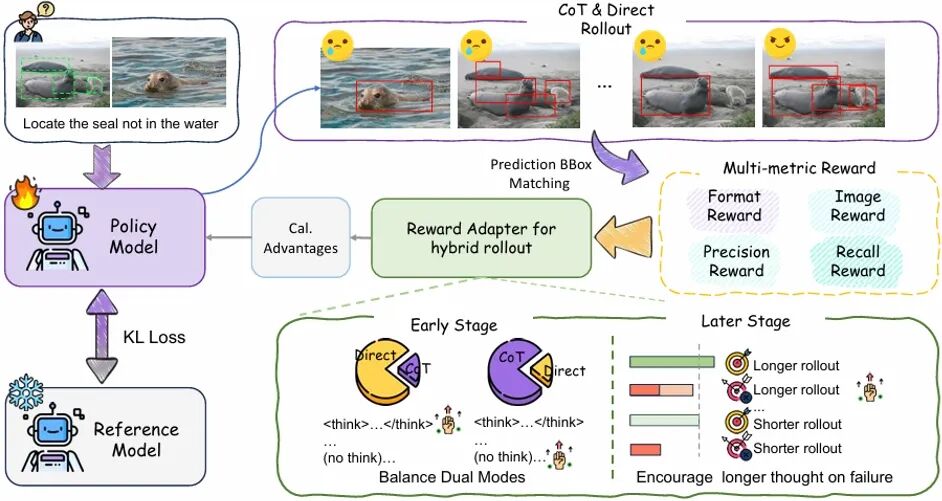
图2. 强化微调策略框架
**34. **基于功能感知神经元分组的 LLM 结构化剪枝泛化能力提升方法
Improving Generalization in LLM Structured Pruning via Function-Aware Neuron Grouping **作者:**于涛,安永琪,朱宽,朱贵波,唐明,王金桥 后训练结构化剪枝是压缩大语言模型(LLM)的重要技术路径。然而,当少样本校准集无法充分覆盖预训练数据分布时,现有方法在下游任务上往往泛化能力受限。针对这一问题,我们提出 FANG(Function-Aware Neuron Grouping),一种功能感知的后训练剪枝框架,通过识别并保留对特定功能关键的神经元,减轻由校准集偏差带来的性能退化。 FANG 首先根据神经元所处理的语义上下文类型,将具有类似功能的神经元分组,并对各组分别进行剪枝;在组内重要性评估时,对与该功能高度相关的 token 赋予更高权重。同时,FANG 显式保留在多类上下文中均有贡献的多功能神经元。为在稀疏率与性能之间取得更佳权衡,FANG 还依据不同模块的功能复杂度自适应分配稀疏率。实验结果表明,FANG 在基本保持语言建模能力的前提下显著提升了下游任务表现。结合 FLAP 与 OBC 两种代表性剪枝方法使用时,FANG 取得当前最优结果,在 30% 和 40% 稀疏率下,平均准确率较原方法提升 1.5%–8.5%。
功能感知神经元分组(FANG)方法框架
**35. **基于质量感知的语言条件局部自回归异常合成与检测
Quality-Aware Language-Conditioned Local Auto-Regressive Anomaly Synthesis and Detection **作者:**钱隆,朱炳科,陈盈盈,唐明,王金桥 工业异常检测普遍受制于异常样本稀缺与分布差异,现有扩散/粗修补管线在低分辨去噪、语义可控性与生成成本上存在低分辨率瓶颈/边界缝隙、语义可控性差、训练等权导致劣质合成干扰优化等问题。为此,我们提出了一套“可控合成 × 质量自适应学习”的闭环解决方案:其一,ARAS(语言条件、掩码局部的自回归编辑器)在VQ-VAE离散token空间施加Hard-Gate算子,仅重写掩码内token、冻结上下文,从而保持材质微结构与相位连续,并以自然语言精确控制缺陷的类型/形状/尺度/位置;其二,QAW(质量感知重加权)将CLIP图文一致性映射为样本级连续权重,在不丢弃数据多样性的前提下降低训练方差、抑制低质合成对优化的干扰。 在 MVTec AD、VisA、BTAD 三个基准上,QARAD在图像级/像素级AUROC均实现一致领先,数据集均值分别达到 99.7/99.8、98.9/99.8、96.7/98.0;同时,ARAS避免迭代去噪,在 1024×1024 分辨率下合成速度较扩散式管线约快 5×,且检测阶段推理时延不增加,体现出准确性与效率兼优的工程价值。 代码已开源: https://github.com/neymarql/QARAD
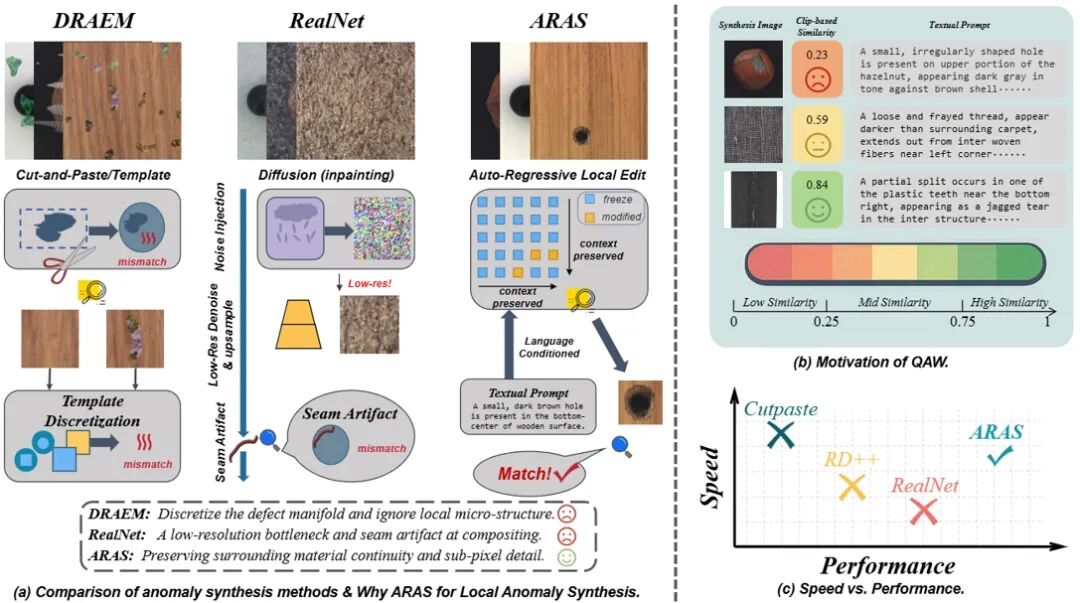
图1. ARAS与Quality-Aware Weighting 的设计动机
图2. ARAS-QARAD 端到端框架图
**36. **AnomalyMoE: 无需语言的通用异常检测通才模型
AnomalyMoE: Towards a Language-free Generalist Model for Unified Visual Anomaly Detection **作者:**古兆鹏,朱炳科,朱贵波,陈盈盈,葛卫,唐明,王金桥 异常检测是跨越众多领域和模态的一项关键任务,但现有方法通常高度特化,仅为特定领域或特定异常类型设计,难以检测其设计领域之外的异常,这极大地限制了现有异常检测方法的通用性。而现有的统一异常检测方向的尝试要么局限于局部结构缺陷,要么依赖于复杂的组件分割和大型语言模型,计算开销大且仍然无法处理组件缺失等复杂情况。为解决这些问题,本研究提出了一种名为AnomalyMoE的无需语言的通用视觉异常检测框架。该方法的核心思想是利用混合专家架构,将复杂的异常检测问题分解为三个独立的语义层级:局部结构异常、组件级语义异常和全局逻辑异常。AnomalyMoE为每个层级配备了专门的基于特征重建的专家网络,使其能够在一个统一模型内协同理解和检测多种类型的异常。此外,本研究还引入了专家信息排斥(EIR)模块以促进专家的多样性,并引入了专家选择平衡(ESB)模块以确保所有专家得到充分利用。 在涵盖工业、3D点云、医疗影像、视频监控和逻辑异常等领域的8个具有挑战性的数据集上进行的大量实验表明,AnomalyMoE的性能不仅全面超越了现有的通用模型,还显著优于各自领域中的专用方法。 代码已开源: https://github.com/FantasticGNU/AnomalyMoE
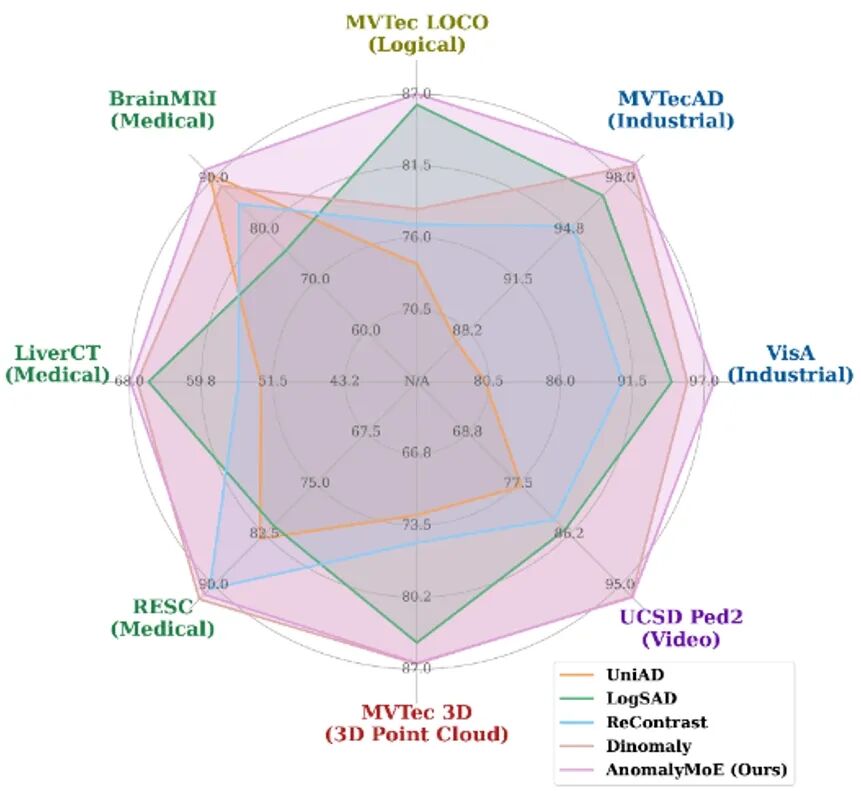
图1. AnomalyMoE 与现有异常方法在不同领域数据集上的性能对比
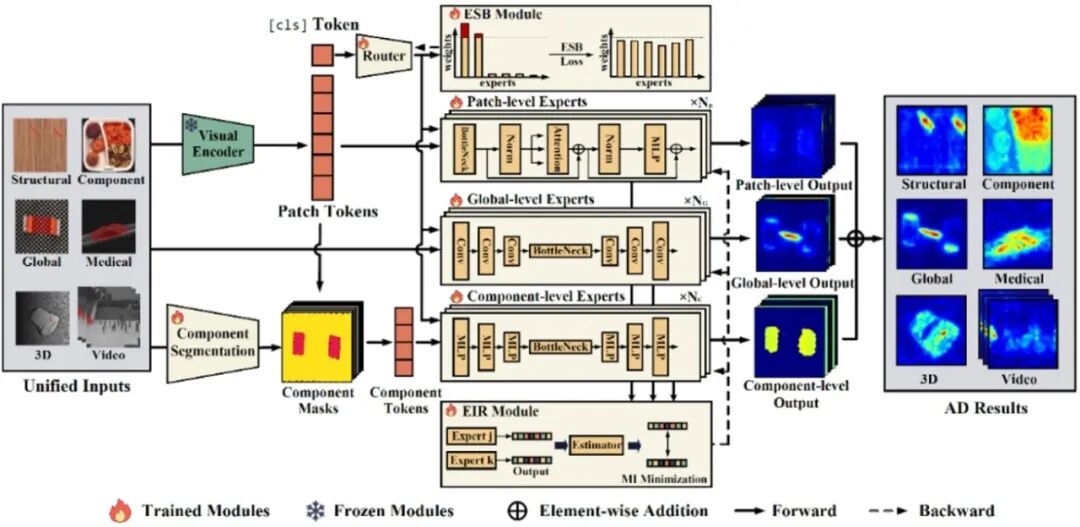
图2. AnomalyMoE 整体结构图
**37. **从大规模网络数据的人类轨迹中学习城市环境下语言引导的具身导航
UrbanNav: Learning Language-Guided Embodied Urban Navigation from Web-Scale Human Trajectories **作者:**梅阳鸿,杨易蓉,郭龙腾,汪群博,于明明,何兴建,吴文峻,刘静 在复杂城市环境中,如何让智能体仅凭自然语言指令准确导航,一直是具身智能领域的难题。现有方法多局限于仿真或非街道场景,且依赖精确目标(如坐标或图像),难以应对真实城市中嘈杂的语言、模糊的空间指代、多样地标与动态街景等挑战。 为此,研究团队提出 UrbanNav,一个大规模的的语言引导城市导航框架。该方法利用网络规模的城市步行视频,构建了一套高效的自动化导航数据标注流程,将人类真实行走轨迹与基于现实地标的自然语言指令对齐。UrbanNav 数据集涵盖超过1500小时的导航视频和300万组“指令-轨迹-地标”三元组,覆盖丰富多样的城市场景。 基于该数据集,UrbanNav 模型学会了强大的导航策略,在空间推理、抗噪能力和跨城市泛化方面表现卓越。实验表明,其性能显著优于现有方法,首次实现了在真实、开放城市环境中基于自由形式语言指令的稳健导航。这项工作表明,利用大规模网络视频数据有望为具身智能在城市环境中的实际应用提供有效支持,为未来自主机器人在复杂城市场景中实现语言引导导航提供了一种可行路径。
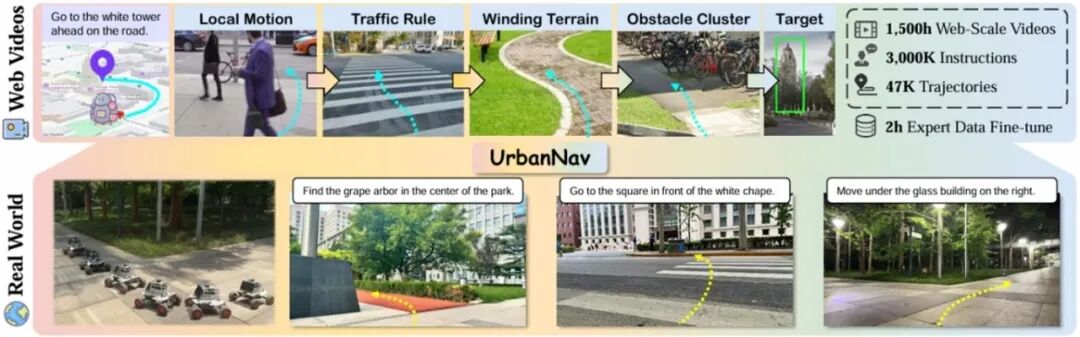
图1. UrbanNav总览。从海量网络步行视频中构建大规模语言-轨迹数据集,训练出能理解复杂自然语言指令的导航策略,仅需少量真实场景数据微调即可实现在未知城市环境中的视觉语言导航。
图2. UrbanNav数据构建流程。包括三个关键步骤:1)相机位姿估计;2)机器人兼容性过滤;3)语言指令生成。
**38. **SAQ-SAM:面向分割一切模型的语义对齐量化
SAQ-SAM: Semantically-Aligned Quantization for Segment Anything Model **作者:**张静,李志凯,胡诚智,刘学文,顾庆毅 分割一切模型(Segment Anything Model, SAM) 展现了卓越的零样本分割能力,但其高昂的计算成本使得在边缘设备上的部署面临挑战。尽管后训练量化(Post-Training Quantization,PTQ)提供了一种有前景的压缩方案,但现有方法在SAM上效果不佳,具体表现为: (i) 掩码解码器中存在极端的激活异常值。实验发现,激进的剪裁(甚至缩放100倍)不影响性能而有利于量化。然而,传统的基于分布的量化误差度量并不鼓励这种剪裁。(ii) 通用的量化重建方法忽略了SAM的语义交互性,损害了图像特征与提示意图之间的对齐。 为了解决上述问题,本文提出了SAQ-SAM,从语义对齐的角度提升SAM的PTQ性能。具体来说,提出了感知一致性剪裁,通过度量注意力焦点重叠度误差来支持语义对齐剪裁。此外,提出提示感知重建,利用掩码解码器中的交叉注意力整合图像与提示的交互,从而促进分布和语义的双重对齐。 实验涵盖了不同规模的 SAM 模型及多种任务(包括实例分割、定向目标检测和语义分割),结果表明SAQ-SAM具有显著优势。
图1.掩码解码器中极端激活分布的可视化及不同剪裁方法的性能对比。掩码解码器中的 QK 激活值呈现出高度偏斜的分布,大部分数据集中在一个狭窄的范围内,而异常值可能超出正常范围的180倍。MSE 提供了一个过于宽泛的剪裁范围,而本文提出的感知一致性剪裁(PCC)方法能够更精确地识别异常值。
图2. SAQ-SAM框架。感知一致性剪裁(Perceptual-Consistency Clipping,PCC) 通过最小化注意力焦点相对于全精度模型的偏差,指导 QK 激活值的量化剪裁,从而在语义上保留感知对齐性。提示感知重建(Prompt-Aware Reconstruction,PAR)利用掩码解码器中的现成模块,将图像与提示的交互融入到逐Stage重建中。通过在全精度模型的监督下最小化交互响应误差,量化模型学习到视觉特征与提示意图之间的对应关系,从而在分布和语义层面实现双重对齐。
**39. **重新审视基于多模态大语言模型的图像质量评估:错误与改进
Revisiting MLLM Based Image Quality Assessment: Errors and Remedy **作者:**唐榛辰、杨嵩林、彭勃、王梓川、董晶 多模态大语言模型(MLLM)的迅速发展极大地推动了图像质量评估(IQA)任务的进步。然而,一个关键挑战在于:MLLM 的离散 token 输出与 IQA 任务所需的连续质量分数之间存在内在的不匹配。这种差异显著限制了基于 MLLM 的 IQA 方法的性能。以往将离散 token 预测结果转换为连续分数的做法常常会引入转换误差。此外,由于等级类 token(如 “good”)所带来的语义混淆,MLLM 在 IQA 任务中的表现进一步受限,其在相关任务中的原生能力也因此受到削弱。 为解决上述问题,本研究首先对以往方法中固有的误差进行了理论分析,并基于此提出了一个简单而高效的框架——Q-Scorer。该框架在 MLLM 流程中引入了轻量级回归模块与专为 IQA 设计的评分 token。大量实验证明,Q-Scorer 在多个 IQA 基准上均取得了最新的性能表现,能够良好地泛化到混合数据集上,并且在与其他方法结合时能进一步提升效果。
图1. 基于MLLM的IQA方法概览与误差分析。该图展示了MLLM在标签转换与分数预测中的适配过程,并重点标出了导致转换误差与语义混淆的关键步骤。
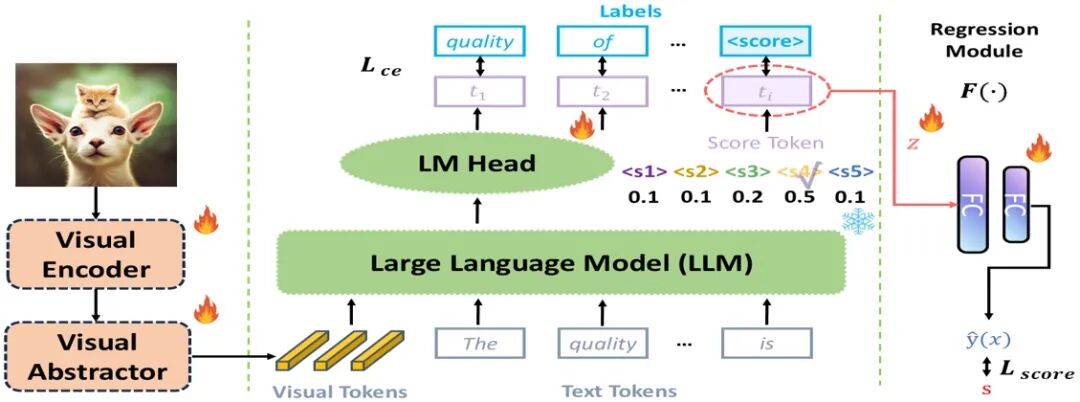
图2. Q-Scorer概览。该方法通过损失函数Lce学习输出特定区间的评分token。随后,将该评分token的嵌入向量输入至一个MLP中,以回归得到连续的质量分数,并利用Lscore进行优化,从而保证与主观意见分数(MOS)的一致性与无损性。
**40. **CoGrad3D:一种基于正交梯度融合与空间耦合时间步优化的 3D 生成方法
CoGrad3D: Spatially-Coupled Timestep Optimization with Orthogonal Gradient Fusion for 3D Generation **作者:**童昊阳,王宏博,刘进,王琦,曹杰,赫然 分数蒸馏采样推动了文本到3D生成的进展,但现有方法常难以生成细节丰富且多视图一致的3D资产。这些局限性源于对精细细节的引导不均、对单视图优化的过度依赖,以及扩散时间步和相机选择的过度随机性等问题,导致纹理模糊和视图不一致,降低了真实感。为了应对这些挑战,我们提出了 CoGrad3D,这是一个统一的生成式精炼框架,它采用了一种持续自适应的优化策略。 CoGrad3D 通过根据实时收敛信号动态调整优化焦点,确保了在几何完整性和高保真细节两方面都能取得均衡进展。具体而言,本研究提出了一种自适应区域采样策略,该策略重点关注欠收敛的视图区域,从而促进稳定和均匀的优化。为了促进从粗糙几何到精细重建的过渡,研究团队开发了一种区域感知的时间调度方案,该方案将全局训练动态与局部收敛反馈相结合。此外,本研究引入了一种梯度融合机制,该机制整合了来自相邻视角的历史梯度,从而减轻了特定视图的伪影,并促进了连贯3D结构的生成。
CoGrad3D的流程框架
**41. **UniAlignment:基于语义对齐的统一图像生成、理解、编辑和感知
UniAlignment: Semantic Alignment for Unified Image Generation, Understanding, Manipulation and Perception **作者:**宋昕洋,王立彬,王卫宁,柳绍桢,郑丹丹,陈景东,李琦,孙哲南 扩散模型在文本生成图像任务上的显著成功,激发了将其能力扩展至多模态任务(包括图像理解、编辑和感知等)的广泛兴趣。这类任务要求模型具备跨视觉与文本模态的高级语义理解能力,尤其是在涉及复杂语义指令的场景中。然而,现有方法往往高度依赖视觉-语言模型(VLMs)或模块化设计进行语义引导,导致架构碎片化和计算效率低下。 为应对这些挑战,本研究提出了UniAlignment——一种基于单一扩散Transformer的统一多模态生成框架。UniAlignment采用双流扩散训练策略,融合了模态内及跨模态的语义对齐,有效提升了模型的跨模态一致性和指令遵循的鲁棒性。此外,研究还提出了SemGen-Bench,这是一项专为评估复杂文本指令下多模态语义一致性而设计的新基准。大规模多任务和多基准测试结果表明,UniAlignment显著优于现有方法,彰显了扩散模型在统一多模态生成领域的巨大潜力。
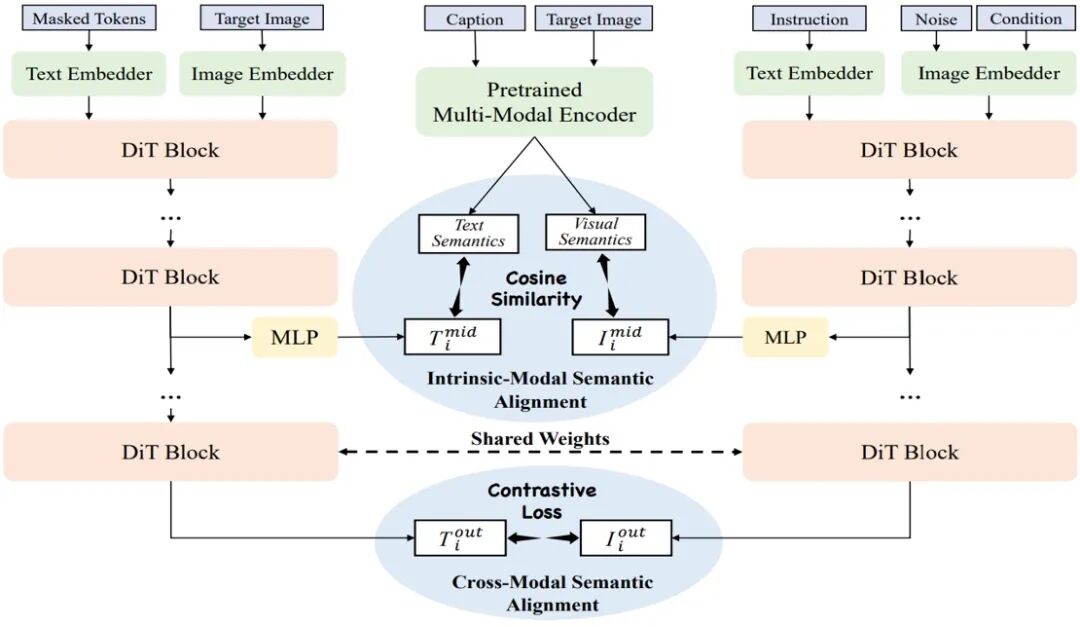
UniAlignment模型框架
**42. **稀疏调优提升预训练模型的持续学习可塑性
Sparse Tuning Enhances Plasticity in PTM-based Continual Learning **作者:**张桓,樊胜华,董姝妤,郑昱津,汪鼎文,吕凡 在预训练模型上进行持续学习为跨任务的高效适应提供了巨大潜力。然而,现有的大多数方法往往冻结预训练模型参数,并依赖于提示或适配器等辅助模块,从而限制了模型的可塑性。当面对显著的分布变化时,这种策略会导致泛化能力不足。尽管完全微调可以提高适应性,但它同时也可能破坏的预训练知识。 本文提出了一种互信息引导的稀疏微调方法,该方法是一种即插即用的策略,通过互信息目标的敏感性选择性地更新少量PTM参数(少于5%)。MIST能够在保持泛化能力的同时实现有效的任务特定适应。为进一步减少任务间干扰,在微调过程中引入了强稀疏正则化机制,通过随机丢弃梯度,使每步更新的参数比例低于0.5%。在标准冻结式方法之前应用MIST,可以持续提升多种持续学习基线的性能。实验结果表明,将MIST集成到多种基线方法中均能显著提高性能。
MIST方法思想
**43. **TRACE: 变化感知驱动的图结构优化反应条件预测
TRACE: Transformation-Aware Graph Refinement for Reaction Condition Prediction **作者:**陈雨洁,马腾飞,刘元盛,魏乐义,吴书,曹东升,刘益萍,曾湘祥 化学反应条件的精准预测(如催化剂、溶剂、试剂),是实现智能合成的关键。现有方法通常将反应物与产物独立编码,难以捕捉与条件相关的化学结构变化。 为此,本研究提出变化感知的TRACE框架。该框架从原子层面联合建模反应物与产物,然后通过构建动态交互图来直接服务条件预测。其核心包含两大模块:结构感知编码器用于整合原子局部环境信息;动态交互优化模块则自适应推断关键分子间作用,并利用反应中心正则化聚焦化学活性区域。实验表明,TRACE在基准数据集上达到领先水平,尤其在溶剂与试剂预测中优势明显,并在时间迁移、少样本及真实合成场景中展现出卓越的泛化能力与稳健性,为其实际应用奠定了坚实基础。
TRACE框架图
欢迎后台留言、推荐您感兴趣的话题、内容或资讯! 如需转载或投稿,请后台私信。

