摘要—基础模型(FM)驱动的代理服务被视为一种有前景的解决方案,用于开发智能化和个性化的应用,推动人工通用智能(AGI)的发展。为了在部署这些代理服务时实现高可靠性和可扩展性,必须协同优化计算和通信资源,从而确保有效的资源分配和无缝的服务交付。为实现这一愿景,本文提出了一个统一框架,旨在提供一个全面的综述,探讨在异构设备上部署基于FM的代理服务,重点是模型和资源优化的集成,以建立一个强大的基础设施支持这些服务。特别地,本文首先探索了推理过程中的各种低层次优化策略,并研究了增强系统可扩展性的方法,如并行化技术和资源扩展方法。接着,本文讨论了几种重要的基础模型,并调查了专注于推理加速的研究进展,包括模型压缩和标记减少等技术。此外,本文还研究了构建代理服务的关键组件,并突出了值得关注的智能应用。最后,本文提出了开发具有高服务质量(QoS)实时代理服务的潜在研究方向。 关键词—基础模型、AI代理、云/边缘计算、服务系统、分布式系统、AGI。
I. 引言
人工智能(AI)的快速发展使得基础模型(FM)成为创新的基石,推动了自然语言处理、计算机视觉和自主系统等多个领域的进步。这些模型的特点是参数空间庞大,并在广泛的数据集上进行了深度训练,孕育了从自动化文本生成到高级多模态问答和自主机器人服务等众多应用[1]。一些流行的基础模型,如GPT、Llama、ViT和CLIP,推动了AI能力的边界,提供了处理和分析大量数据的复杂解决方案,涵盖了不同格式和模态。基础模型的持续进展显著增强了AI在理解和与世界互动方面的能力,使其在某种程度上类似于人类认知。 然而,传统的基础模型通常仅限于提供问答服务,并根据已有知识生成回答,往往无法整合最新信息或利用先进工具。基础模型驱动的代理服务旨在增强基础模型的能力。这些代理具备动态记忆管理、长期任务规划、高级计算工具以及与外部环境的交互功能[2]。例如,基础模型驱动的代理能够调用不同的外部API以访问实时数据,执行复杂的计算,并根据最新的可用信息生成更新的响应。这种方法提高了响应的可靠性和准确性,并使与用户的互动更加个性化。 开发具有低延迟、高可靠性、高弹性并且资源消耗最小的服务系统,对于向用户提供高质量的代理服务至关重要。这样的系统能够有效地管理不同的查询负载,同时保持快速响应并减少资源成本。此外,在异构的边缘-云设备上构建服务系统,是利用边缘设备的闲置计算资源和云端丰富计算集群的一种有前景的解决方案。边缘-云设备的协同推理能够通过根据计算负载和实时网络条件动态分配任务,提升整体系统效率。 尽管许多研究已经探讨了小型模型在边缘-云环境中的协同推理,但在这种范式下部署基础模型以支持多样化的代理服务仍然面临着一些严重挑战。首先,波动的查询负载极大地挑战了模型服务。随着越来越多的用户希望体验基础模型驱动的智能代理服务,查询负载急剧增加。例如,截至2024年4月,ChatGPT的用户约为1.805亿,其中每周活跃用户约为1亿[3]。这些用户在不同时间访问服务,导致请求速率变化。因此,弹性服务系统应根据当前的系统特性动态调整系统容量。其次,基础模型的参数空间极为庞大,达到数百亿规模,这对存储系统提出了巨大挑战。然而,边缘设备和消费级GPU的存储容量有限,无法容纳整个模型。庞大的参数量导致了显著的推理开销和较长的执行延迟。因此,有必要设计模型压缩方法,并在不同的执行环境中采用不同的并行化方法。此外,用户在不同应用中有不同的服务需求和输入。例如,有些应用优先考虑低延迟,而有些则优先考虑高精度。这要求动态资源分配并调整推理过程。此外,AI代理需要在复杂环境中处理大量艰巨任务,这要求有效管理大规模内存、实时处理更新的规则和特定领域知识。此外,代理具有不同的个性和角色,因此需要设计高效的多代理协作框架。
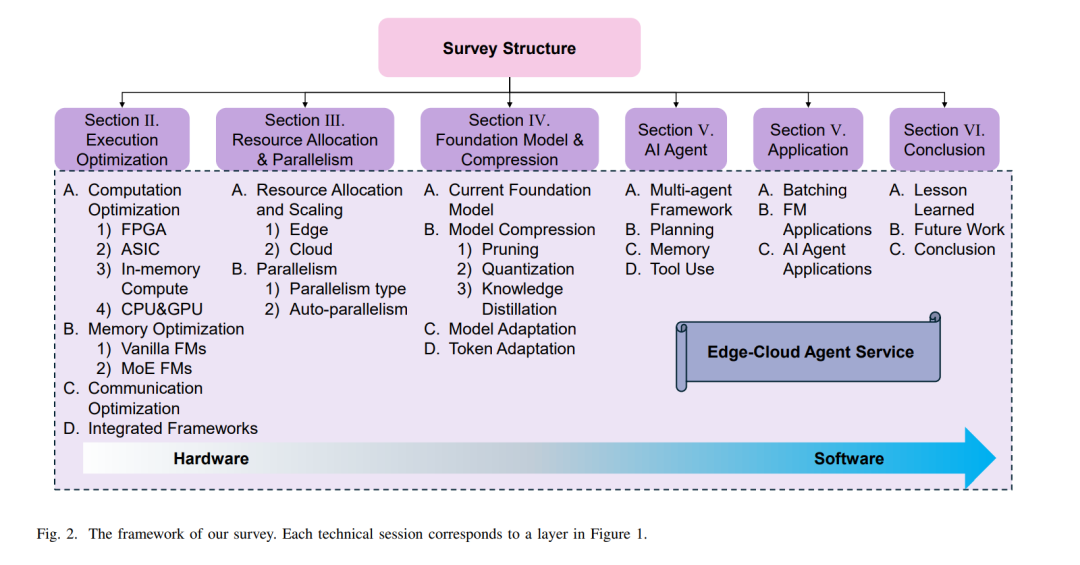
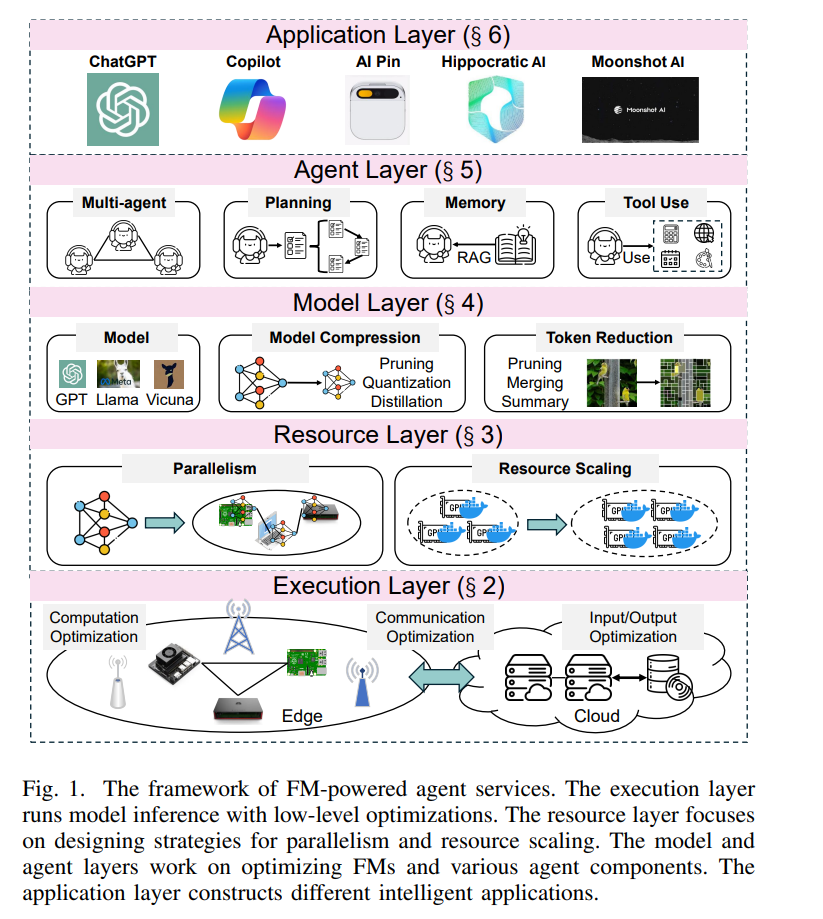
为了解决上述挑战,并推动实时基础模型驱动的代理服务的发展,本文提出了一个统一框架,并从不同优化角度调查了多项研究成果。该框架如图1所示。底层是执行层,边缘或云设备在此执行基础模型推理。联合计算优化、输入/输出优化和通信优化被应用于加速推理,并促进构建强大的基础模型基础设施。资源层由两个组件组成,帮助在不同设备上部署模型。并行化方法设计了不同的模型拆分和放置策略,以利用可用资源并协同提高吞吐量。资源扩展根据查询负载和资源利用情况动态调整硬件资源,从而提高整体可扩展性。模型层专注于优化基础模型,提出了两种轻量级方法,包括模型压缩和标记减少,旨在推动基础模型的广泛应用。基于这些基础模型,构建了许多AI代理来完成各种任务。为了增强代理的四个关键组件,提出了许多方法,包括多代理框架、规划能力、记忆存储和工具利用。最终,利用上述技术,可以开发各种应用,为用户提供智能化和低延迟的代理服务。
A. 相关工作
许多研究集中于优化在边缘-云环境中部署机器学习模型的系统。KACHRIS回顾了一些用于大规模语言模型(LLMs)计算加速的硬件加速器,以解决计算挑战[4]。Tang等人总结了旨在优化网络和计算资源的调度方法[5]。Miao等人提出了一些加速方法以提高大规模语言模型的效率[6]。这项综述涵盖了系统优化,如内存管理和内核优化,以及算法优化,如架构设计和压缩算法,以加速模型推理。Xu等人关注人工智能生成内容(AIGC)的部署,并概述了AIGC的移动网络优化,涵盖了数据集收集、AIGC预训练、AIGC微调和AIGC推理过程[7]。Djigal等人研究了机器学习和深度学习技术在多接入边缘计算(MEC)系统中资源分配的应用[8]。该综述包括了资源卸载、资源调度和协同分配。许多研究提出了不同的算法来优化基础模型和代理的设计。[1]、[9]和[10]提出了流行的基础模型,特别是大规模语言模型。[11]、[12]和[13]总结了大规模语言模型的模型压缩和推理加速方法。[2]、[14]和[15]回顾了代理开发中的挑战和进展。 总之,上述研究要么优化了边缘-云资源分配和调度以支持小型模型,要么为大规模基础模型设计了加速或效率方法。据我们所知,本文是首篇全面综述和讨论实时基础模型驱动的代理服务在异构设备上部署的研究,近年来这一研究方向已经变得尤为重要。我们设计了一个统一框架,填补了这一研究空白,并从不同视角回顾当前的研究成果。该框架不仅勾画了基础模型部署的关键技术,还识别了基础模型驱动的代理服务的关键组件和相应的系统优化方法。
B. 贡献
本文全面综述了在边缘-云环境中部署基础模型驱动的代理服务,涵盖了从硬件到软件层的优化方法。为方便读者,本文提供了综述的大纲(见图2)。本文的贡献总结如下:
- 本综述提出了第一个全面的框架,旨在深度理解在边缘-云环境中部署基础模型驱动的代理服务。该框架具有促进人工通用智能(AGI)发展的巨大潜力。
- 从低层次硬件角度出发,本文展示了各种运行时优化方法和资源分配与调度方法,这些技术旨在为基础模型构建可靠且灵活的基础设施。
- 从高层次软件角度出发,本文阐述了专注于模型优化和代理优化的研究工作,提供了构建智能化和轻量化代理应用的多种机会。
本文其余部分安排如下:第二节介绍了一些低层次的执行优化方法;第三节描述了资源分配和并行机制;第四节讨论了当前的基础模型及模型压缩和标记减少技术;第五节阐明了代理的关键组件;第六节介绍了批处理方法及相关应用;最后,第七节讨论了未来的研究方向并作结论总结。