

检测人工智能生成的文本(AIGT)主要有三种方法:水印、统计和文体分析以及使用预训练的语言模型(LM)。检测水印需要了解水印提取算法;除此之外,不需要额外的数据。不过,其他两种广泛的检测方法需要数据集,以便学习将 AIGT 与人类撰写的文本区分开来的模式--最好是由我们希望检测的人工智能模型生成的数据集,而且数据集的设置要尽可能接近我们在现实世界中遇到这些文本的方式。以往的研究表明,最有效的检测器是在与测试数据相同的领域(新闻文章、社交媒体帖子、学术论文等)、语言(英语、中文、法语等)和模型设置(解码算法、提示、输出长度等)的数据上训练出来的。同时,研究还表明,为了获得最大的通用性和鲁棒性,必须在各种数据上训练检测器,使其不局限于(或者用机器学习的术语来说,是overft)一个非常狭窄的数据样本范围。因此,对于任何给定的应用,选择适当的数据来训练检测器以及测试检测器的准确性都是非常重要的。
在本报告中,列举了在进行文献综述时遇到的数据集。将提供每个数据集的详细摘要,解释其创建过程和访问方法。不过,在此首先介绍一些可用数据集的简要统计数据。从图 1.1 中可以看出,绝大多数可用的数据集都是英文版的,还有相当大的一部分是多语种的(包括英语和其他语言)。在自然语言处理(NLP)领域有一个众所周知的偏见,即大部分研究都集中在英语上,而忽略了其他语言。
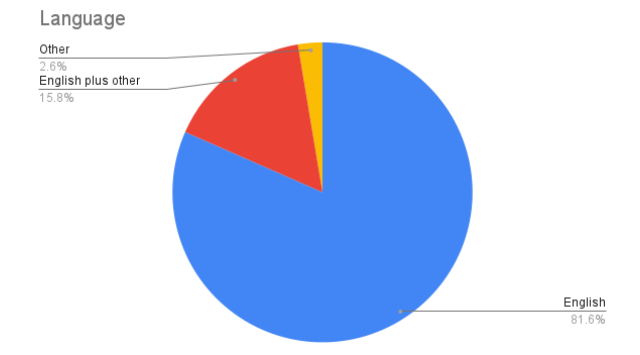
图 1.1: 英语与其他语言数据集的比例。
毫无疑问,用于生成这些数据集的许多大型语言模型(LLMs)至少在一开始只有英语版本,这加剧了这种偏差。不过,随着越来越多的多语种 LLM 可用,我们预计情况会继续发生变化。
图 1.2 显示了除英语以外的其他语言在数据集中所占的比例。中文在其中所占比例最大,其次是阿拉伯语。在本报告总结的数据集中,许多其他语言只出现在其中的一个或两个数据集中。
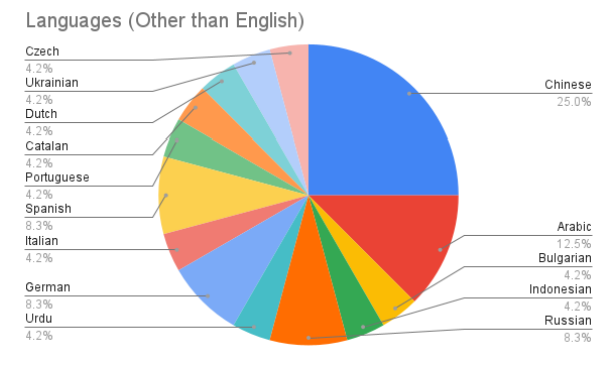
图 1.2:非英语数据集的语言比例。
如上所述,另一个重要因素是数据集的领域。图 1.3 显示了数据集中的不同领域。错误信息是最常见的,这无疑是由于我们将重点放在了错误信息这一感兴趣的领域。我们还注意到,在这个大类别中,还有多个子类别(如假新闻、社交媒体错误信息等)。相当大比例的数据集也包含多个域(因此也包含子域)。除了这些类别外,我们还观察到新闻、学术写作和论文等领域的受欢迎程度。社交媒体虽然从实用的角度来看非常有趣,但却没有得到很好的体现,这可能是由于在短文中检测 AIGT 的困难,或者在创建数据集时模拟真实的社交媒体帖子的困难。
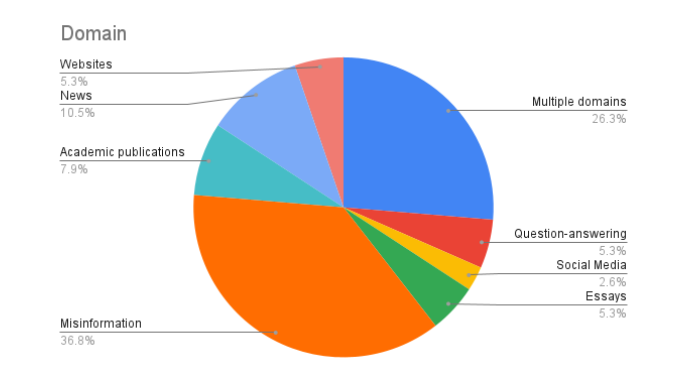
图 1.3:不同文本领域数据集的比例。
在图 1.4 中,探讨了数据集规模的分布情况,数据集规模分为四个等级,从小型(少于 50,000 个样本)到超大型(超过 500,000 个样本)。这只是一个粗略的描述,因为我们是通过将人类生成的示例和人工智能生成的示例结合起来计算总规模的,而某些数据集可能会偏重于其中的一个或另一个。此外,有些数据集包含来自单一模型或语言的大量样本,而有些数据集则包含来自大量不同模型的少量样本。不过,我们看到一个总体趋势,即由少于 50,000 个样本组成的数据集,同时也有相当大比例的 “大型 ”数据集(样本数在 100,000 到 500,000 之间)。虽然有些检测方法声称自己是零样本或少样本方法,需要较少的数据样本来校准算法,但一般认为尽可能多的数据是有益的。
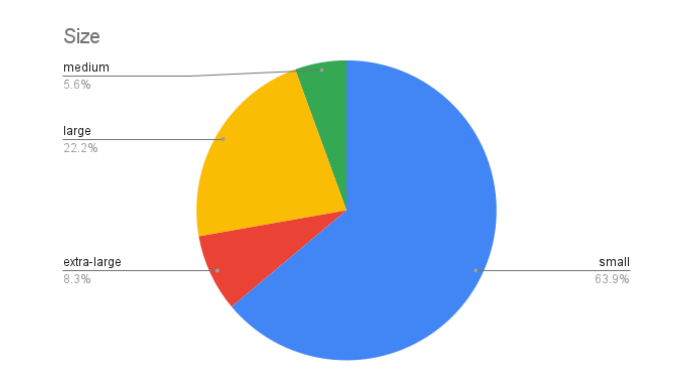
图 1.4 不同规模数据集的比例 不同规模数据集的比例,其中 “小 ”表示少于 50,000 个样本,“中 ”表示介于 50,000 至 100,000 个样本之间,“大 ”表示介于 100,000 至 500,000 个样本之间,“特大 ”表示超过 500,000 个样本。.
值得注意的是,除了极少数例外,所有这些数据集都是为研究目的而生成的,而不是从网上收集的。这样做的原因不言自明:如果我们一开始就没有一个准确的 AIGT 检测器,我们就无法确定互联网上的任何特定文本是由人类还是由人工智能撰写的。通过自己生成 AIGT,研究人员可以保证它确实是 AIGT,而且通过将人类数据样本限制在 2020 年之前的文本,他们可以合理地确信这些文本确实是由人类撰写的。一个值得注意的例外是 TweepFake 数据集(见第 2.5.2 节),该数据集的 AIGT 部分包含了从 Twitter 上已知机器人账户中抓取的数据。其他工作也尝试通过自动技术识别被伪装成僵尸的账户,从而从社交媒体中收集数据(Cui 等,2023 年),但我们在此不包括该工作,因为其方法似乎是相当循环的(通过依赖算法来检测僵尸账户,随后在数据上训练的任何系统的实用性都会与初始算法一样,出现假阳性和假阴性错误)。
相反,大多数数据集都是先定义一个人类生成文本的 “parent”或 “anchor”数据集,然后再人工生成平行的 AIGT 文本。例如,在新闻领域,研究人员可以从新闻故事语料库开始。然后,他们将标题(或标题加首句)输入 LLM,并要求 LLM 撰写文章的其余部分。这样,他们就能为同一组标题生成一个由人类和人工智能撰写文章的并行数据集。同样,在问题解答领域,如果研究人员有一个由人类撰写答案的问题数据集,他们就可以要求人工智能回答同样的问题。正如数据集摘要中详细介绍的那样,有些生成方法包括更具体的风格提示,以模仿人类数据集,如 “以《纽约时报》的风格写一篇新闻文章”,还有一些数据集包括人工智能对人类文本的转述以及人类-人工智能协作文本。所有这些生成文本的方法都允许对检测 AIGT 进行精确、受控的研究实验;但是,目前还不清楚这些方法在多大程度上代表了互联网上实际存在的人工生成文本。
另一个需要考虑的相关因素是,检测器不仅要从训练数据中学习 AIGT 模型,还要学习人类写作的模型。因此,举例来说,如果训练数据只包括来自专业记者的样本(许多新闻数据集就是这种情况),我们就不能指望检测器能准确识别普通非专业人士撰写的文本。人类生成的样本缺乏多样性很可能是造成偏差的原因,例如 AIGT 检测器会将英语学习者的文章误判为 AIGT。因此,训练数据最好能代表来自人工智能和人类的各种文本。
本报告中的大多数数据集要么是公开的,要么是用于研究目的的。

