随着大规模语言模型(LLM)技术的快速发展以及生物信息学特定语言模型(BioLMs)的出现,对当前领域的综合分析、计算特性和多样化应用的需求日益增加。本综述旨在通过对BioLMs进行全面回顾来满足这一需求,重点介绍其演变、分类及其独特特征,同时详细考察训练方法、数据集和评估框架。我们探讨了BioLMs在疾病诊断、药物发现和疫苗开发等关键领域的广泛应用,突出了它们在生物信息学中的影响力和变革潜力。我们识别了BioLMs中固有的关键挑战和局限性,包括数据隐私和安全问题、可解释性问题、训练数据和模型输出中的偏差以及领域适应的复杂性。最后,我们强调了新兴趋势和未来发展方向,提供了有价值的见解,以指导研究人员和临床医生推动BioLMs在日益复杂的生物学和临床应用中的进步。
1. 引言
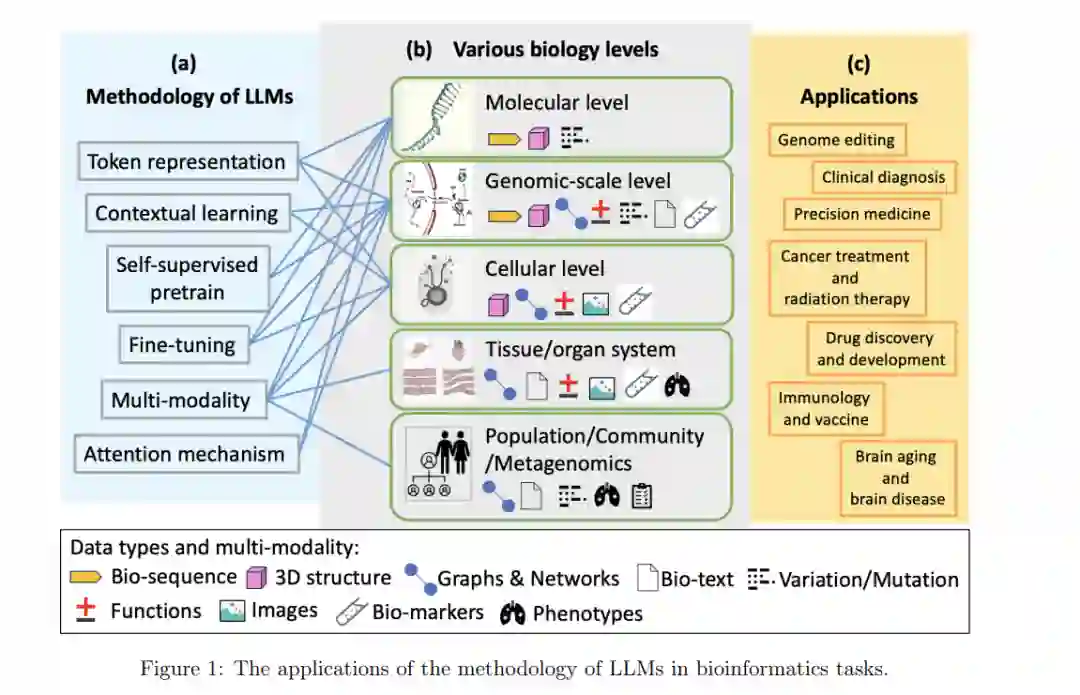
大规模语言模型(LLM)的快速发展,如BERT [1]、GPT [2]及其专门化的对应物,已经彻底改变了自然语言处理(NLP)领域。它们能够建模上下文、解读复杂数据模式,并生成类人反应,这使得它们自然地延伸到生物信息学领域,在这个领域中,生物序列往往与人类语言的结构和复杂性相似 [3]。LLM已成功应用于多个生物信息学领域,包括基因组学、蛋白质组学和药物发现,提供了以前通过传统计算方法无法获得的见解 [4]。 尽管取得了显著进展,但在系统地分类和全面评估这些模型在生物信息学问题上的应用方面仍然存在挑战。考虑到生物信息学数据的多样性以及生命活动的复杂性,导航这一领域常常充满挑战,因为现有研究通常集中在有限的应用范围内。这导致了对LLM在多个生物信息学子领域中更广泛应用的理解存在空白 [5]。 本综述旨在通过提供LLM在生物信息学中的应用的全面概述,来解决这些挑战。文章通过关注不同层次的生命活动,从两个主要视角收集并展示相关工作:生命科学和生物医学应用。我们与领域专家合作,编写了跨越这些视角中的关键领域的深入分析,如核体分析、蛋白质结构与功能预测、基因组学、药物发现和疾病建模,包括脑部疾病、癌症以及疫苗开发中的应用。 此外,我们提出了“生命活性因子”(Life Active Factors,LAFs)这一新术语,用以描述作为生命科学研究目标候选分子和细胞成分的因素,这不仅包括具体实体(DNA、RNA、蛋白质、基因、药物),还包括抽象组件(生物通路、调节因子、基因网络、蛋白质相互作用)以及生物学测量(表型、疾病生物标志物)。LAFs是一个全面的术语,能够调和各个生物信息学子领域研究中产生的概念差异,有助于对LAFs及其在复杂生物系统中相互作用的多模态数据的理解。LAFs的引入与基础模型的精神高度契合,强调了在尊重每个LAF作为生物网络节点的相互关系的同时,统一了LAFs的序列、结构和功能。 通过弥合现有的知识空白,本工作旨在为生物信息学家、生物学家、临床医生和计算研究人员提供如何有效利用LLM来解决生物信息学中迫切问题的理解。我们的综述不仅突出了近期的进展,还识别了开放性挑战和机遇,为未来跨学科合作和创新奠定基础(图1)。