

从被动式 LLM 向自主式 LLM-智能体的快速跃迁,标志着网络安全领域的新范式。尽管这些智能体既可作为进攻与防御行动的强大工具,但正是这种智能体语境引入了一类新的内生安全风险。本文提出首个关于智能体安全版图的全景式综述,并围绕三个相互依存的支柱——应用、威胁与防御——对该领域加以结构化梳理。我们对 150 余篇论文给出全面的分类体系,解释智能体如何被使用、其所具有的脆弱性,以及为保护它们而设计的防御措施。通过细致的跨维度分析,我们既展示了智能体架构的新兴趋势,也揭示了在模型与模态覆盖方面的关键研究空白。
1 引言
自大型语言模型(LLMs)问世以来,它们已被应用于网络安全领域(Xu 等,2025a;Wang 等,2024;Deng 等,2024a)。研究范式正从被动式 LLM 转向自主式 LLM-智能体(Yao 等,2023;Shinn 等,2023;Schick 等,2023),这使模型的能力显著增强:它们不仅能描述解决方案,还能执行该方案。 定义:LLM 智能体
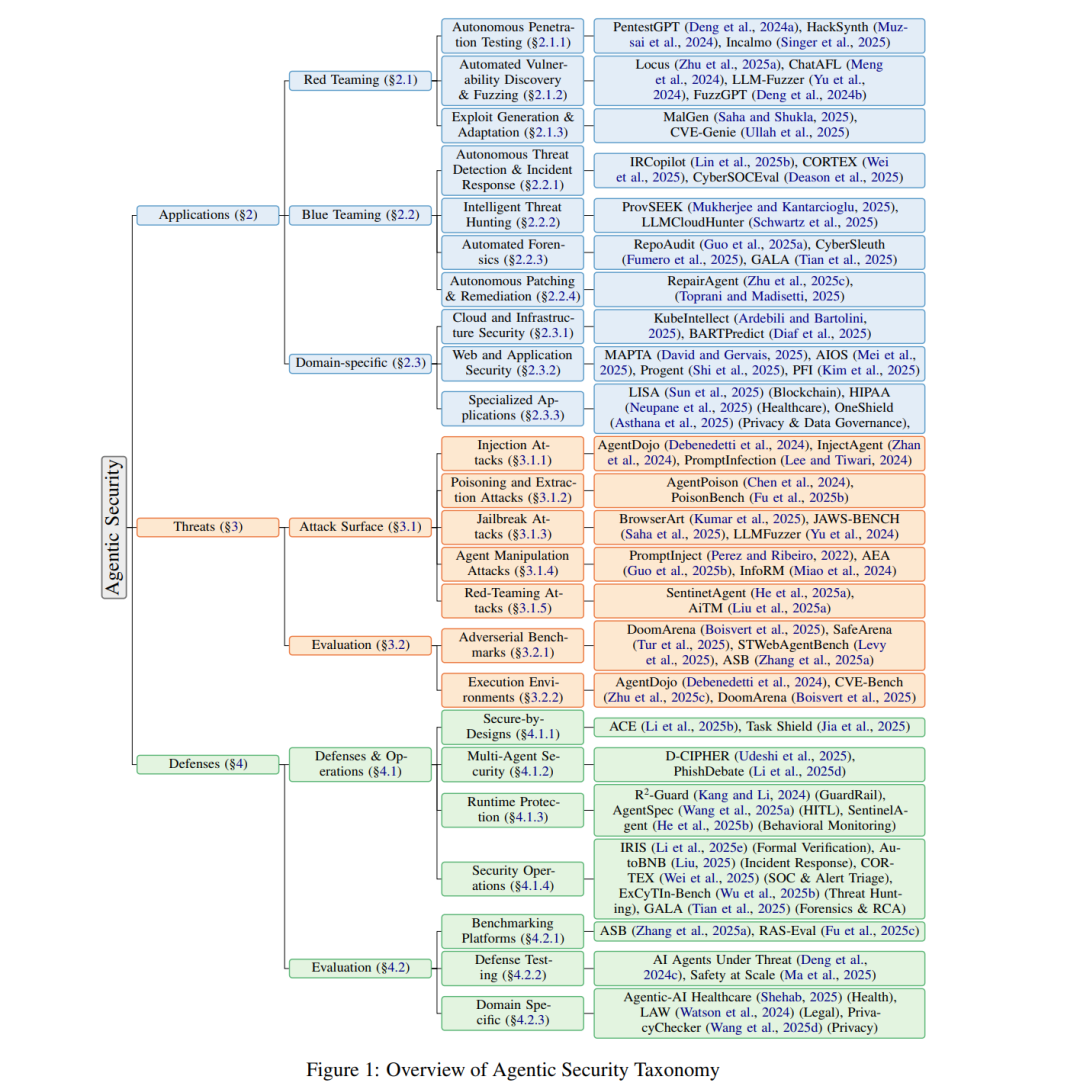
我们将 LLM 智能体定义为:其核心决策模块为 LLM,能够进行规划,调用工具/API,并在外部环境中采取行动;同时观察反馈并据此调整后续动作。它维护状态(短/长时记忆或知识库),并可能包含显式的自我反思/自验证与治理层,以满足任务目标与安全约束。 这种新获得的“能动性”使 LLM-智能体在安全谱系上展现出惊人的能力(Shen 等,2025;Zhu 等,2025b;Lin 等,2025b)。然而,多项研究表明,仅仅将 LLM 包装进智能体框架这一行为,就会显著增加其脆弱性(Saha 等,2025;Kumar 等,2025;Chiang 等,2025)。对此,越来越多的研究着手提出对策以加固这些系统(Debenedetti 等,2025;Udeshi 等,2025)。 智能体安全研究的快速发展——仅 2024–2025 年间就有 150 余篇论文——造成了缺乏系统综合的碎片化格局。现有综述虽分别在安全威胁(Deng 等,2024c)、可信性(Yu 等,2025)、企业治理(Raza 等,2025)与核心 LLM 安全(Ma 等,2025)等具体方面提供了有价值的洞见,但如表 1 所示,它们未能呈现全景图。这种碎片化使实践者与研究者缺乏一个统一框架来理解智能体的能力、脆弱性与防御之间如何相互关联。 在本文中,我们提出首个关于智能体安全版图的全景式综述,并围绕安全研究者最关心的三个问题加以结构化:**“智能体能为我的安全做什么?”(应用),“它们会如何被攻击?”(威胁),以及“我如何阻止它们?”(防御)。**为此,我们定义了三大分类支柱: * 应用(§2):在下游网络安全任务中使用 LLM-智能体,包括红队(自主式漏洞发现)、蓝队(威胁防御)与特定领域安全(云、Web 等)。 * 威胁(§3):智能体系统所固有、可被攻击者利用的安全脆弱性。 * 防御(§4):用于抵御上述威胁、加固智能体系统的技术与对策。
通过独特地贯通这三大支柱,我们的综述给出了当前技术全貌,将分散的研究工作整合为可执行的知识体系。本文的贡献包括三点: * 全景式回顾:基于三支柱分类,对智能体安全进行深入综述,如图 1 所示。 * 聚焦应用:详尽梳理安全团队实际如何使用智能体——覆盖进攻、 防御与特定领域任务,这是既往综述较少触及的方面。 * 跨维度分析:对 150 余篇论文进行分析以识别关键趋势与重要缺口——例如:从单体到规划-执行器与多智能体架构的迁移;研究几乎集中于单一商业 LLM(GPT);威胁与模态覆盖不均(RAG 污染防御不足、图像相关工作稀少);以及基准碎片化等。