成为VIP会员查看完整内容
VIP会员码认证
首页
主题
会员
服务
注册
·
登录
Dropout
关注
14
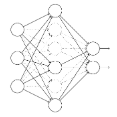
Dropout就是指在深度学习网络的训练过程中,对于神经网络单元,按照一定的概率将其暂时从网络中丢弃。Dropout可以减轻过拟合问题。
综合
百科
VIP
热门
动态
论文
精华
精品内容
【CVPR2022】 Dropout在图像超分任务中的重煥新生
专知会员服务
19+阅读 · 2022年3月5日
【斯坦福大学】Dropout的隐性和显性正则化效应,Regularization Effects
专知会员服务
34+阅读 · 2020年3月4日
花书《深度学习》笔记,深度学习规则,帮你抓住精髓!(附下载)
专知会员服务
62+阅读 · 2019年12月25日
参考链接
提示
微信扫码
咨询专知VIP会员与技术项目合作
(加微信请备注: "专知")
微信扫码咨询专知VIP会员
Top